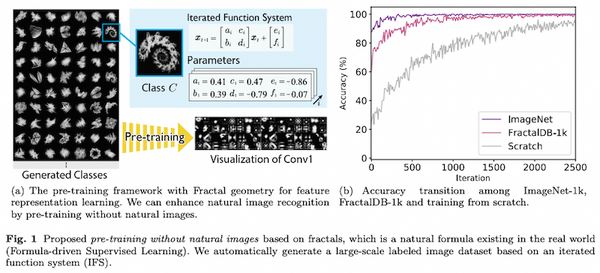
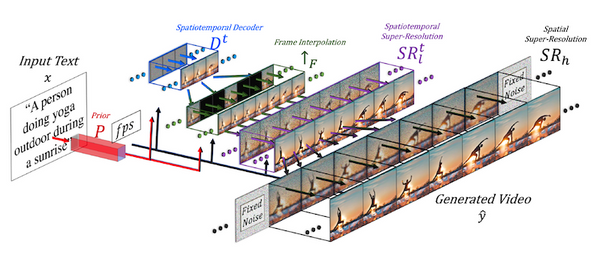
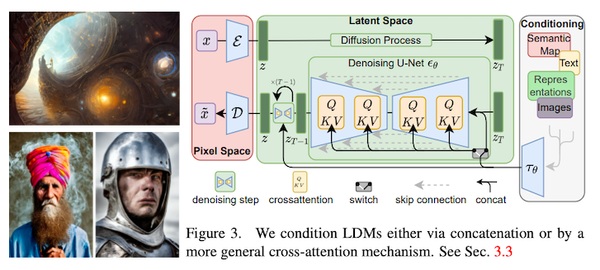
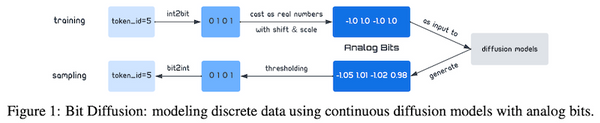
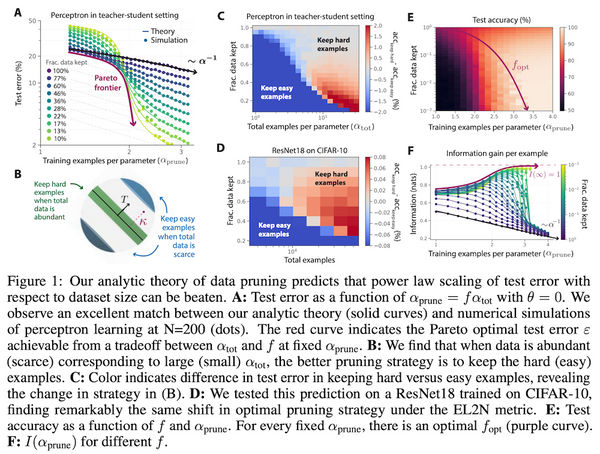
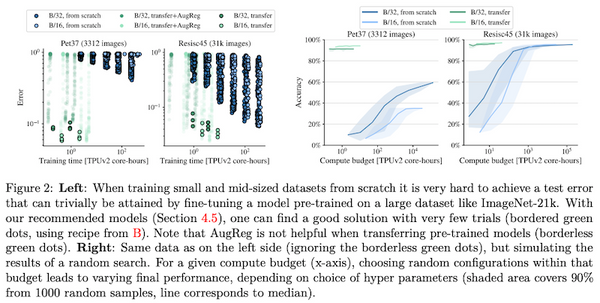
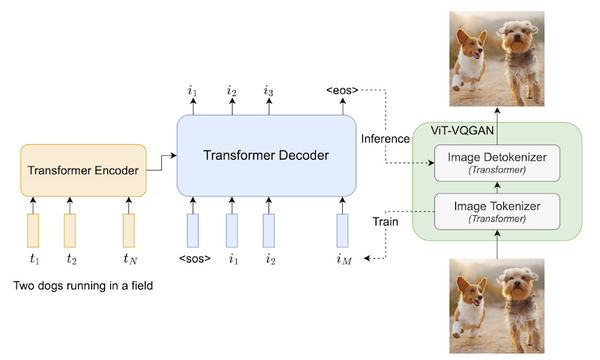
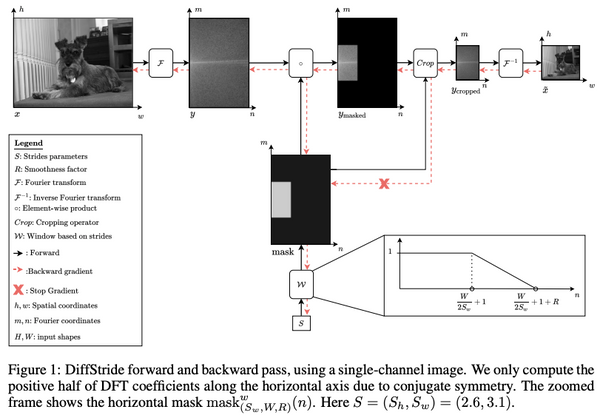
トランスフォーマーを画像分類タスクに適用したビジョン・トランスフォーマー (ViT) は、2020年に提案されて以来、その強力な性能から、画像分類だけでなく、物体検出や領域分割、ビデオの分析など、幅広いコンピューター・ビジョンのタスクで使われています。一方で、大量の事前学習データを必要としたり、データ拡張・正則化を工夫する必要があったりと、訓練にコツが必要でした。発表から2年ほど経ち、「どのように訓練すれば、ViT の性能を最大限発揮できるか」という知見が論文などで発表されてきています。本記事では、比較的新しい論文から、「ViT の性能向上 Tips」に注目し、まとめてみたいと思います。