5 月末に Google から、テキストに忠実かつ非常に写実的な画像を生成できる Imagen が発表されました。最近発表された DALL·E 2 に続き、テキストをもとに画像を生成する「テキスト→画像 (text-to-image)」タスクが急速に発展しています。本記事では、Imagen に採用されている技術の解説を丁寧に紐解いていきます。
論文: Saharia et al., 2022. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
公式ページ: https://imagen.research.google/
はじめに (tl;dr)
Imagen は拡散モデル (Diffusion model) です。テキストに忠実かつ非常に写実的な画像を生成でき、つい最近 OpenAI から発表された DALL·E 2 を生成品質の上で早く破ったと、Twitter をはじめとする SNS で大きな話題になりました。Imagen は、たとえば、以下のような画像を生成することができます。

この図では、画像の下に示したテキストを入力とし、その上の画像を生成させています。このように、人の手によって作られた・撮られたと言っても遜色ない画像を、テキストから忠実に再現することができます。技術的なポイントは以下の通りで、記事で詳しく解説していきます。
- テキストのみで学習したエンコーダーは非常に強力。拡散モデルをスケールさせるより、言語モデルを大きくした方が効率がよい
- 「テキスト→画像」タスクの新しい評価ベンチマーク DrawBench を提案
- 画像の飽和を防ぐための動的な閾値戦略を提案
Imagen の技術的詳細
ここでは、Imagen の技術的な詳細を見ていきます。
ネットワーク構造の概観
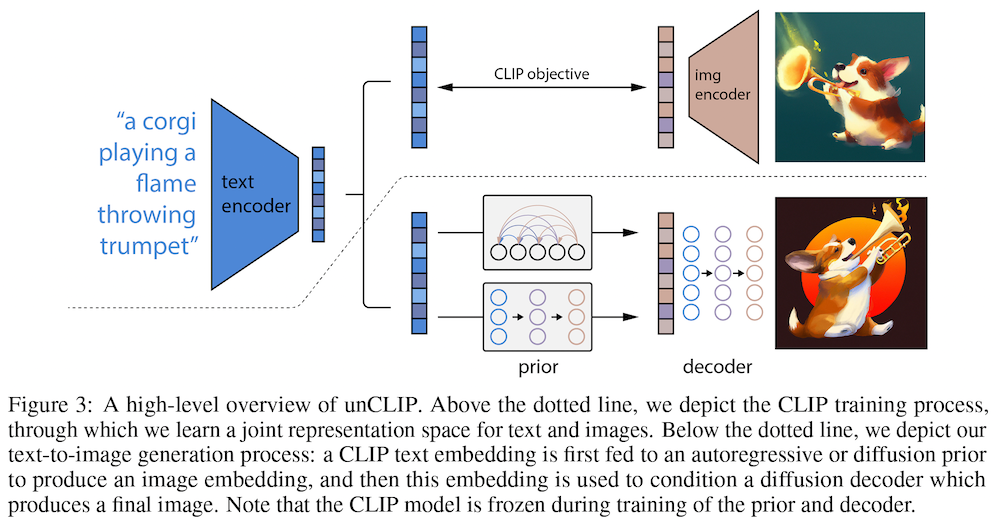
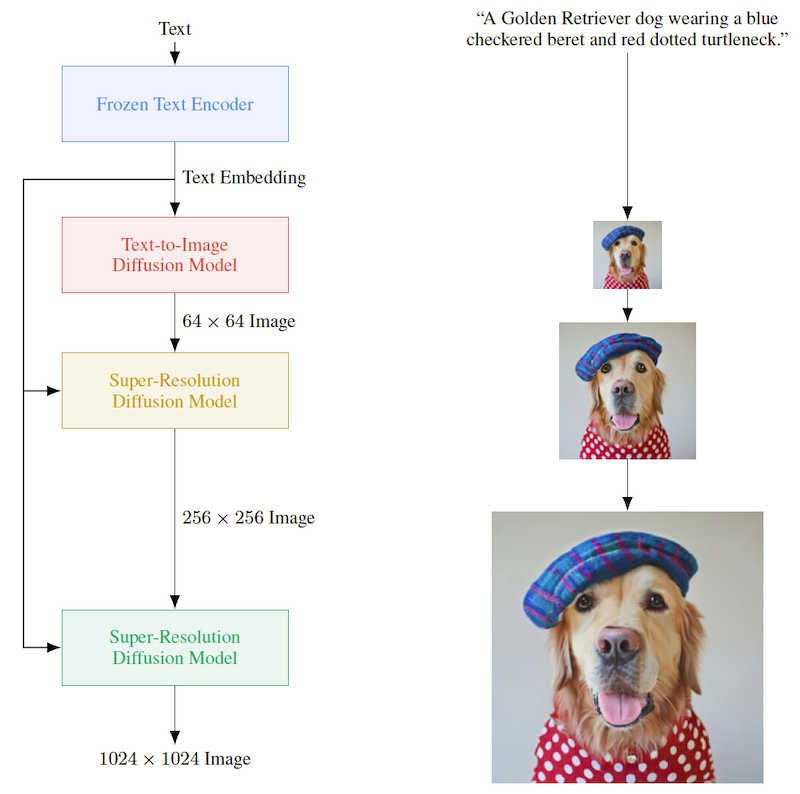
Imagen では、以下 3 つのプロセスを経て画像を生成します (下図)。後述するように、先行研究の DALL·E 2 (Ramesh et al., 2022) と比較すると単純なモデルになっています。
- テキストを言語モデルでエンコードして特徴量ベクトルを得る
- 特徴量ベクトルから、U-Net 形式の拡散モデルを使った「テキスト→画像」モデルで 64×64 サイズの画像を生成する。
- 拡散モデルを使った超解像モデルで、64×64 → 1024×1024 まで高解像化する。
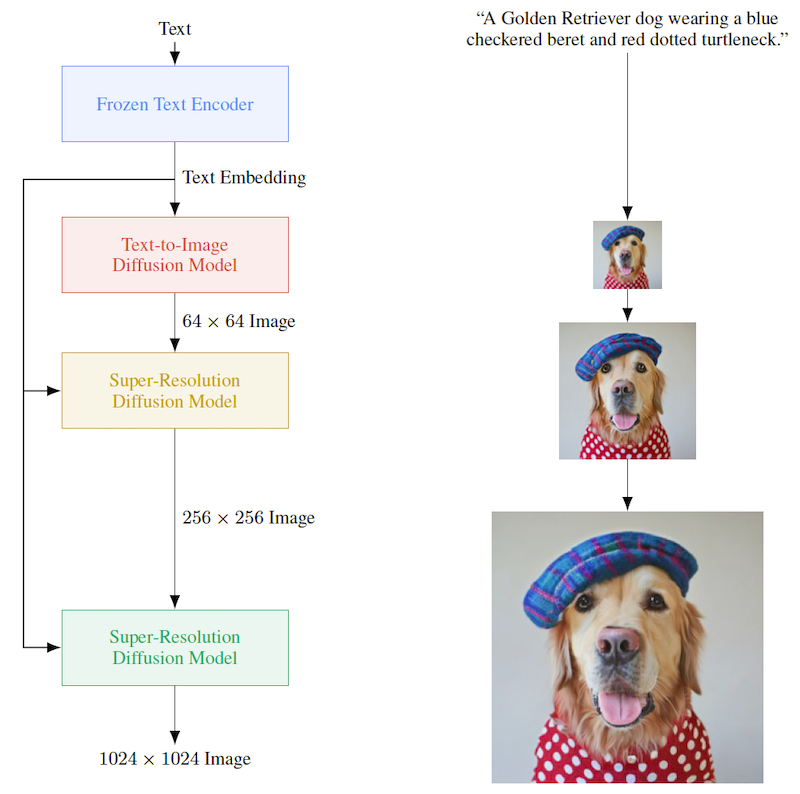
上図にあるように、まずはテキストをパラメータを固定したテキストエンコーダー (Frozen Text Encoder) に入力します。テキストの特徴量ベクトルを得て、次工程の「テキスト→画像」モデル (Text-to-Image Diffusion Model) に入力します。ここでのテキストエンコーダーは、T5 (Raffel et al., 2019) のような言語モデルが使われます。
次に、テキストから画像を生成するモデルに伝播させ、テキストをもとに 64×64 サイズの少し小さい画像を生成します。ここでの生成モデルは、拡散モデルが使われています。最後に 64×64 → 256×256 → 1024×1024 サイズと 2 回超解像モデルを通すことで画像の解像度を上げます。
以下でそれぞれ詳しく説明してきます。
高難易度な DrawBench データセットの提案と重みを固定した巨大言語モデルの使用
ここでは、 テキストエンコーダーモデルの比較用に提案された難易度の高いデータセット DrawBench と、言語モデルを巨大化すると効率良く性能を向上できることを説明します。
Imagen の著者たちは、テキストエンコーダーとして、大規模な言語モデルを使っています。
テキストエンコーダーの候補としては、大きく分けて 2 つあります。1つ目は画像とテキストの対応が取れた訓練データを使って学習させた CLIP などのモデル、 2つ目は BERT や T5 などの大量のテキストデータのみで学習した言語モデルです。著者らは、それらを MS COCO データセットと今回新しく提案した DrawBench データセットで実験し、テキストエンコーダーとしての性能を比較をしています。その結果を示したのが下図です。
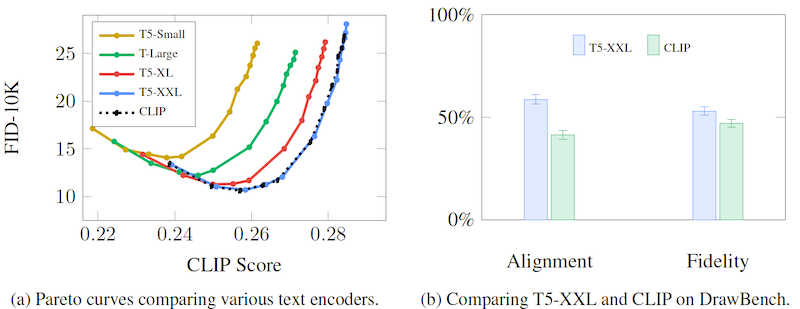
まず、左側の MS COCO データセットにおける比較を見てみましょう。縦軸は FID (Fréchet inception distance) スコアで、学習済みモデルを使って生成した画像と元画像の分布の距離を測ることで性能を比較する評価指標です。MS COCO データセットでは、画像を説明する短いテキスト「キャプション」が画像データに付随しています。この実験では、そのキャプションから生成された画像とキャプション (テキスト) の「一致度」を計測し、比較しています。その「一致度」は、CLIP Score (Hessel et al., 2021) と呼ばれるもので計測されます。
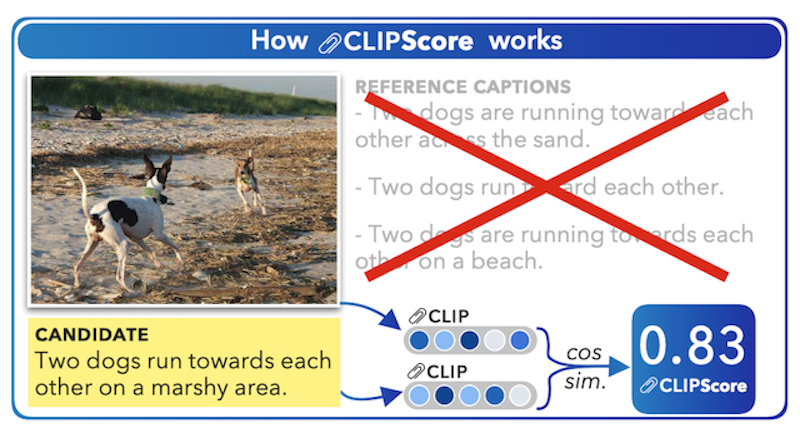
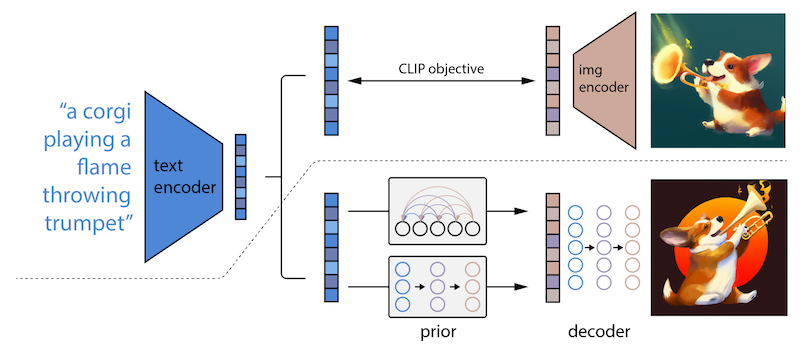
CLIP Score は、Jack Hessel らが提案した画像とテキストの一致度を計測する手法で、CLIP を利用しています。CLIP は下図 (OpenAI のブログから引用) のように、画像とテキストのペアデータを用いて「画像とテキストのペア当てクイズ」をして学習します。この学習形式を対照学習 (contrastive learning) と呼び、形式は少し違えどコンピュータービジョン分野でも自己教師あり学習として事前学習にもよく使われている学習手法です。
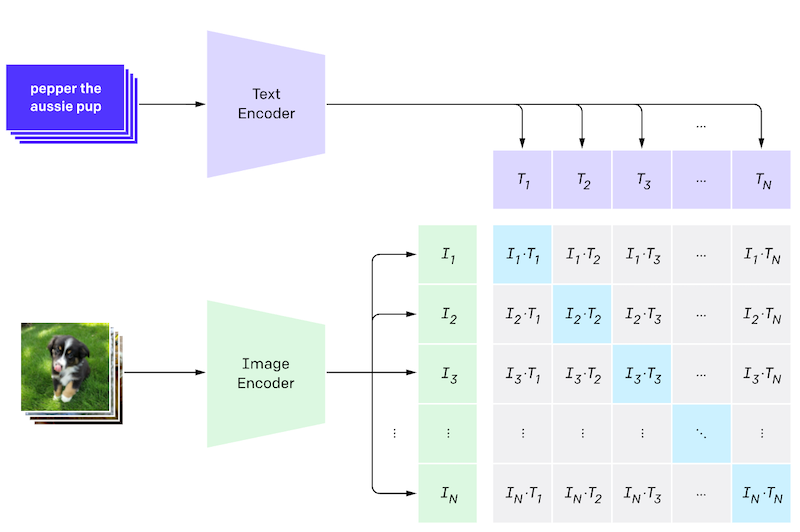
ペア当てタスクを上手くこなすためには、画像エンコーダー、テキストエンコーダー両方で抽出した特徴量の一致度が高くないといけません。その性質を利用したのが、CLIP Score です。CLIP Score では画像とテキストをそれぞれ学習済みの CLIP のエンコーダーで読み込み、それらの一致度をコサイン類似度により算出します(下図)。従前のものは、テキストのサンプル (参照テキスト) を使って一致度を測っていましたが、そのサンプルが不要になることが特筆すべき点です。
改めて、MS COCO における T5 モデル系列のスコアや、CLIP のテキストエンコーダーを Imagen のテキストエンコーダーに使用した時のスコアを見てみましょう。モデル大規模化が高精度化に直結する近年の傾向に漏れず、T5 モデル系列ではモデルが大きくなるほど、CLIP Score と FID のトレードオフが改善しています。また、T5 モデル系列で最大の T5-XXL と CLIP のスコアが大凡一致していることがわかります。MS COCO の評価では、CLIP と言語モデルどちらが優れているかは断定できません。
次に新しく提案された DrawBench データセットにおけるスコアを見てみましょう (上のグラフ b)。DrawBench データセットは、MS COCO より複雑なキャプションで物体生成を評価することを目的にしたデータセットです。 MS COCO ではプロンプトの種類が限られているため、モデル間の差異を容易に把握できないという問題がありました。DrawBench データセットは、異なる色、オブジェクトの数、空間関係、シーン内のテキスト、オブジェクト間の異質な関係を忠実に表現する能力を測定するための、11 カテゴリの計 600 のプロンプトが含まれています。プロンプトのサンプルと、それに従って Imagen で生成した画像の例が下図です。
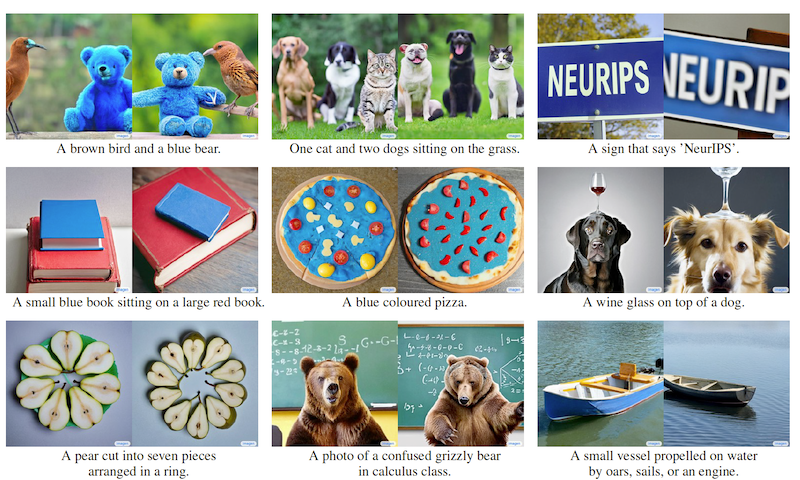
MS COCO のデータと比較すると、「青い色をしたピザ ("A blue coloured pizza.")」 や 「微分積分学の授業で困っているヒグマの写真 ("A photo of a confused grizzly bear in calculus class.")」など、現実世界には存在しないような概念・状況を生成させるタスクが含まれています。後述するように、学習データは現実世界の画像とテキストのペアデータを使っているので、現実世界に存在しない概念を生成するタスクは、学習データに直接答えがないため難しいタスクになっていると言えます。
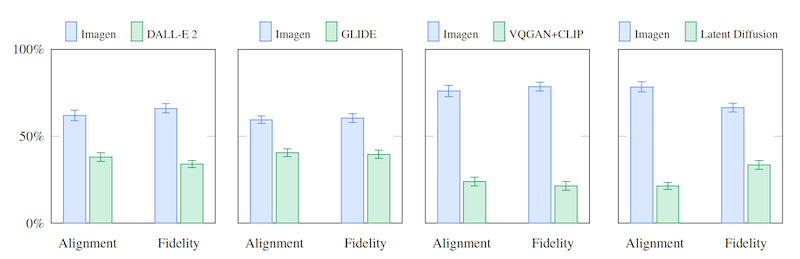
これを踏まえた上で、改めて DrawBench データセットを使った人間による評価結果をみてみます。(下図右、再掲)
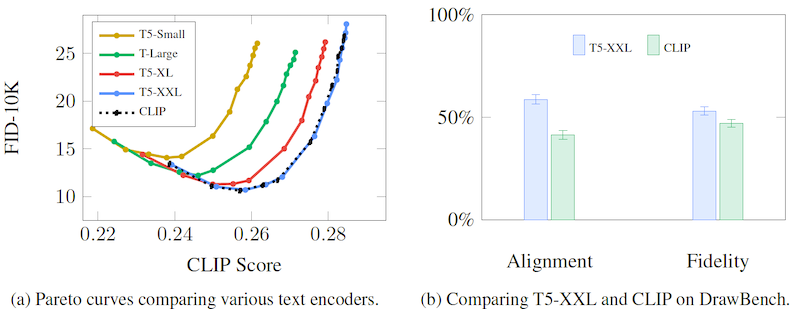
Alignment と Fidelity という評価指標があり、それぞれ「テキストと画像の生合成」「画像の忠実度 (画像が現実の画像のように写実的か) 」の2つの観点で、2つのモデルどちらが優れているかを比べた結果です。両方の評価指標において、 CLIP を使ったものより、 T5-XXL を使ったものの方が優れていることがわかります。
総評すると、(評価指標が異なり、かつ後者は人による感性評価であることが少し気になりつつも) MS COCO データセット (左) を使った評価では T5-XXL と CLIP の差がほぼありませんが、この論文で新しく提案した DrawBench データセットの評価 (右) では言語モデル T5-XXL が優位になっています。
より難しいタスクである DrawBench において、 CLIP よりも 巨大言語モデル T5-XXL の方が良いスコアを出している理由については、著者たちは学習テキストの量とモデルサイズについて指摘しています。 CLIP などの画像と言語両方を扱うモデルより、テキストのみで学習させたモデルの方が、より多くのテキストデータで学習されています。また、テキストエンコーダーのサイズもテキストのみで学習させるモデルの方がかなり大規模なものになります。これらにより、よりリッチなテキスト表現を学習できるとしています。
パラメータを固定した言語モデルを巨大にすると性能が向上する
モデルの性能を向上させるために、モデルのパラメータ数を増やすことが多いですが、この論文ではテキストエンコーダーに使われている言語モデルのパラメータ数を増やす方が、後段の拡散モデル (U-Net) のサイズを大きくするよりも効果的だったと著者たちは述べています (下図) 。
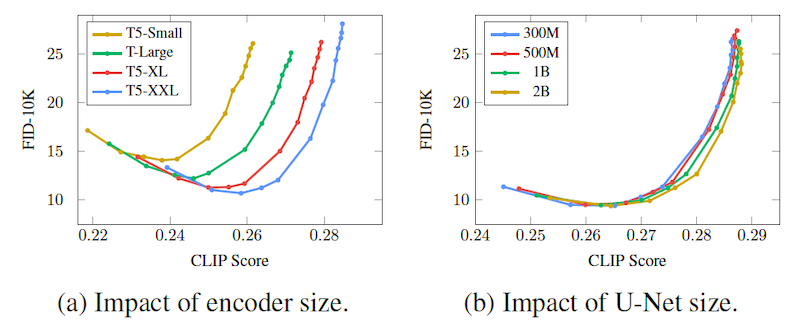
この図で示されているように、言語モデルのサイズを大きくすることは非常に性能の向上に大きく貢献しています (左図)。一方、拡散モデル (U-net) のパラメータ数を増やすことはあまり効果がないようです (右図)。
また、Imagen では、学習中にテキストエンコーダーのパラメーターを固定しています。テキストエンコーダーのパラメーターを固定することにより、計算コストを軽くすることができます。
拡散モデルを使った「テキスト→画像」モデル
Imagen では、テキストから画像を生成する「テキスト→画像」モデルに、拡散モデルを採用しています。拡散モデルにノイズを付与する方法や損失関数を工夫して BigGAN を超える性能を出しつつ、推論速度を向上した Nichol 氏と Dhariwal 氏の論文 (Nichol and Dhariwal, 2021, 以前の解説記事も参照) に従い、U-Net (Ronneberger et al., 2014) 形式のネットワークを採用しています。
U-Net とは、その名が示す通り U字型のネットワークで、抽象度が高く解像度が低い状態 (下図の底) から、再び解像度が高い状態に戻すネットワークです。特徴的なのは、解像度が同じ部分をスキップ結合によって連結させている部分です。この機構により、元画像の特徴を反映した特徴量マップを出力しやすいので、意味的領域分割 (semantic segmentation) のような元画像の詳細な特徴を加味しつつ密な予測マップが必要なタスクで広く利用されています。
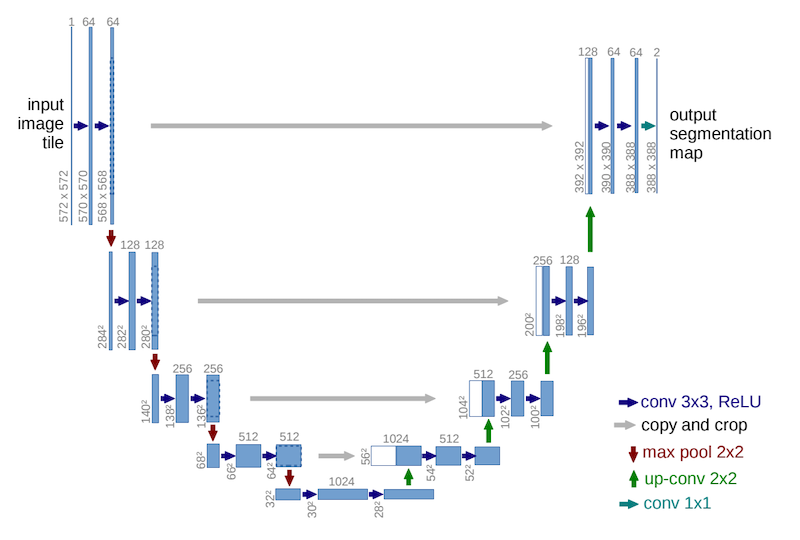
拡散モデルの元祖とも言える「ノイズ除去拡散確率モデル」(DDPM; denoising diffusion probabilistic models, Ho et al., 2020) が U-Net を採用していることの影響か、画像の拡散モデルの多くは U-Net 形式のネットワークを採用しています。
超解像モデル
より高い解像度の画像を生成する Imagen の最終段階でも拡散モデルが使われています。「テキスト→画像」と同様に、U-Net 形式の拡散モデルが使われていますが、著者らはより効率的なネットワーク Efficient U-Net を提案しています。
Efficient U-Net では、低解像度ブロックにより多くのパラメータを使い、残差ブロックを追加しています。低解像度ブロックは一般的に多くのチャンネルを持っているので、メモリや計算のコストあまり増やさずに、モデル容量を増やすことができます。
また、典型的な U-Net のダウンサンプリングブロックでは、ダウンサンプリング操作は畳み込みの後に行われ、アップサンプリングブロックでは、アップサンプリング操作は畳み込みの前に行われます。著者らは、U-Net の順伝播の速度を改善するために、ダウンサンプリングブロックとアップサンプリングブロックの両方でこの順序を逆にしています。これによる性能の劣化はないようです。
分類器を使わずにテキストに整合した画像を生成しつつも、動的な閾値を使って生成画像の過飽和を防ぐ
拡散モデルを生成画像をテキストに沿って条件付けする方法として、分類器誘導型 (classifier-guided) と分類器不使用型 (classifier-free) の 2 種類があります。
前者の分類器誘導型では、その名の通り分類器の勾配を使って拡散モデルを誘導します。$z_\lambda$ をノイズが乗った生成途中の画像、$c$ を条件ベクトル、モデルを $\epsilon_\theta$ とおくと、誘導された後の拡散モデルの更新式は、以下のようになります。
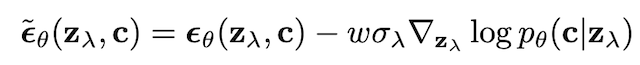
$p_\theta$ は分類モデルです。テキストで条件付けする場合は、CLIP がよく用いられます。
一方、分類器不使用型では、分類器を用いずに、条件付き拡散モデルと非条件付き拡散モデルを同時に学習することで、条件付き拡散モデルの学習を行います。式で書くと以下のように書けます。
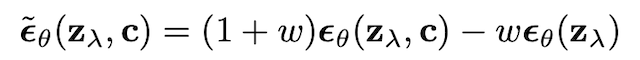
一見、条件付き拡散モデルと非条件付き拡散モデルの2つのモデルが必要であるように思えますが、条件付きベクトル $c$ を空にする (ゼロベクトルを入れる) ことで条件付き拡散モデル1つのみで学習できます。
この誘導重み (guidance weight) と呼ばれるハイパーパラメータ $\omega$ を大きくすると、画像とテキストの一致度は向上しますが、色が飽和状態 (画素出力値が極端になる、下図の場合は黒い部分が増える) になり、画像の品質が下がってしまします。

左の 6 つの画像は誘導なし、右の 6 つは $\omega = 3$ の画像です。 右側画像に黒い部分が増えていることがわかります。
本研究では、一致度を上げつつも画像の品質を上げるために、画像の閾値を動的に変化させる「動的閾値設定 (dynamic shareholding)」を提案しています。擬似コードは以下の通りです。

通常は、上図左のようにモデルの出力値が一定値に収まるようにクリッピングします。画像は $0$ - $255$ の画素値をもちますが、勾配爆発防止のため、学習時は $0$ - $1$ や $-1$ - $1$ にスケーリングします。画像生成をする場合も $0$ - $255$ の値を直接生成するのではなく、スケーリングさせた値を生成させます。左図では、画素値を $-1$ - $1$ にスケーリングさせているため、モデルの出力がその範囲を超えないように調整しています。
一方、右側の「動的閾値設定 (dynamic shareholding)」では、分位点を示すパラメータ $p$ を用いて動的に調整しています。具体的には、$p$ 位分位数 の値 $s$ を使って、モデルの出力をスケールし直しています (論文中に $p$ の設定指針の記述が見当たらないので、おそらく生成対象によって毎回調整しているのだと考えられます)。
「動的閾値設定 (dynamic shareholding)」の効果を定性的に評価したのが下図です。

3つの条件でそれぞれ5段x3列の画像が表示されており、それぞれの段は誘導重み $\omega$ を上から$1,2,..,5$と変化させたものです。誘導重みの値が大きいほど飽和しやすい条件になっています。閾値調整していない水準 (No thresholding) よりは品質が良いですが、静的な閾値調整 (Static thresholding) でも誘導重み $\omega$ が大きな水準では、画像が黒っぽくなってしまっています。それに対し、動的な閾値調整 (Dynamic thresholding) では誘導重み $\omega$ の値が大きくなっても、黒色に飽和することなく画像を生成できています。
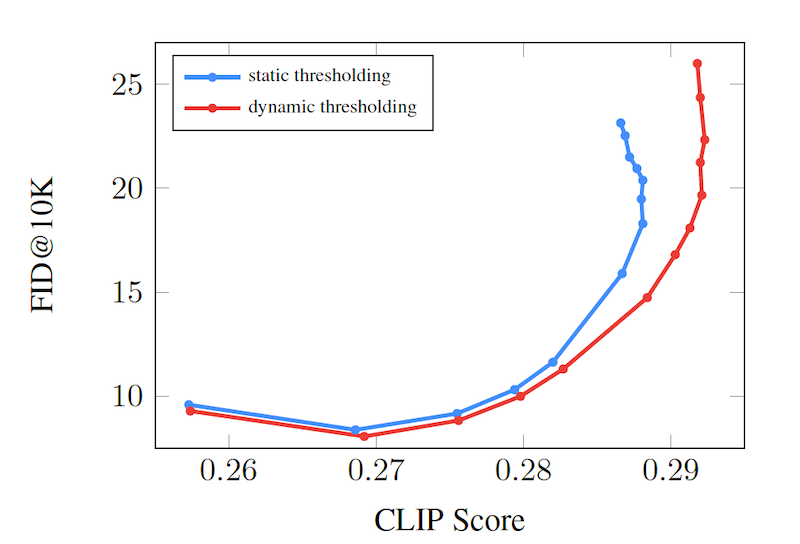
また、定量的に見ても、下図に示すように、 CLIP Score と FID のトレードオフも改善していることがわかります。
学習の詳細
言語モデルは事前学習済みのものを使っているので、新たに訓練する必要があるのは、拡散モデルを使った「テキスト→画像 (text-to-image)」モデルと、2つの超解像モデル (64×64->256×256, 256×256->1024×1024) です。なお、256×256->1024×1024 の超解像は、1024×1024の画像をクロップした画像で 64×64->256×256 の超解像を介して学習させます。使用するデータセットは、Google 社内で持っている 4.6 億のテキスト・画像のペアデータセットと、4 億のテキスト・画像のペアを含む Laion データセット (Schuhmann et al, 2021)、合計 8.6 億のテキスト・画像のペアデータセットで学習をしています。大規模データセットを使った際に出てくる問題点については、後述します。
モデルの詳細なアーキテクチャー、オプティマイザの設定や学習ステップ数、その他のハイパーパラメータは元論文の Appendix に非常に詳細な情報が載っていますので、気になる方は是非ご覧ください。
他手法との比較
DALL·E 2 と Imagen のアーキテクチャ比較
最近話題になった「テキスト→画像 (text-to-image)」手法として DALL·E 2 (Ramesh et al., 2022) があります。
Imagen と DALL·E 2 のアーキテクチャを比較してみましょう。
上が Imagen で下が DALL·E 2 です。Imagen は今まで見てきたように、事前学習済みの言語モデル、「テキスト→画像 (text-to-image)」モデル、拡散モデルを使った超解像の組み合わせで、比較的単純なアーキテクチャをしています。先行研究で見られたような CLIP による誘導がないので、CLIP を使わなくても画像を生成できます。
一方、 DALL·E 2 は少し複雑になっています。ざっくり言うと、与えられたテキストに整合するような CLIP の画像特徴量を求めるために、拡散モデルベースの事前分布を学習させます。画像の埋め込みを生成する「事前分布 (prior)」や、埋め込みから画像自体を生成する「デコーダー (decoder)」があり、CLIP による画像埋め込みも必要です。ここでは割愛しますが、詳しく知りたい方は、以前の記事を参照願います。Imagen の方が、DALL·E 2 よりも単純な機構で画像を生成できていると言えそうです。
次に定量評価です。 DrawBench を使った人による評価 (2つのモデルが生成した画像を見て、どちらが優れているかを回答) です。 DALL·E 2 や VQGAN+CLIP など SNS 上で非常に話題になった手法と比較しても優れた生成結果を出していることがわかります。
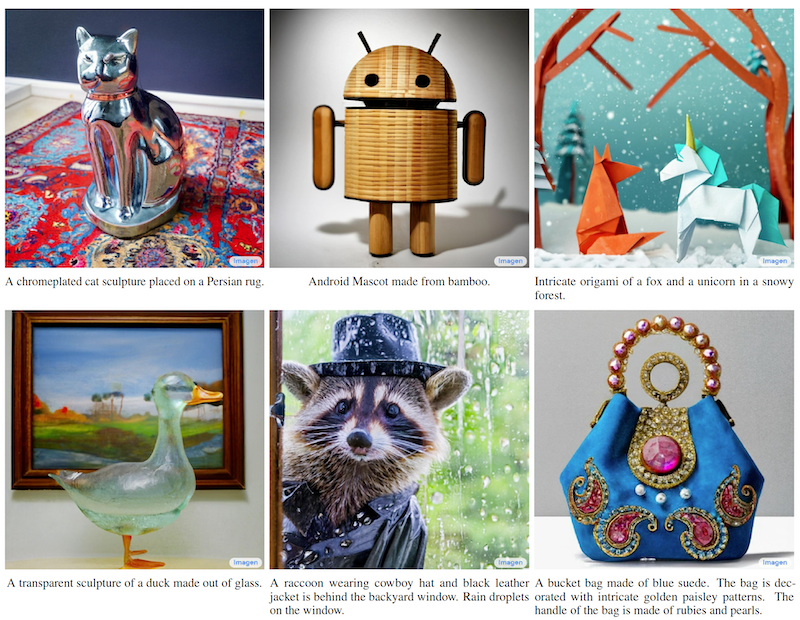
最後に、生成された画像をいくつか紹介します。非常に品質が高く、「AI が生成しましたと言われても信じられない」レベルです。また、「クロムプレートの猫が、ペルシア絨毯に置いてある」「会社オフィスでスーツを着たテディベアのグループが友人の誕生日を祝っている。机にはピザケーキが置いてある」など、非現実的な状況であるにもかかわらずテキストに忠実に生成ができていることがわかります。

社会的影響など
Imagen は非常に強力な生成モデルであり、非常に高品質な画像をテキストから生成することができます。しかし、高品質すぎて悪用の可能性があるため、著者らは現時点ではデモやコードを公開しないことにしているようです。
また、このような巨大モデルにはありがちですが、社会的な偏見が含まれていると著者らは述べています。大規模データセット・大規模モデルを使った研究は、大規模なWebスクレイピングデータセットに大きく依存し、このアプローチにより、近年、モデルを急速に改善することが可能になりました。しかし、この種のデータセットは社会的なバイアスを反映しやすいことが、GPT-3 (Brown et al., 2020) や「基盤モデル」(Bommasani et al., 2021)の論文でも指摘されています。
個人的には、このレベルの生成結果において有効な自動評価指標がなく、人手の評価に頼らざるを得ないことは、今後の研究指針にとって問題かもしれないと思っています。人手の評価は恣意的な評価も可能になってしまうので、今回のようにコードやモデルの公開もなく、人手の評価に頼った結果の提示をされた場合、研究論文としての信頼性が担保されるのかは個人的に気になるところです。また、同じ論文において提案されている評価用のプロンプト DrawBench を使って評価している点においても、研究結果の客観性に疑問を投げかける一因になっています。
まとめ
本記事では、非常に強力なテキスト→画像生成モデル Imagen を紹介しました。社会的バイアス、悪用、評価指標などの問題はあれど、テキストに沿った高解像度画像を自動生成できる実用的・社会的な影響は大きいと思われます。前段で述べたように、評価指標の問題があるので、今後どのように高品質な生成モデルを評価するかは ひとつの課題になってきそうです。
ちなみに、モデルの非公式実装が Phil Wang 氏によって公開されています。計算資源に余裕のある方は試してみるのも良いかもしれません。
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人