近年、ビジョン・トランスフォーマー (Vision Transformer; ViT) がコンピューター・ビジョンの分野を席巻しています。本記事では、Google Research と Google Brain から発表された ”Do Vision Transformers See Like Convolutional Neural Networks?" (Raghu et al., 2021) という論文を解説しながら、従来使われていた CNN とビジョン・トランスフォーマーとの違いを探っていきます。
なお、本記事は、藤井さん との共同執筆です。
ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての高品質な記事を毎月5〜6本配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
この論文の要旨と、このブログの内容
この論文で述べられている要旨は、主に以下6つです。CNN 系ネットワークの代表として、ResNet (He et al., 2016) と ViT とを比較しています。
- ViT は、CNN と比較すると、浅い層と深い層で取得される表現の類似性が高い
- ViT は、CNN と異なり、浅い層から大局的な表現を取得している。しかし、浅い層で取得される局所的な表現も重要である。
- ViT のスキップ接続は CNN (ResNet) よりもさらに影響力が強く、性能と表現の類似性に強い影響を与える。
- ViT は、ResNet と比較すると空間情報を保持している
- ViT は、大量のデータによって高品質な中間表現を学習できる
- MLP-Mixer の表現は、どちらかといえば ResNet よりも ViT に近い
このブログでは、まず CNN 系モデルの代表例である ResNet と ViT の構造を軽くおさらいしたあとに、この論文で述べられている、取得されている表現の違いを細かく見ていきます。
ResNet の基礎
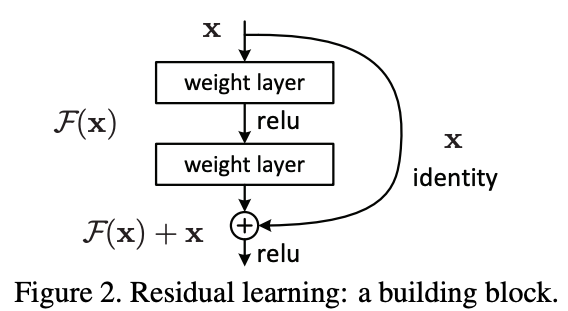
ResNet は、画像系タスクにおいて非常に代表的なモデルです。下図 (Figure 2) のように、重みを使って伝播させる側で、重みの層を飛ばしたスキップ結合 (skip connection) との和をとるような処理をしています。このスキップ結合との和をとる処理により、勾配消失などの問題が緩和され、従前のネットワークよりも深層化が可能になりました。
Vision Transformer (ViT) の基礎
まず、Vision Transformer (ViT) に使われているトランスフォーマー・エンコーダー (Transformer Encoder) を解説します。
トランスフォーマー
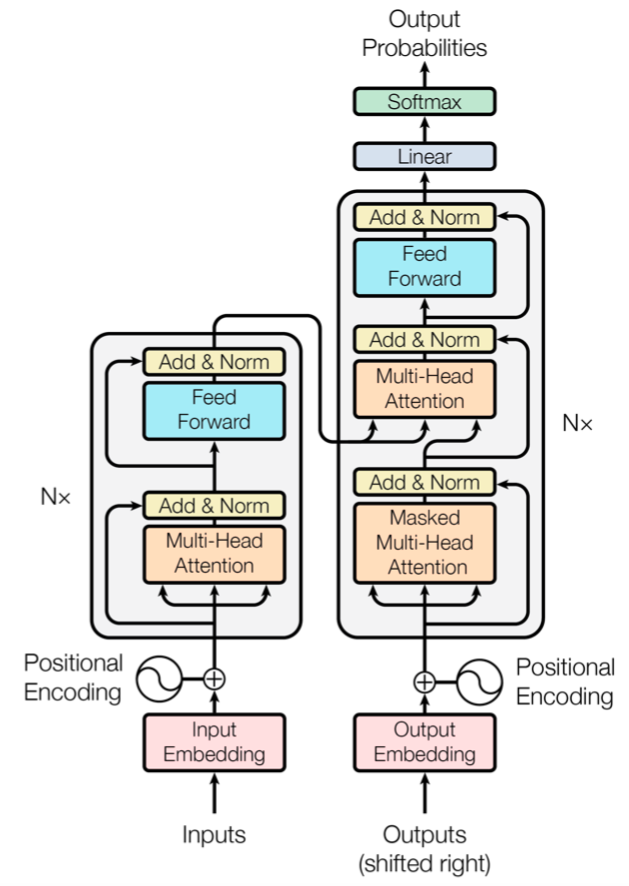
トランスフォーマーは、“Attention Is All You Need” (Vaswani et al., 2017) という論文で提案されたモデルで、それまで LSTM・CNN 等がメインで使われていた状況に対する挑発的なタイトルでも話題になりました。CNN でも LSTM でもない自己注意機構 (self-attention) という機構を使い、それを積み重ねたモデル (トランスフォーマー) によって既存手法を大きく上回る成果を上げています。
下図の Multi-Head Attention(複数ヘッド注意機構)と書かれている部分が、トランスフォーマーのコア部分ですが、ResNet のようにスキップ結合を使っていることにも注意してください。
トランスフォーマーで使われる注意機構では、$Q$ (クエリ), $K$ (キー), $V$ (値) の3つの変数を使います。端的にいえば、クエリーの単語と キーの単語の関連性 (attention weight) を計算し、それぞれの キーに紐づく値を掛け合わせるという仕組みです。
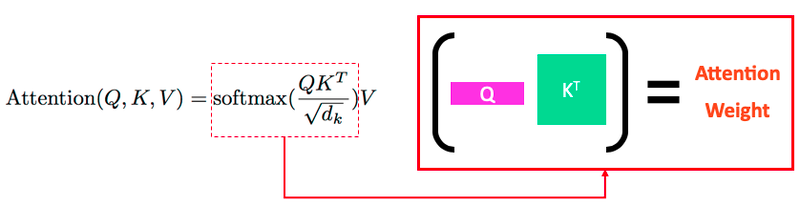
$Q,K,V$ による計算を1つのヘッドと定義し、そのヘッドを複数用いた(全結合でネットワークでいうと”隠れ層の数”を増やした)複数ヘッド注意機構 (multi-head attention) は以下のように定義されます。上図の (単一ヘッド) 注意機構は $Q$ と $K$ をそのまま使っていましたが、複数ヘッド注意機構では各ヘッドに専用の射影行列 $W_i^Q$, $W_i^K$, $W_i^V$ が対応しており、それらを使って射影した特徴量を用いて注意の重みを計算します。
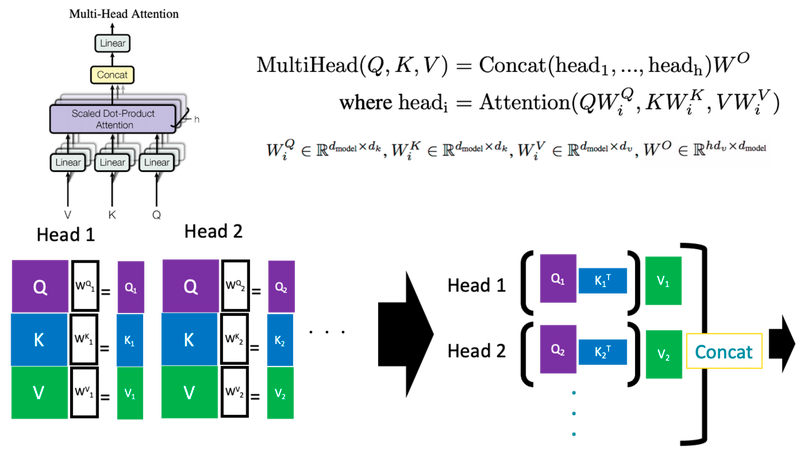
この注意機構で使う $Q,K,V$ を全て同じ入力から計算したものは特に自己注意(Self-Attention)と呼ばれます。トランスフォーマーのエンコーダー (encoder) 部分や、デコーダー (decoder) 部分の最初の注意機構がそれにあたります。デコーダー部分の「クロス注意機構」と呼ばれる部分は、 $Q$ をエンコーダーから、$K$, $V$ をデコーダーから計算しているので、「自己」注意機構ではありません。
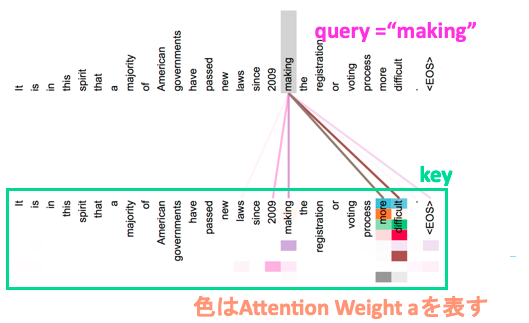
実際に適用したイメージを図で描くと以下のようになります。この図は、"making" という単語をクエリとしてそれぞれのキー単語に対する注意の重みを算出したものを可視化したものになっています。トランスフォーマーでは複数ヘッド自己注意機構を用いて後ろの層に伝播させており、それぞれのヘッドは異なった依存関係を学習しています。下図のキーの単語に複数の色が付いていますが、それぞれのヘッドの注意の重みを表したものになっています。
Vision Transformer (ViT)
Vision Transformer (ViT) は、トランスフォーマーを画像分類タスクに適用したモデルで、2020年10月に提案されました。中身はオリジナルのトランスフォーマーとほとんど同じですが、自然言語処理と同じように、画像を入力として扱えるようにする工夫をしています。
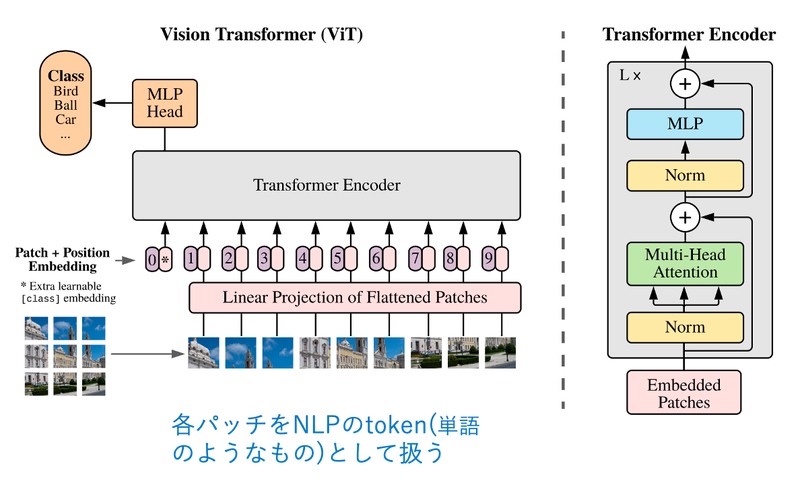
ViT ではまず、画像を 16×16 サイズの N 個の「パッチ」に分割します。パッチ自体は 3次元のデータ (高さ×幅×チャネル数) なので、言語 (2次元) を扱うトランスフォーマーでは直接扱えません。そこで、平坦化 (flatten) した後に線形射影し、2次元のデータに変換します。そうすることにより、各パッチを単語のようなトークン (token) として扱い、トランスフォーマーに入力することができます。
また、ViT は事前学習 (pre-training) した後に微調整 (fine-tuning) されます。ViT は JFT-300M という3億枚もの画像を含むデータセットを用いて事前学習し、ImageNet などの下流タスクで微調整します。ViT は、純粋なトランスフォーマー系のモデルとして初めて ImageNet で SOTA 性能を達成しました。これをきっかけに、トランスフォーマーをコンピューター・ビジョンに適用した研究が大きく盛り上がっています。
しかし、ViT の学習は大量のデータを必要とします。トランスフォーマーは、データが少ない状況では精度が低いですが、データが多くなるにつれ精度が上がり、JFT-300M で事前学習させた場合では、CNN を凌駕する結果となっています。これには帰納バイアスが関わってくるのですが、本ブログの内容とは関係が薄いため割愛します。詳細については原論文を参照してください。
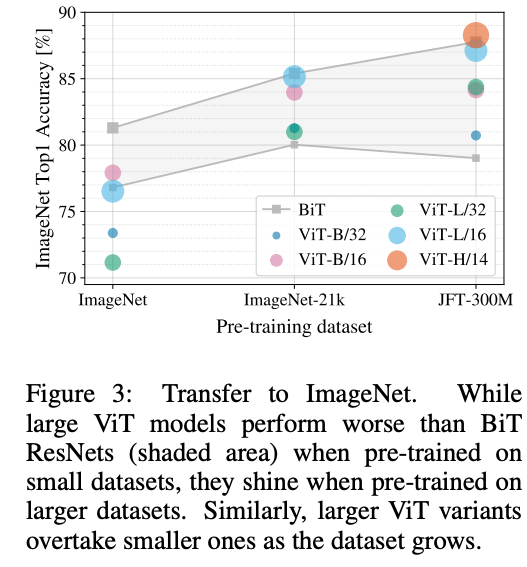
取得している表現の観点から、ResNet と ViT を比較する
ここまで、ResNet と ViT の概要を見てきました。これらは両方とも画像認識タスクで良い成果を出すことができますが、これらの違いはどこにあるのでしょうか?その問いに答えてくれるのが、本記事で紹介する ”Do Vision Transformers See Like Convolutional Neural Networks?" (Raghu et al., 2021) という論文です。
要旨は、冒頭でも述べた以下6つです。それぞれ詳しく見ていきましょう。
- ViT は、CNN と比較すると、浅い層と深い層で取得される表現の類似性が高い
- ViT は、CNN と異なり、浅い層から大局的な表現を取得している。しかし、浅い層で取得される局所的な表現も重要である。
- ViT のスキップ接続は CNN (ResNet) よりもさらに影響力が強く、性能と表現の類似性に強い影響を与える。
- ViT は、ResNet と比較すると空間情報を保持している
- ViT は、大量のデータによって高品質な中間表現を学習できる
- MLP-Mixer の表現は、どちらかといえば ResNet よりも ViT に近い
1. ViT は、CNN と比較すると、浅い層と深い層で取得される表現の類似性が高い
ViT と ResNet の大きな違いとして、初期層の視野の広さが挙げられます。下の画像をご覧ください。
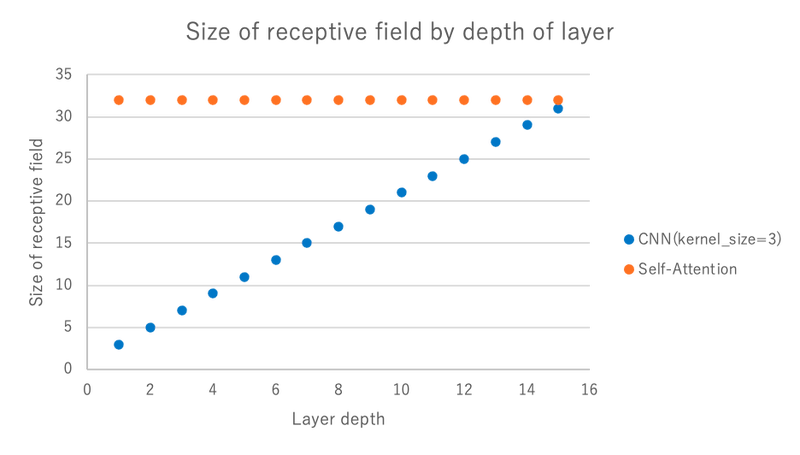
CNN (ResNet) は固定サイズのカーネル分の視野 (3 もしくは 7 のサイズ) しか持っていません。具体的には、CNN ではカーネルの周りの情報を「畳み込む」ことを層ごとに繰り返すことによって視野を徐々に広げていきます。一方、ViT は自己注意機構を用いているため、最下層でも全域視野をもつことが可能です。このように、ネットワークの構造的に視野が異なります。
実際の ViT の視野 (自己注意機構の有効距離) を示したものが下の図です。浅い層において、CNN のように局所視野をもっている部分もありますが、全域的な視野をもっているヘッドも多いことがわかります。
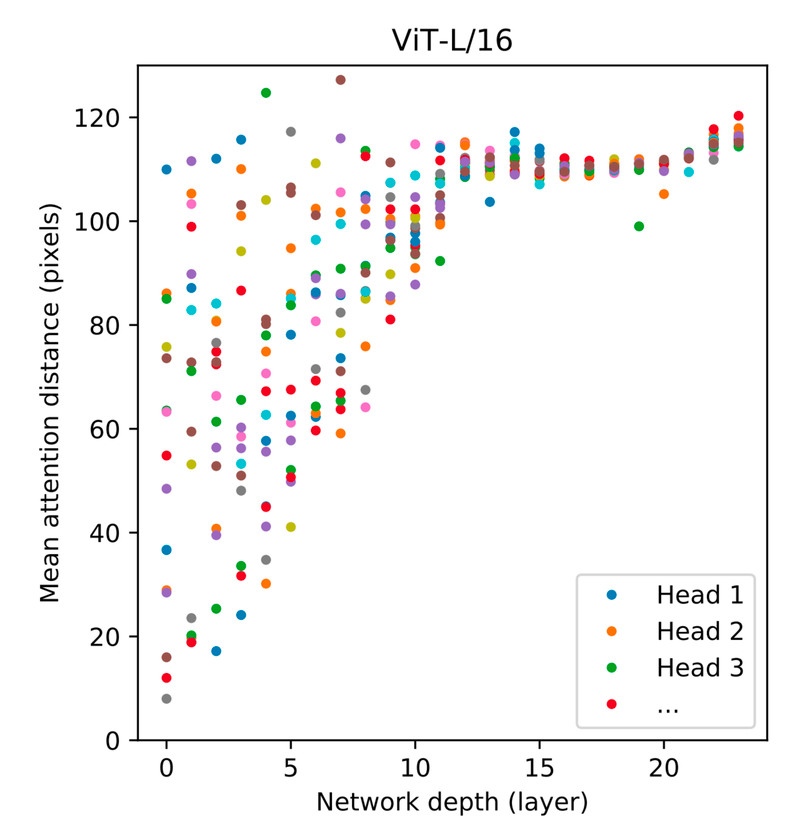
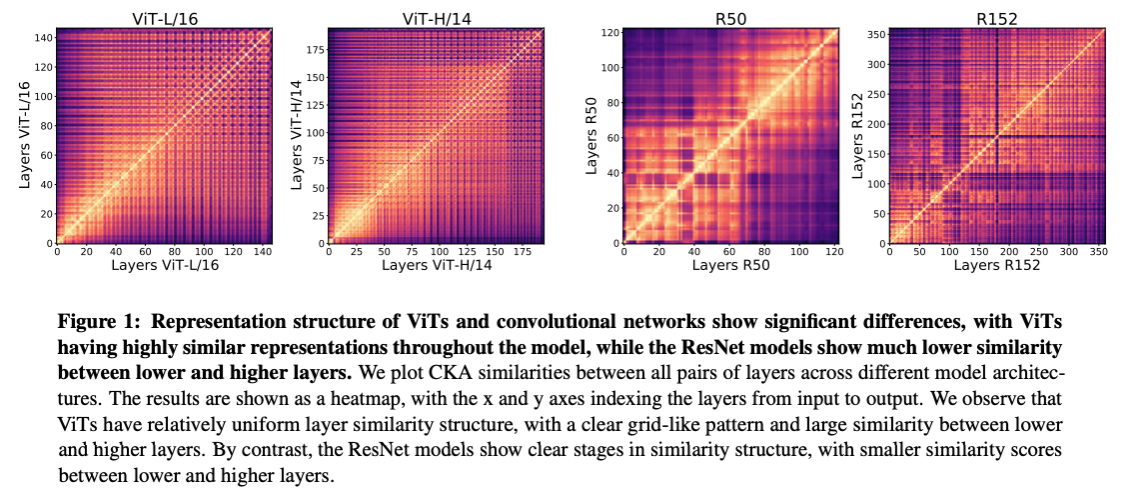
では、取得されている表現と層の深さにはどのような構造的な違いがあるのでしょうか。それを確かめるため、層ごとに取得している表現の類似性をプロットしたのが下の図 (Figure 1) です。
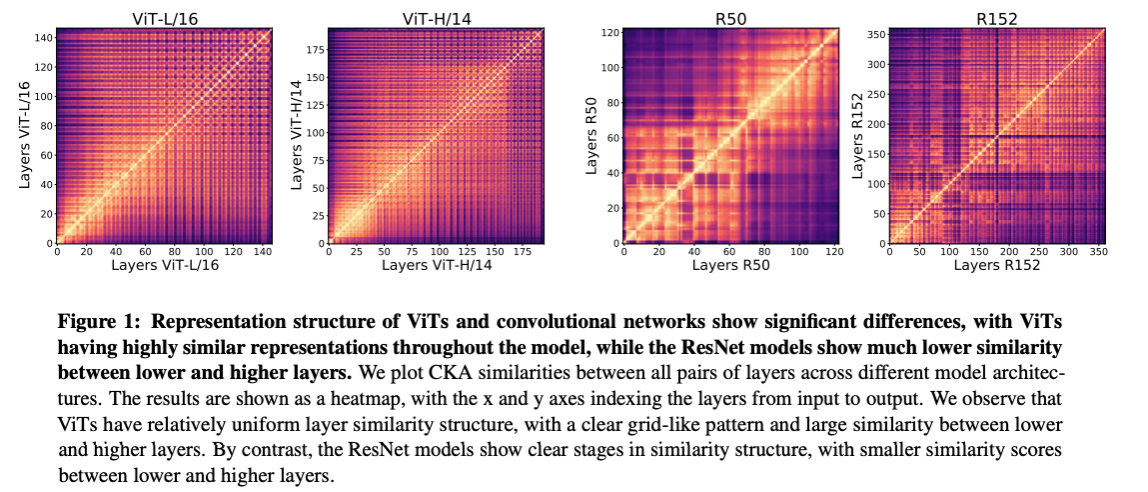
上の図では、CKA 類似性という指標で層ごとに取得している表現の類似性をプロットしたものです (CKA 類似性に関する説明は、技術的な詳細に入るため割愛します。詳細を知りたい方は原論文をご参照ください)。縦軸と横軸に層のナンバリング (深さ) をおいて、層ごとに取得している表現の類似性を示した図になっています。図の対角成分は自身との類似性になるため、当然ながら高い値になっていますが、それ以外の部分に注目してみます。
まず、ViT (左2つ) ですが、全体として色づいているため、層の深さに関係なく似ている表現が取得されていそうだということがわかります。それに対して CNN (右2つ) は、浅い層と深い層で取得している表現に類似性がないことに気づきます。これは、ViT では最初から大域的な表現を取得しているのに対し、CNN では層の伝播をしないと大域的な表現が取得できないことに起因していそうです。
次に、ViT と ResNet で取得している表現を直接比較してみます。それを示すために、ViT と ResNet の間の類似性をプロットしたのが下の図 (Figure 2) です。
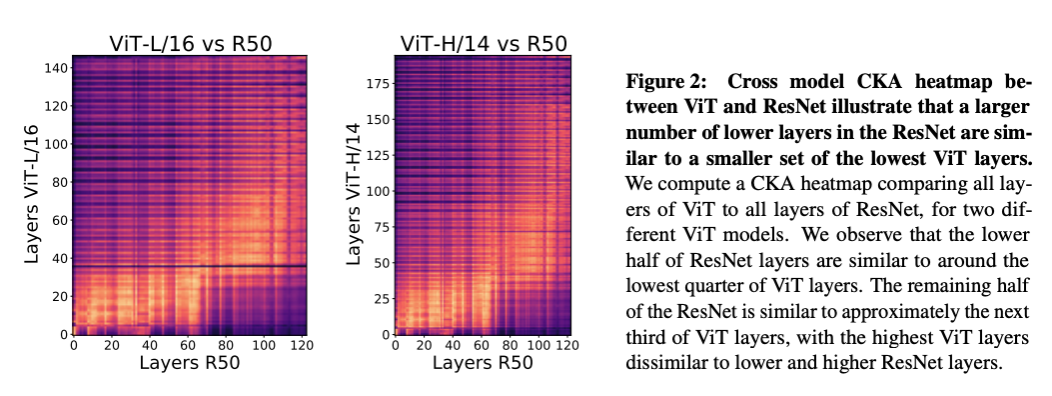
これを見ると、ViT の 1〜40 層目と ResNet の 1〜70 層目までの特徴量の類似性が高いことがわかります。つまり、ViT では 40 層かかる表現の取得を、ResNet では 70 層かかっており、浅い層で表現の取得の方法が大きく異なっているということです。こちらも ViT では最初から大域的な表現を取得しているのに対し、CNN では層の伝播をしないと大域的な表現が取得できないことに起因していそうです。また、ViT の深い層と ResNet の深い層では表現の類似性が低くなっています。よって ViT と ResNet では画像表現の抽象化のされ方が大きく異なっているということがわかります。
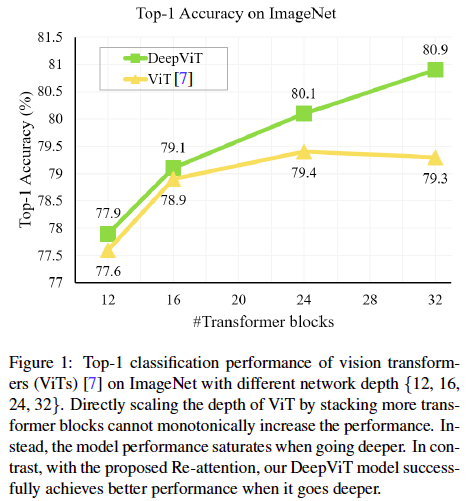
ちなみに、ViT は浅い層と深い層で自己注意が似通っているため、深層化による恩恵を受けられないということをモチベーションにした研究もあります (Zhou et al., 2021)。「似たような注意マップが生成されてしまうため、ViT で深いネットワークを使っても恩恵が得られない」という問題意識からスタートした研究です。一番単純な解決策として、特徴量の次元数をあげることでその問題を解決することができますが、計算量が爆発してしまいます。この研究の著者たちは、ヘッド間の多様性が高いという点に着目し、異なるヘッド間で特徴量を混合する学習パラメーターを導入した Re-Attention という機構を提案しています。その Re-Attention を使い、深層化の恩恵を受けられるようになったモデルである DeepViT を用いて成果をあげています。
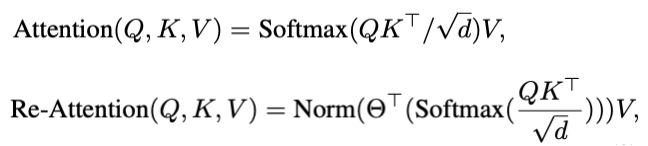
2.ViTは、CNNと異なり、浅い層から大局的な表現を取得している。しかし、浅い層で取得される局所的な表現は重要である
ここでは、もう一度自己注意機構の有効距離に注目してみます。3億枚の画像からなる JFT-300M で事前学習した後に ImageNet (130万枚の画像) で微調整したときの自己注意の有効距離(5000データの自己注意の距離の平均)を示したのが下の図 (Figure 3) です。
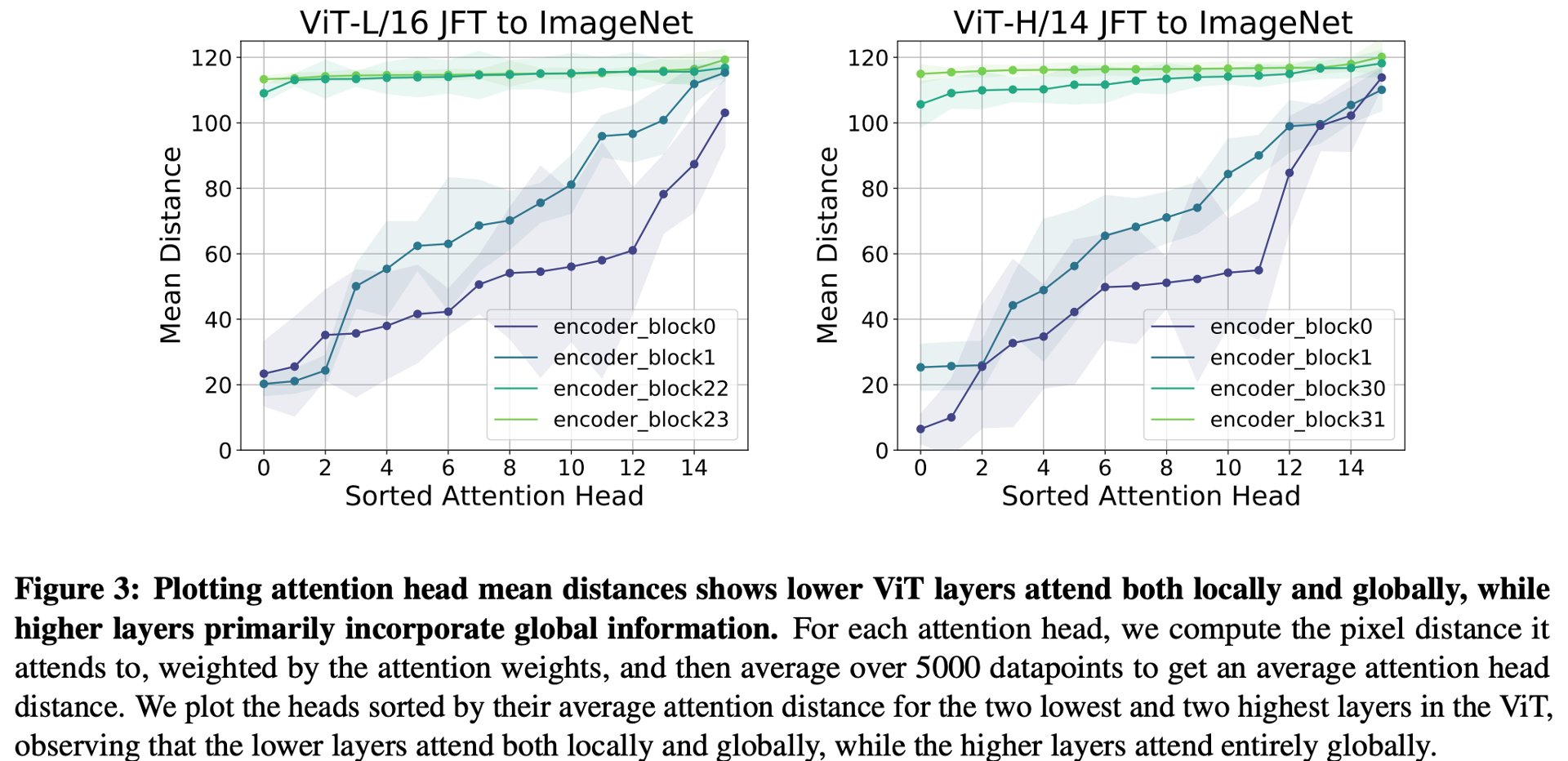
浅い層 (encoder_block0, 1) では、局所的な表現と大域的な表現の両方を取得していることがわかります。それに対し深い層 (encoder_block22, 23, 30, 31) において取得している表現は全て大域的な表現になっていることがわかります。
ビジョン・トランスフォーマーの説明の項で見たように、ViT の学習には大量のデータ (JFT-300M など) が必要で、データが不十分な場合は精度が下がります。その場合、自己注意の有効距離はどのように変化するのでしょうか?
それを実験的にみたのが下の図 (Figure 4) です。
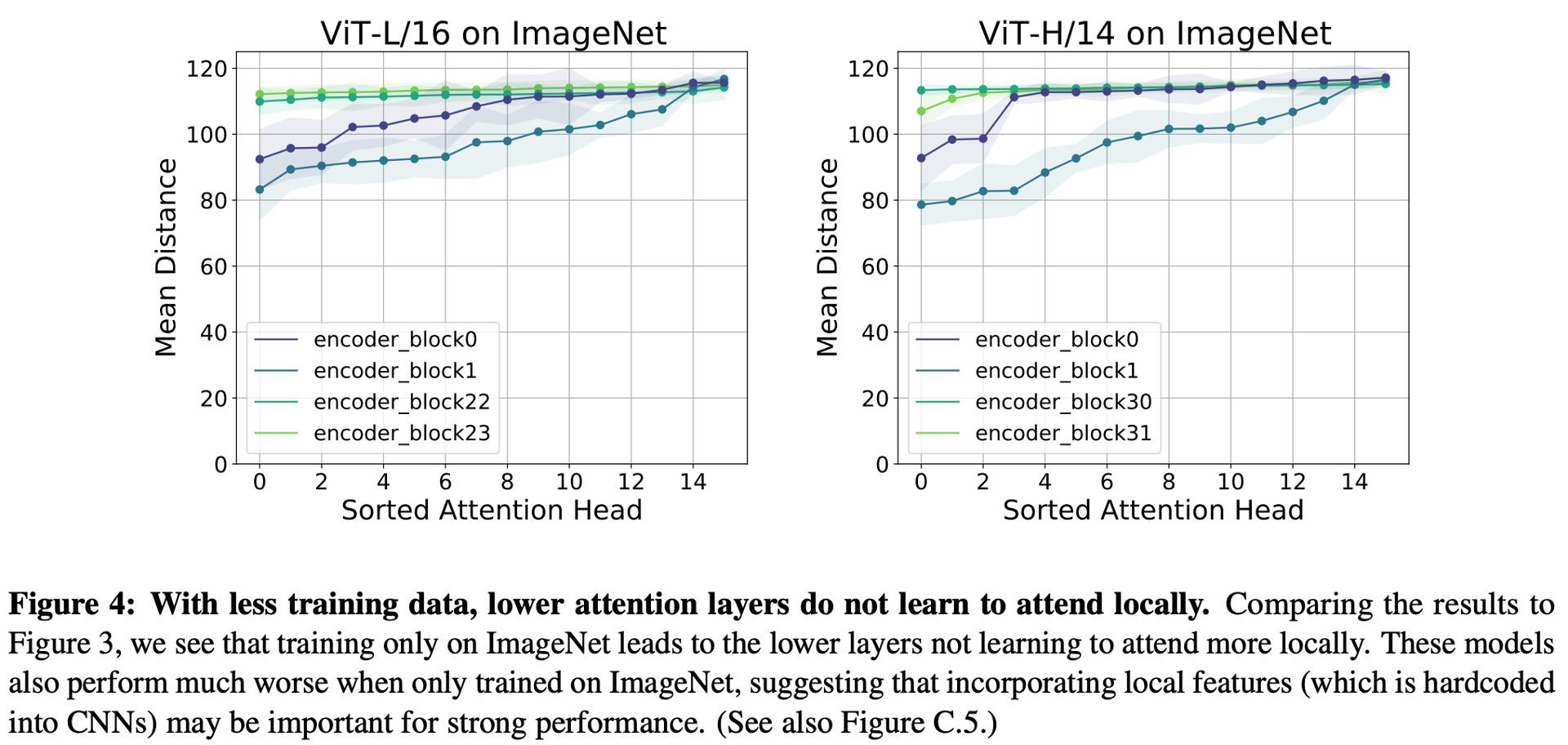
これは、ImageNet のみで ViT を学習させたときの自己注意の有効距離をみています。Figure 3 と Figure 4 を見比べてみると、データが少ない場合は、浅い層で局所的な表現を取得できていないことがわかります。この結果と「データが少ない場合、ViT では精度が出ない」という事実から、十分なデータで学習された ViT や CNN で取得させている「局所的な表現」というのは、精度に大きく効いているということがわかります。
少し話題は変わりますが、データ量と取得される表現はどのような関係があるのでしょうか?それをみたのが、下の図 (Figure 12) です。
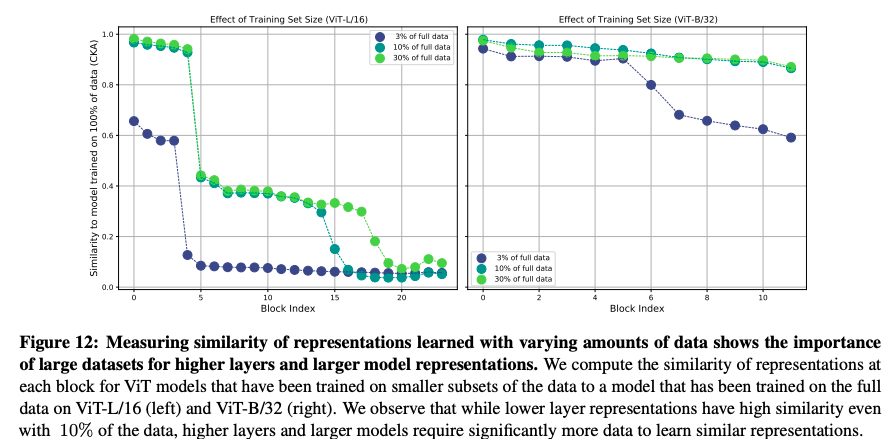
この図では、データ全てを使って学習した表現と、データの一部を使って学習したときの表現の類似性を比較しています。浅い層の表現においては、10% 程度のデータで、データ全てを使って取得した表現とある程度までは類似性が高まっています。しかし、深い層の表現においては、30% のデータがあっても類似度は 0.2 より低くなっています。このことから、「精度に貢献している深い層の表現は、大量のデータがないと学習できない」と言えそうです。さきほどは局所表現が大切だと述べられていましたが、深い層で取得できる大域表現も重要そうです。
ここでは明記されていませんが、おそらく JFT-300M による実験なので、全体のデータの 3% といっても、10M 程度のデータ量 (ImageNet のおよそ10倍) の量があります。これは私の考察になりますが、「30% のデータ量 (100M) 程度があれば浅い層で取得すべき局所表現が取得でき、さらにデータがあれば大域表現においても重要なものを取得可能になる」と言えるかもしれません。
3.ViTのスキップ接続はCNN(ResNet)よりもさらに影響力が強く、性能と表現の類似性に強い影響を与える
次にスキップ結合と取得表現の類似性の関係をみてみましょう。それを表したのが下の図 (Figure 8) です。

この図の実験では、ある層 $i$ のスキップ結合を排除したときの取得表現の類似度を計算しています。この図と Figure 1 の左 (ViT) を比べると、スキップ結合を排除した層 $i$ を境に、取得表現の類似度の傾向が大きく変化していることがわかると思います。つまり、スキップ結合は、表現伝播に大きく影響を与え、それが排除されると層の類似性が大きく変化してしまうということです。ちなみに、中間層でスキップ結合を排除してしまうと、精度は 4% 程度下落してしまうようです。
次に、スキップ結合が情報の伝播においてどのような役割を果たしているのかを見てみます。下の図 (Figure 7) を見てください。
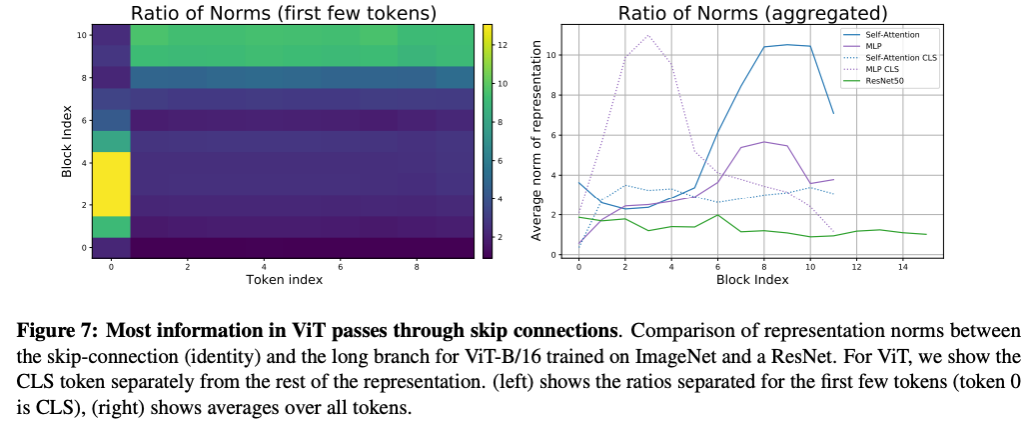
Figure 7 左図では、$i$ 層スキップ結合の情報、つまり$i$ 層においる自己注意への入力情報 $z_i$ と、その $z_i$ に自己注意や多層ネットワークによる変換を行なったあとの特徴量 $f(z_i)$ の比である $||z_i|| / ||f(z_i)|| $ をトークン (16×16サイズの画像のパッチなど) ごとにプロットしてます (トークン0はクラストークンなので画像パッチではないことに注意してください)。この比が大きいほど、スキップ結合を通して情報が伝播されていくことを意味しています。Figure 7 左図をみると、クラストークンは初期層でスキップ結合を通じて伝播しており、画像は自己注意や多層ネットワークを通じて伝播していることがわかります。そして、その傾向は深い層では逆転しています。
また、右図が ResNet との比較です。緑色の線が ResNet ですが、それに対して ViT は値が大きい、つまりスキップ結合を通した情報伝播が大きな役割を果たしていることがわかります。
論文で特に言及はありませんでしたが、このスキップ結合が情報伝播で大きな役割を果たしていることにより、Figure 8 において中間層のスキップ結合を排除すると、精度が大きく下がったのかもしれません。
4. ViT は ResNet と比較すると空間情報を保持している
次に、どの程度位置情報を保持しているかを ViT と ResNet で比較してみます。下の図を見てください。
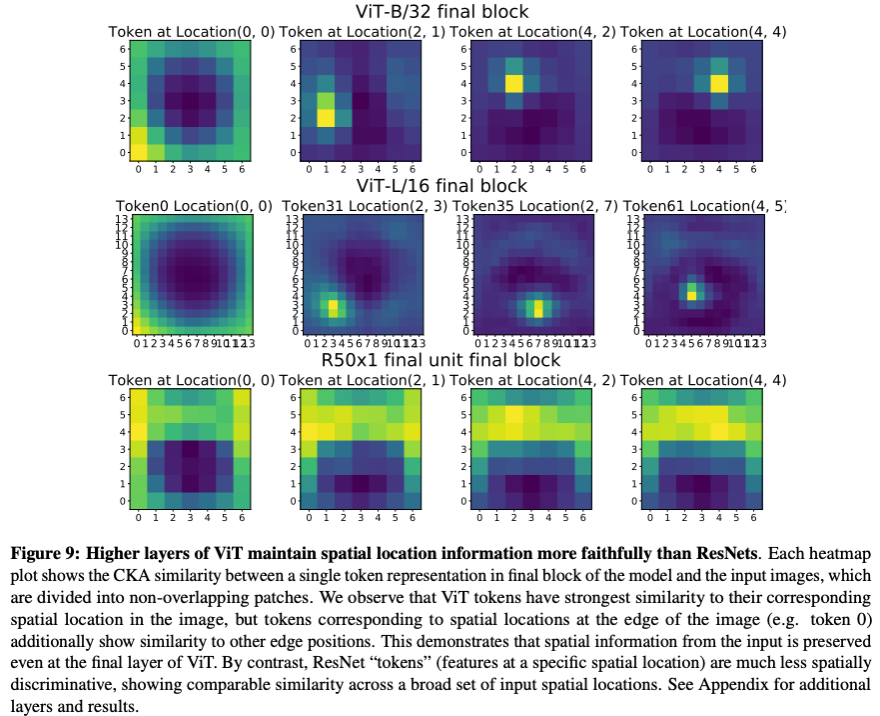
この実験では、ViT と ResNet がどの程度位置情報を残しているかを、ある位置における入力画像のパッチと最終層の特徴量マップの CKA 類似性をプロットすることにより実験したものです。位置情報を残しているならば、ある位置の入力画像のパッチとの類似性が、特徴量マップのその位置に相当する部分の位置のみで高くなるはずです。
まず、ViT を見てみましょう (上、中段) 。見込み通り、最終層において、対応する位置の類似性が高くなっています。つまり、ViT は位置情報を残しながら表現を伝播しているということです。次に、ResNet を見てみましょう (下段)。こちらは、関係ない位置の類似性が高くなっており、位置情報を保持していないことがわかります。
この傾向の違いは、ネットワーク構造の違いによるものだと思われます。下の図をみてください (図はWang et al., 2021より引用)。
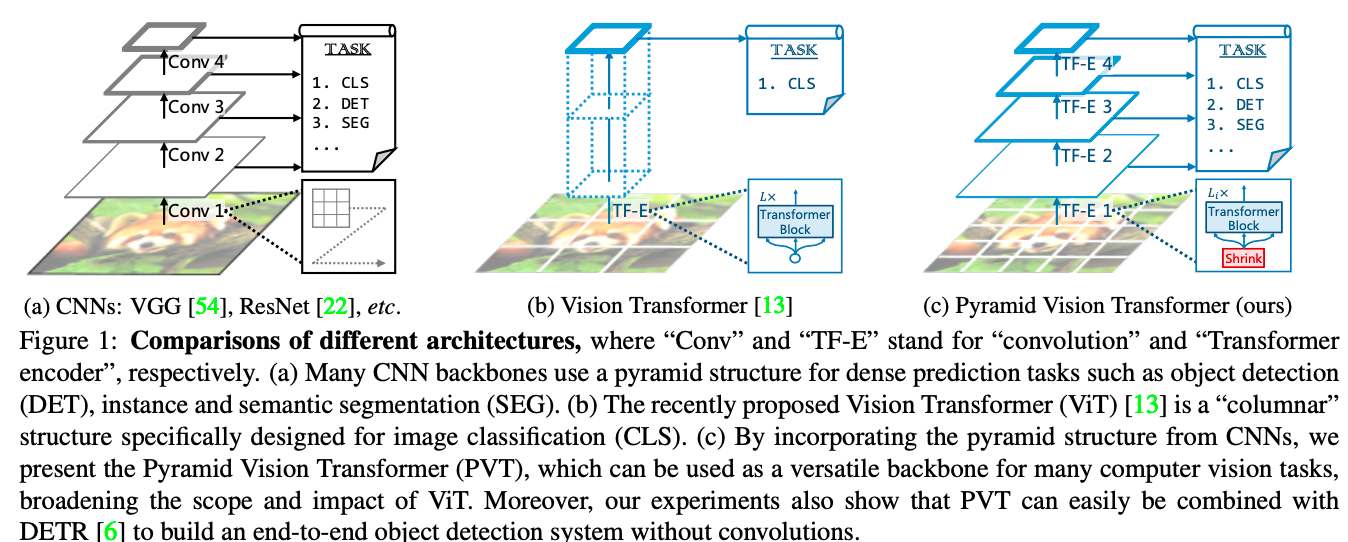
ResNet をはじめとする CNN 系画像分類ネットワークは、解像度を下げながら表現を伝播させます。例えば、ResNet には 5 つのステージがあり、それぞれにおいて解像度が半分になるので、最終的な特徴量マップの大きさは 1/32 × 1/32 の大きさになります (上図左)。一方、ViTは、最初に 16×16 サイズにトークン化するため、その部分における解像度は下がるのですが、その解像度のまま最終層に伝播していきます。そのため、ViT はResNet と比較すると位置情報を残しやすくなります。しかし、そもそもですが、画像分類タスクでは分類の判断に位置情報を必要としないので、「位置情報が残っているので ResNet より ViT が有利」とは言い切れません。
また、近年の研究では、ResNet のように徐々に解像度を落としていく戦術がビジョン・トランスフォーマー系の研究でもよく用いられています。例えば、上図右の Pyramid Vision Transformer です。トランスフォーマー系は、自己注意で画像サイズの4乗に比例して占有メモリサイズが大きくなっていきます。そのため、大きな解像度は扱いにくいのですが、CNN系のように徐々に解像度を落としていく戦術を用いることにより、メモリを節約しながら最初の層では高解像度の情報を扱うことができるようになるというわけです。
5. ViT は、大量のデータによって高品質な中間表現を学習できる
次は、中間層表現の質について見ていきましょう。その実験を行なったのが、下図 (Figure 13) です。
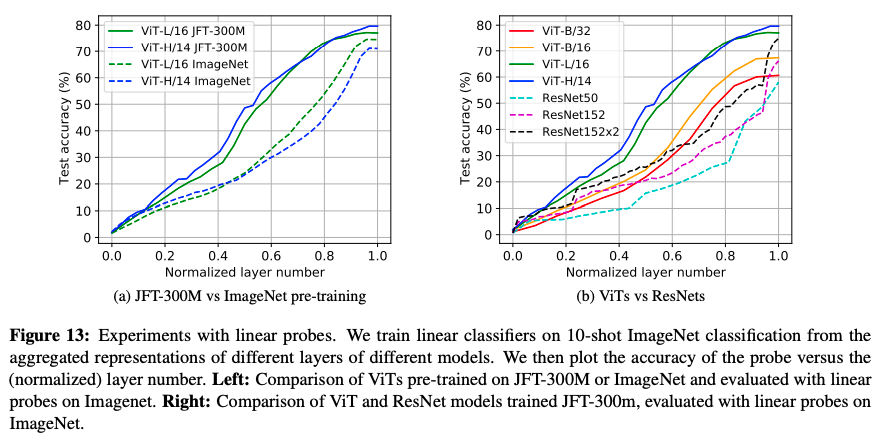
この実験では、中間層の表現を使って、線形モデルで分類ができるかを試しています。線形モデルのような単純なモデルで精度が出ているほど、よい表現が得られているというイメージです。
まずは、データセットのサイズと得られている表現の関係を見てみましょう (左図)。ここでは、130万枚の画像を含む ImageNet (点線) と、3億枚の画像を含む JFT-300M (実線) で実験したときの比較をしています。見てわかるように、巨大なデータセットである JFT-300M で学習した表現の方が良い表現が得られています。次に、ResNet を含めたモデルにおける比較です。大きなモデルの方が、良い表現が得られていることがわかります。
余談ですが、右図において、ResNet 系モデルの精度が最終層付近で一気に上がっています。これは何故でしょうか。
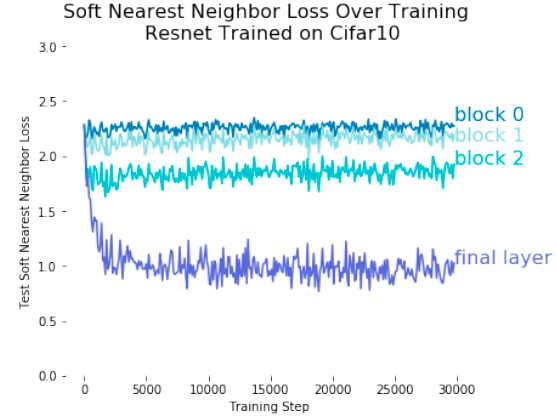
そのヒントになる研究が Frosst 氏らによってなされています (Frosst et al., 2019)。 Frosst 氏らは、温度項つきの Soft Nearest Neighbor Loss というものを ResNet の中間層に導入して、その挙動を調べています。Soft Nearest Neighbor Loss は、値が大きいときはクラス別の特徴量が絡み合っている状態を示し、逆に小さいときにはクラス別に特徴量が分離できていることを示すような指標です。
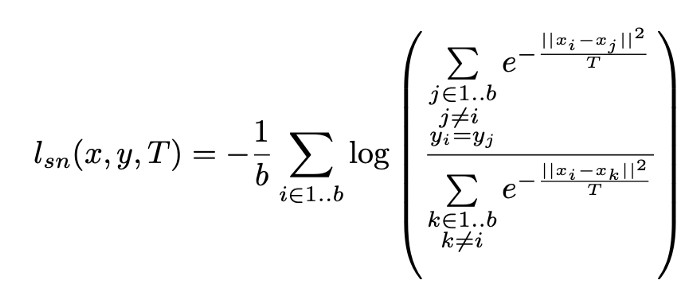
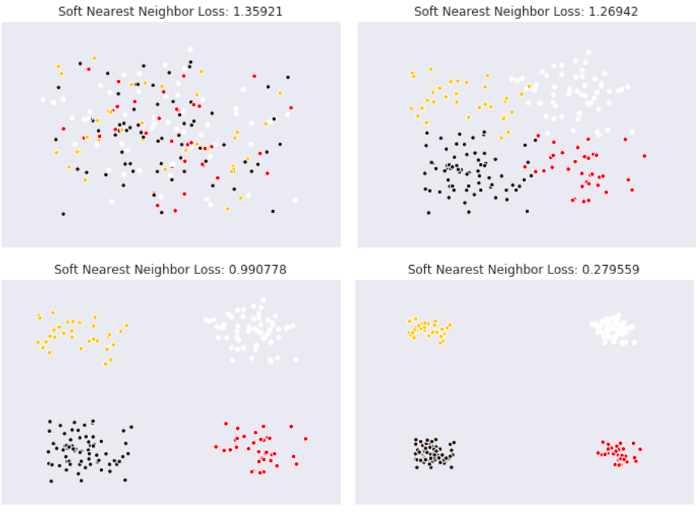
ResNet の各ブロック中での Soft Nearest Neighbor Loss の値を調べたのが下の図です。ResNet は高性能な画像分類ネットワークとして知られていますが、最終層以外ではクラス毎の特徴量を分離できていないことを示しています。私の考察ではありますが、ResNet のこの性質のおかげで、Figure 13 にあるような最終層付近で急激に精度が向上するような挙動が示されたのではないかと考えています。
6. MLP-Mixer の表現は、どちらかといえば ResNet よりも ViT に近い
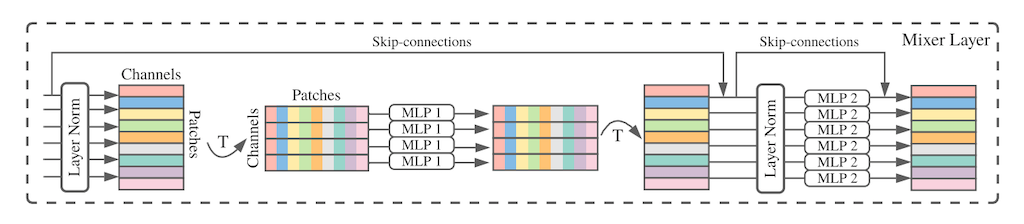
近年、トランスフォーマーの代わりに、多層パーセプトロン (MLP)、つまり全結合層を使ったネットワークを使った高精度な画像分類モデルが提案されています。その代表が、MLP-Mixer (Tolstikhin et al., 2021) と呼ばれるネットワークです。このネットワークの構造は下図のようになっています。
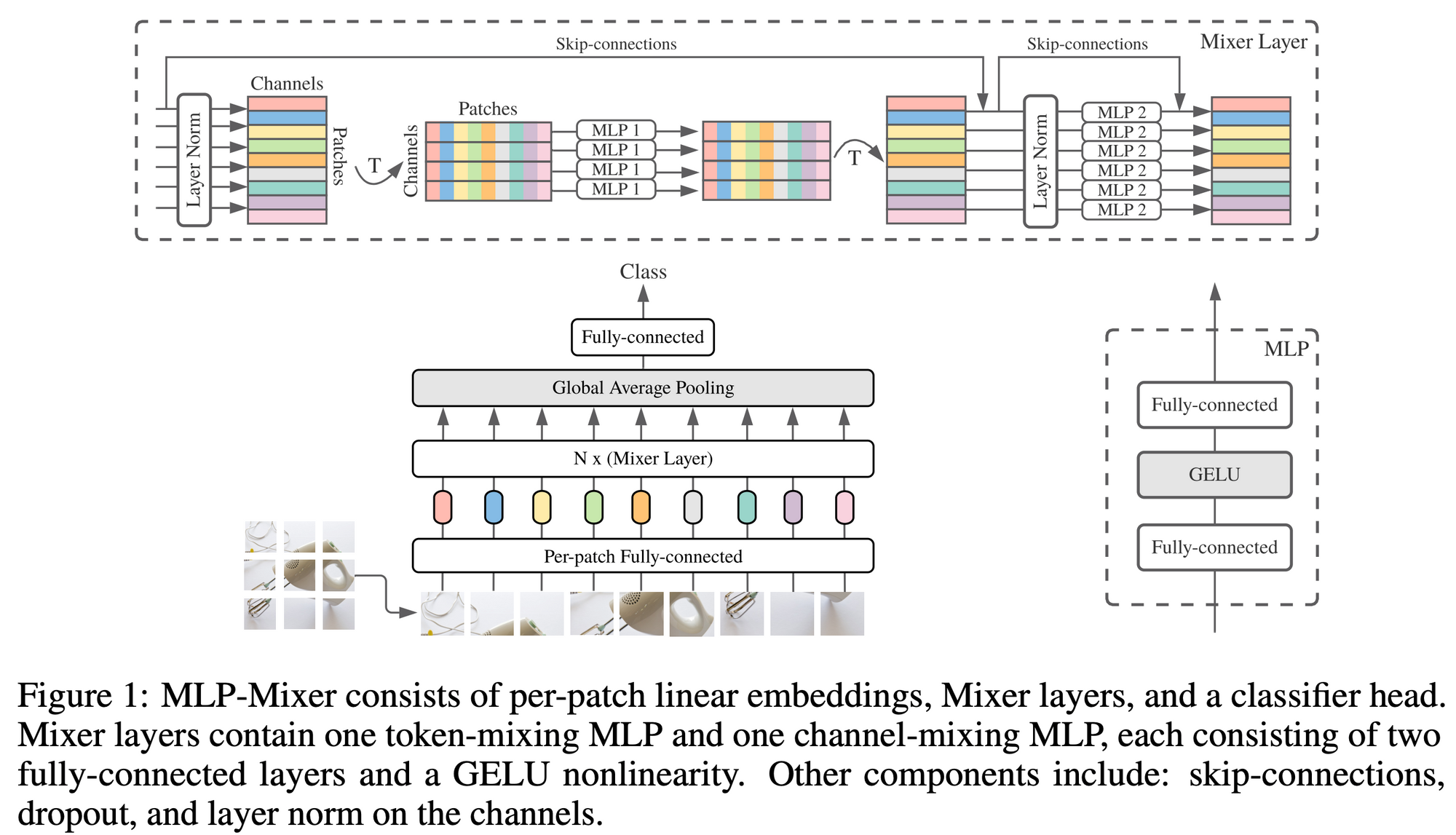
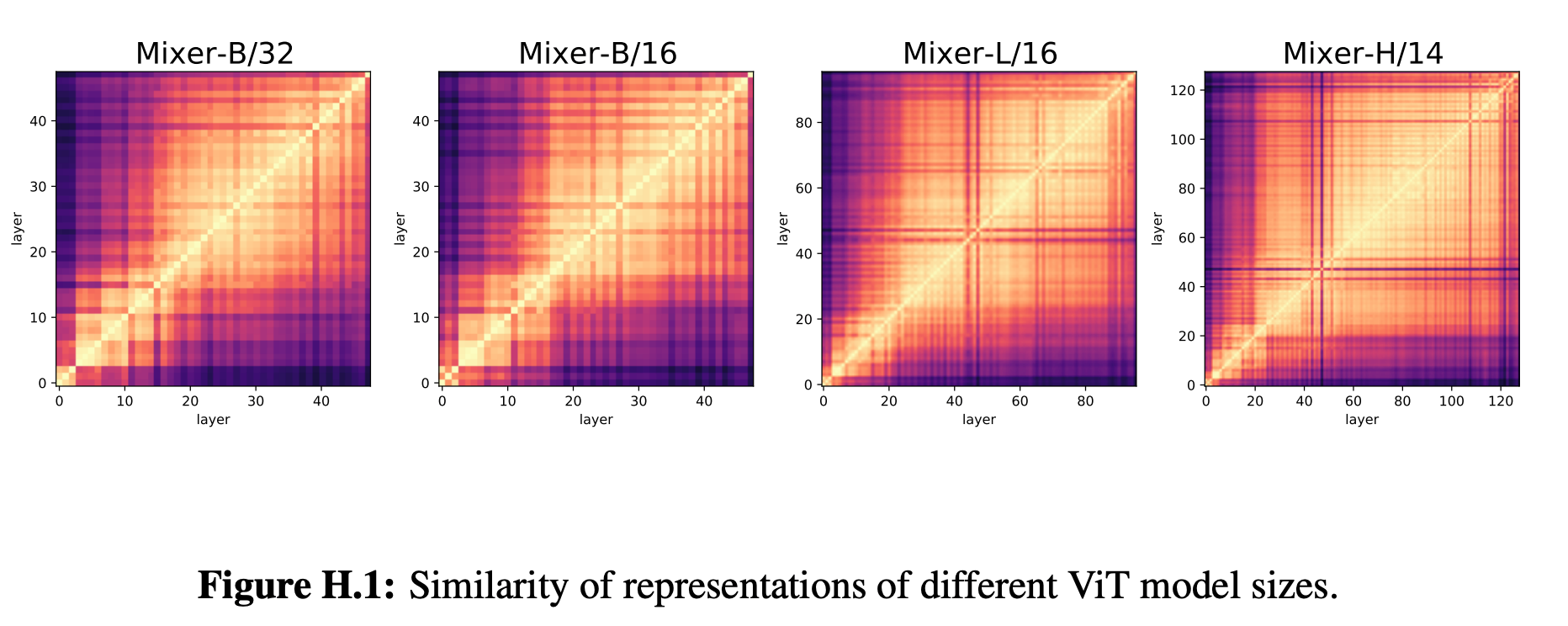
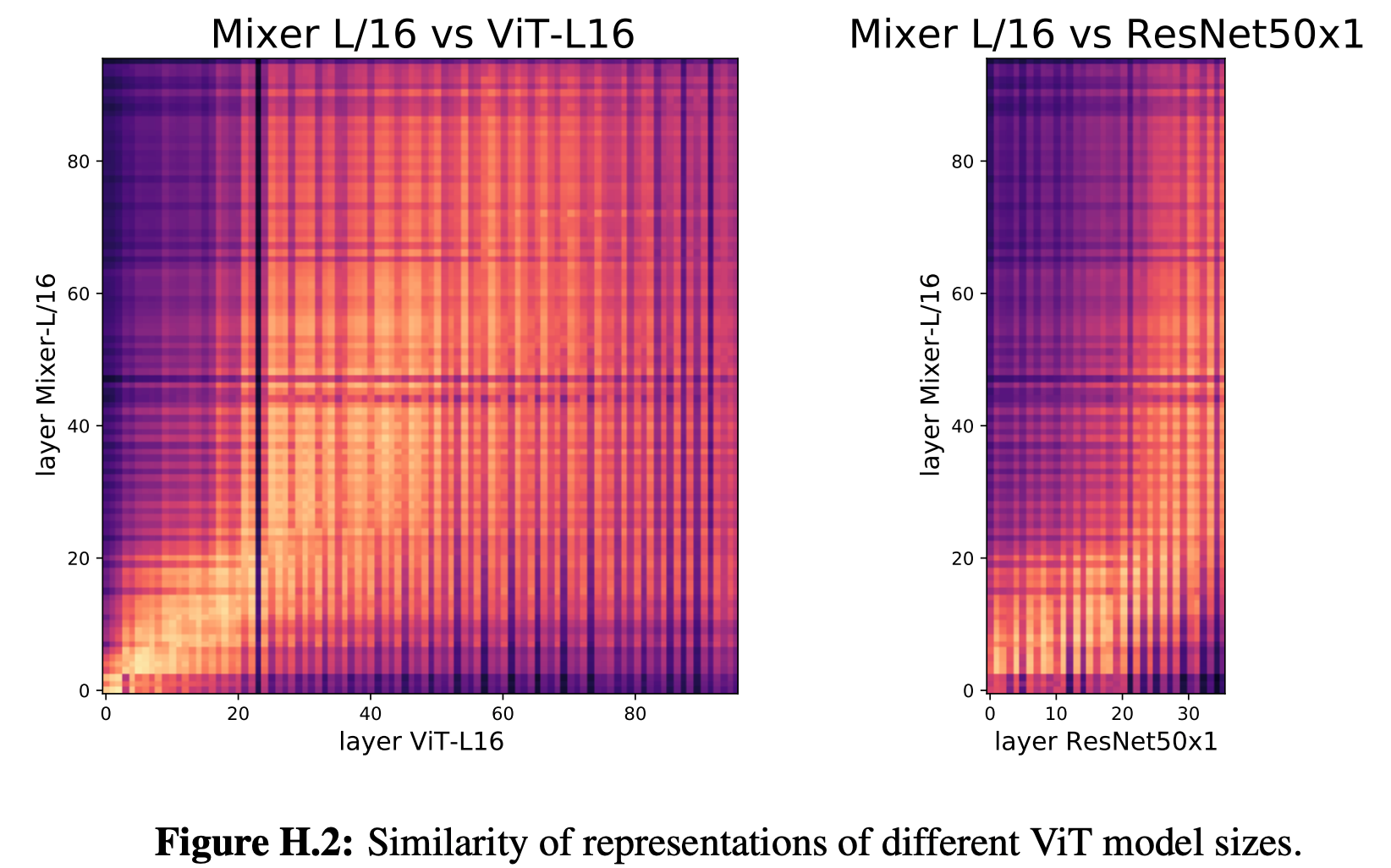
本論とそれるので詳細は割愛しますが、MLP1 でパッチ間の情報を混合し、次に MLP2 でパッチ内部で情報を混合し、それら2つを組み合わせたブロックを積み上げて伝播させていく仕組みです。この MLP-Mixer では、ViT と同等以上の精度に到達することができます。この MLP-Mixer の表現を、今までと同様の方法で比較したのが次の図です。この図を Figure 1 や Figure 2 と比較し、大まかな傾向としては ViT に近い、と著者らは述べています (ViT の表現の類似性が広がりよりは、MLP-Mixer の方が広がり方が小さい気がするので、私は「強いて言うならば」程度で捉えています)。
MLP-Mixer は、ViT のように画像をパッチで分割して伝播させていくため、構造的には ResNet より ViT に近くなります。こういった構造が原因でこのような結果が出てくるのかもしれません。
終わりに
本記事では、ViT と CNN の違いを詳細にみてきました。もう一度おさらいすると、両者には以下のような違いがあります。トランスフォーマー系は、今後もコンピュータービジョン分野で大きな影響力をもっていくと考えられます。この記事が、トランスフォーマーに対する理解の一助になれば幸いです。
- ViT は、CNN と比較すると、浅い層と深い層で取得される表現の類似性が高い
- ViT は、CNN と異なり、浅い層から大局的な表現を取得している。しかし、浅い層で取得される局所的な表現も重要である。
- ViT のスキップ接続は CNN (ResNet) よりもさらに影響力が強く、性能と表現の類似性に強い影響を与える。
- ViT は、ResNet と比較すると空間情報を保持している
- ViT は、大量のデータによって高品質な中間表現を学習できる
- MLP-Mixer の表現は、どちらかといえば ResNet よりも ViT に近い
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人