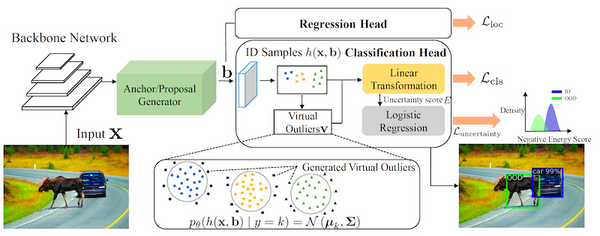
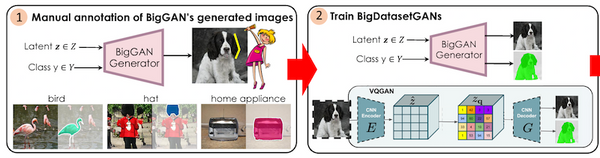
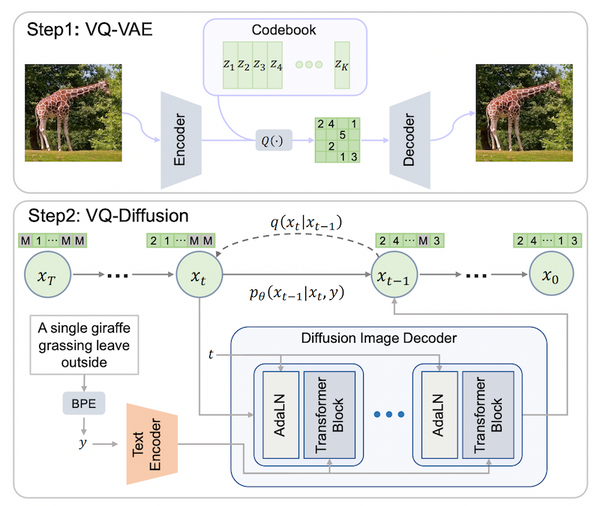
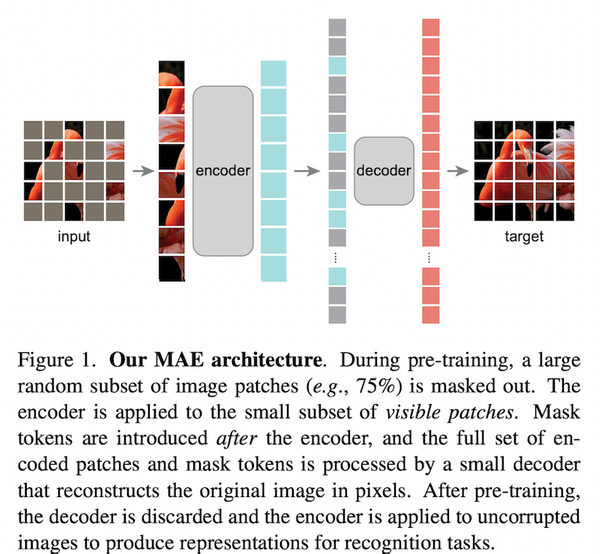
最近大きな話題になっている ChatGPT。専門的なタスクであっても高品質な回答を出力できますが、その「回答」は定量的にどの程度正しいのでしょうか。また、大学のエッセイやレポートなどの「代筆」やフェイクニュースの自動生成などの社会問題にもなっていますが、ChatGPT の出力した文章を自動で判別することはできるのでしょうか。この記事では、最近話題を呼んでいる ChatGPT の性能を調査した論文 4 本と、ChatGPT の出力した文章の自動検出手法に関する論文 3 本、合計 7 本解説します。