

ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
敵対的生成ネットワーク (Generative Adversarial Network; 以下 GAN) といえば、非常にリアルな人の顔や写真などを生成できる技術としてここ数年、深層学習技術の中でも特に注目が集まっており、ご存知の方も多いのではないでしょうか。2014年に提案されて以来、リアルな画像の生成だけではなく、セキュリティーへの応用や、音楽を生成したりと、GAN の応用は様々な分野に広がっています。一方で、有名人が実際には話していなことをあたかも話しているような「ディープフェイク」と呼ばれる動画を生成するなど、悪用も懸念されています。
Andrew Ng (アンドリュー・エン) 氏によって設立された Deeplearning.ai において、敵対的生成ネットワーク (GAN) の専攻コース が9月末にローンチされました。コースのローンチにあわせて、「GANs for Good」(社会のための GAN)と題されたバーチャルセミナー・パネルディスカッションが行われました。「GAN の生みの親」Ian Goodfellow 氏をはじめ、画像×AI の分野で著名なそうそうたるメンバーからの講演とパネルディスカッションがありました。以下では、抄訳とともに紹介したいと思います。
基調講演1 — GAN の生みの親 Ian Goodfellow 氏 (アップル)
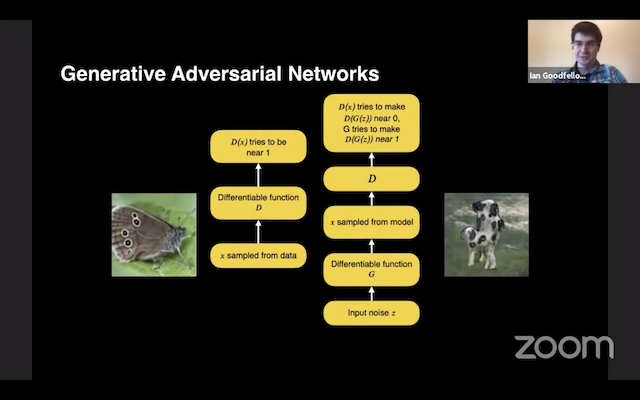
はじめに、GAN の動作原理を簡単におさらいしたいと思います。教師データを与えられ、そのデータの分布から新しいサンプルを生成するモデルを学習します。有名人の顔画像データセット (CelebA) から学習すると、この世には存在しない、あたかも有名人のような顔画像を生成できます。
GAN は、以下の2つのプレイヤーがナッシュ均衡を達成しようとするゲーム理論的な設定で学習されます。
- 識別器 D ... 本当の画像に高い確率、偽の画像に低い確率を付与するように学習
- 生成器 G ... 識別器が高い確率を付与するように画像を生成
一番最初に GAN が発表されてから 4年半が経ちます。当初は、白黒の低解像度の画像しか生成できなかったものが、その後、世界中の研究者や研究機関が改善を重ね、写真のようにリアルな、高解像度の画像を生成できるようになりました。また、ImageNet のような多様な種類の画像も生成できるようになりました。
GAN の医薬への応用に注目しています。GAN の技術を使い、患者個人個人にあった「歯のかぶせもの」を設計するというものです。従来は、設計・製造に2週間かかったものが、GAN と 3D印刷技術を組み合わせると1日で可能になります。
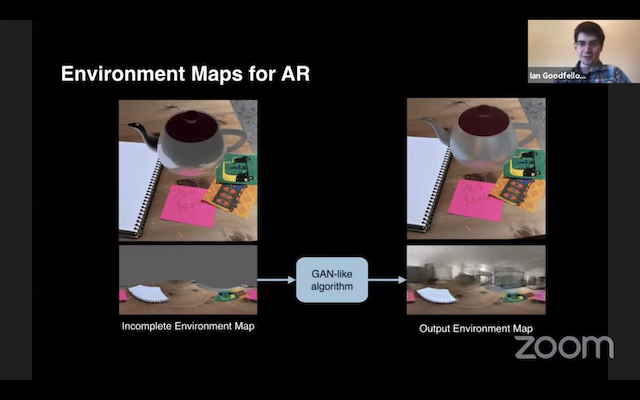
アップルでは、拡張現実 (AR) に GAN の技術を応用しています。実際の背景の中に物体を挿入した時、壁や天井など、カメラには写らないが環境に存在するものを「想像」し、それらを映りこませるというものです。
また、GAN を使って教師データを作るというアイデアもあります。一般的に、GAN を使って教師データを増やし、対象のタスク (例えば分類問題) の性能を上げるというのはうまくいきません。ただ、GAN を使って2つのデータセットを「合成」することはできます。
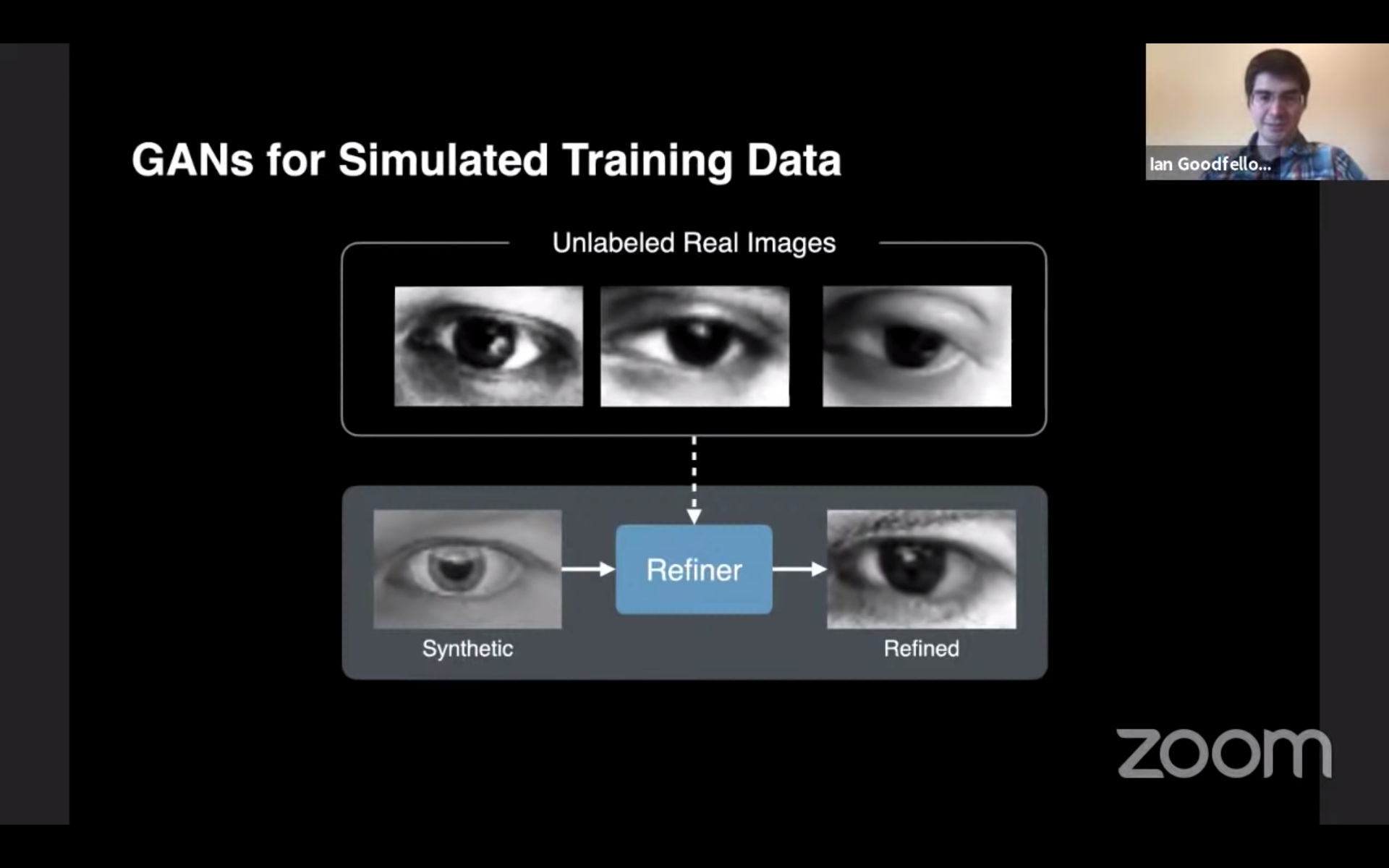
CVPR 2017 のベストペーパーを受賞した Shrivastava 氏らの論文 では、人工的に作られた(ラベルあり)画像と、自然な(ラベルなし)画像を合成し、視線推定のためのデータセットを「合成」しています。
また、アップルでは、iOS で使われている入力法である「QuickPath」の訓練データを作成するために、テキストと、ユーザーの入力軌跡のデータを GAN の技術を使って合成しました。学習に使ったデータ量と誤り率を両対数グラフ上にプロットすると、ほぼ直線上に並び、手法が有効であったことが分かります。
他にも、差分プライバシー (differential privacy) を使い、「偽の」医療情報を生成できるモデル (Beaulieu-Jones et al. 2018)や、公平性を考慮した GAN (Sattigeri et al. 2018)、アクセシビリティ、パーソナリゼーション (vue.ai) など、様々な応用に対して用いられています。
基調講演2 — Animashree Anandkumar 氏 (Nvidia)

識別器 D と 生成器 G がゲーム理論的に同時に最適化される GAN の訓練では、両者の相互作用を正しく理解することが重要です。
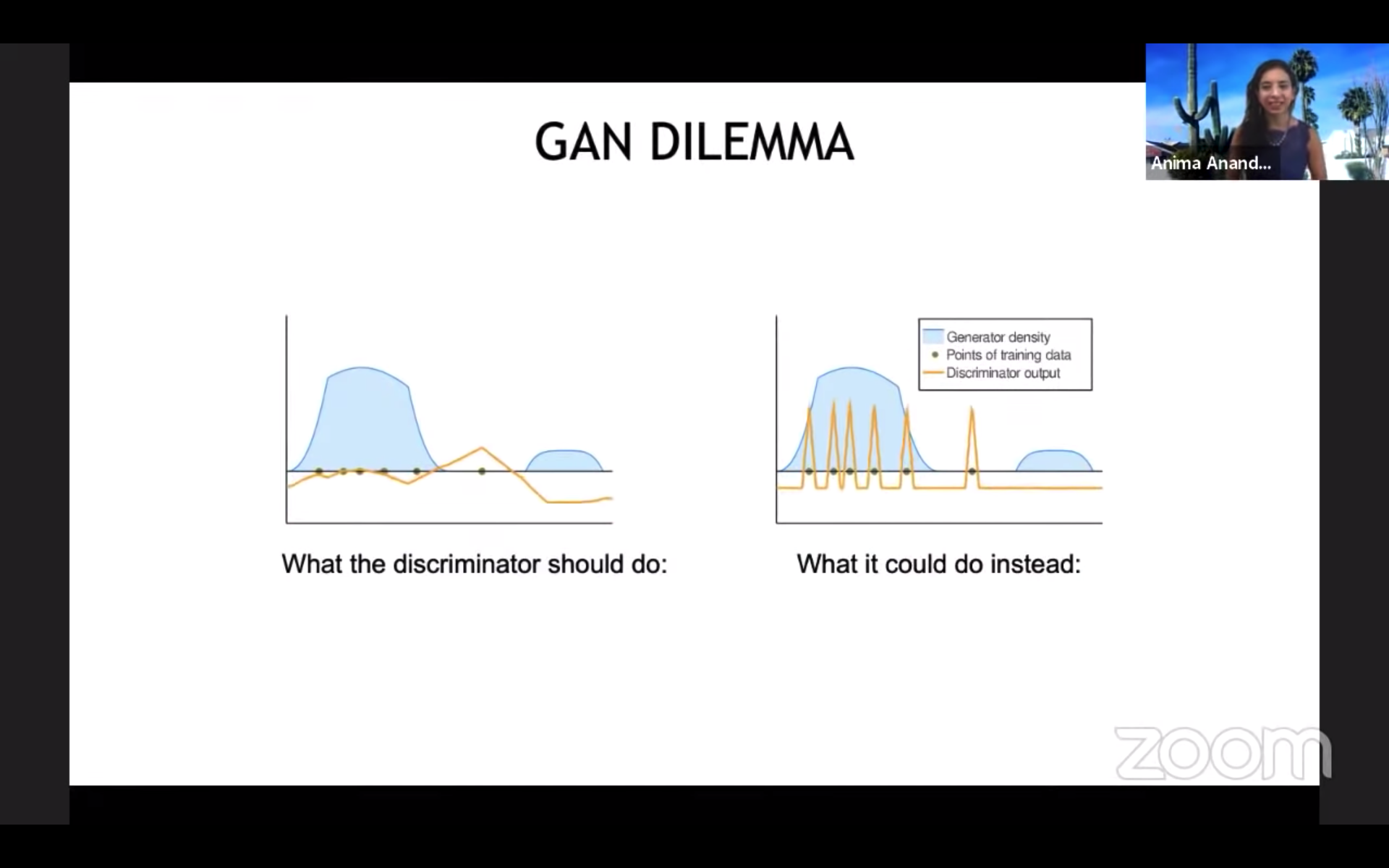
Schäfer 氏らの ICML 2020 の論文 では、GAN を訓練する際の「暗黙的な正則化」の役割を分析しています。識別器 D をひたすら最適化するだけでは、訓練データにある「本物」を単に丸暗記してしまいます (上右図)。そうならないのは、識別器 D と同時に生成器 G も訓練されるため、これが暗黙的かつ競争的な正規化の役割を果たしている、ということです。著者らは、この「相互作用」を強化するための項を最適化に導入しました。また、同様のアイデアは、GAN だけではなく、強化学習の枠組みを使い、エージェントを競争的に訓練させる場合にも有効だということです。

多数ある GAN モデルの中でも、高解像度・リアルな画像を生成できることでポピュラーな StyleGAN。スタイルを考慮した画像を生成できますが、例えば「口の開き方」「メガネの有無」などを完全に教師なしで学習、制御するのは難しいことが知られています。Nie 氏らの 2020年の論文 では、ラベル付きの少数の訓練データを使い、制御可能なスタイルを「分解」して学習できる手法を提案しています。また、このためにスタイルを再構築する損失関数を使っています。
パネルディスカッション
続いて、以下の五名によるパネルディスカッションが行われました。
- Animashree Anandkumar, Nvidia 機械学習研究ディレクター
- Alexei Efros, UC バークレー 教授
- Ian Goodfellow, アップル 機械学習ディレクター
- Andrew Ng, Deeplearning.ai 創業者
- Sharon Zhou, スタンフォード、GAN 専攻コース講師
Efros 氏: 論文に「恋に落ちる」ことはあまりないのですが、自分は GAN の大ファンです。
Ng 氏: GAN は最初に提案された時はうまく行かないことも多かったのですが、その後 Nvidia など世界中の研究者の貢献で発展しました。綺麗な写真を生成するだけでなく、実世界の多くの役に立つ応用で使われています。
質問: 最近の研究活動について教えてください。
Efros 氏: Goodfellow 氏が紹介してくれたように、Glidewell Dental Labs との共同研究で 「歯のかぶせもの」を設計する GAN を発表しました。
また、Anandkumar 氏の発表にもあったように、分解を教師なしで達成する手法も研究しています。一つの例として、CycleGAN の「循環性」を対照学習 (contrastive learning) の枠組みで達成する手法を ECCV 2020 で発表しました (Park et al. 2020)。また、入れ替え自己復号器 (swapping autoencoder) という手法を NeurIPS 2020 で発表します (Park et al. 2020)。
これまで自己学習に長く取り組んできました。個人的に「ラベル」が好きではないので、なるべく使わないようにしています。また、「固定のデータセット」というのも好きではありません。ストリーミング形式のデータにテスト時に適用する継続学習の手法の論文も発表しました。
GAN は、例えば StyleGAN を適用したというだけでも、既にスタイルの「分解」をかなり達成しています。これも、今後発展が期待される方向です。
GAN の訓練には、いまだに専門家が必要
質問: 注目しているトレンドは?
Ng 氏: 多くの深層学習の技術は、実験室で一つのタスクでうまく行ったのをきっかけに、ドミノのように多くの面白い応用に適用され始めます。10〜12年前、教師あり深層学習は、はじめに音声認識の分野で成功を収めたのをきっかけに、画像認識、続いて、自然言語処理の分野に次々と応用されてきました。GAN は、このパターンに合致しているように思われます。今、GAN が様々な実世界の有用なアプリケーションに応用されはじめているのに注目しています。人工知能の分野では、研究からプロダクションのギャップを埋めるのに大きな課題があります。実世界に応用する際に、モード崩壊が起きないかどうか、訓練はうまくいくかどうかなど、解決しなければらなないステップがたくさんあります。専門家だけではなく、産業界の多くの人がシステマティックに使えるようにする必要があります。
また、クリエイティブ分野への応用も楽しみです。「Photoshop 2.0」的な画像を操作する応用です。そのためには、多くの人が、アルゴリズムがどう動くかを理解できるようにする必要があります。
質問: GAN をビジネスに応用するにあたってのチャレンジは?
Anandkumar 氏: Nvidia では、GAN を使ってチューリング・テストにも通るようなリアルな画像を生成する技術を追求しています。リアルな風景を簡単に生成できる GauGANは、100万ダウンロードを達成しました。
アカデミックでは、より分野を跨いだ研究に注目しています。脳に生成モデルはあるか?などの課題を神経科学の研究者と追求しています。人間が知覚をする時、単に入力を受け取るだけではなく、自分の頭にある「表現」を使って補間し、絶えずフィードバックを受け取っています。このようなフィードバック機構を通常の順伝播型ニューラルネットワークにどう取り入れるか、という研究です。モデルをロバストにするというのは、現実の問題に適用する際に重要です。
質問: GAN の社会的応用についてもう少し。
Goodfellow 氏: 差分プライバシー (differential privacy) とは、訓練データの個別のサンプルに特有のパターンを記憶することなく、機械学習モデルを訓練する手法です。GAN に適用すると、訓練に使ったデータの情報を明らかにすることなく、新たなデータを生成できます。医療分野に適用すると、新たな「偽の」医療情報を無限に生成し、公開することができます。他にも、話者が少ない言語のデータを生成することによってサポートしたり、vue.ai のように、自分が服を試着した画像を生成したりといったことができます。これらはまだ一例で、表面をなぞったにすぎません。
今の GAN の状況は、2012年当時の深層学習の状況に似ています。当時は、高度な知識を持った専門家しか、深層学習モデルを訓練できませんでした。今の GAN もそのような状態です。今では、新たなアーキテクチャや最適化手法の開発により、ずっと信頼性高く深層学習モデルを訓練できるようになりました。今後、専門的な知識を持たなくても、GAN を使って応用できるようになる技術の開発に期待しています。
Ng 氏: GAN を精度を正しく評価できる評価手法が無いというのも問題です。これも、GAN に専門家が必要な理由の一つです。
Zhou 氏: 下流の人工知能モデルにどのぐらい貢献できるか。人間を巻き込むことも大切です。
Anandkumar 氏: GAN を「大衆化」するといえば、最近、画像・動画生成モデルを統一的に扱える Imaginaire というオープンソース・ソフトウェアを Nvidia からリリースしました。
「知識は3ヶ月で陳腐化する」人工知能の進歩についていくには?
質問: GAN の研究・開発に携わる・入門する人へのアドバイスは?
Efros 氏: 研究をするためには、少し「クレイジー」であることが重要です。想像力を働かせ、短期的に論文を採録させることだけにフォーカスしないこと。自分が本当にしたいことを持ってそこに向かうこと。arXiv から湯水の如く出てくる論文を気にしすぎないこと。
医学の分野では、医学部から卒業する時に、「これまで学んだことの半分は、5年で無駄になる」と言われます。これが、科学の進歩による「知識の半減期」です。機械学習や GAN の分野では、この半減期はおそらく3ヶ月程度でしょう。
論文・手法・モデルなど、発表されるものをいちいち気にしすぎないこと。もし論文に顔の写真しか載ってなければ、私は読みません。顔は比較的簡単な対象であることが分かっています。数年間待ってみて、時の試練に合格するかを見てみると良いでしょう。もしあなたに良いアイデアがあるなら、それをとにかくやってみてください。きっと成果になります。
質問: 人工知能の分野に興味のある女性に対するメッセージは?
Anandkumar 氏: 分野に対する注目が高まっているので、より多様性・包容性が高まると良いと思います。分野全体としては、女性などに非常に支援的です。社会的、技術的問題があれば、すぐには変化は現れないかもしれませんが、サポートを見つけ、立ち向かってください。
質問: 時間を管理し、人工知能の進歩についていくためのアドバイスは?
Ng 氏: Deeplearning.ai が発行している The Batchでは、人工知能に関するニュースを配信しています。今週は「GAN スペシャル号」で、ここから私個人として学ぶことも多いです。論文について語ったりできる友人・知人を持つことも大切でしょう。
Goodfellow 氏: アップルでは、「論文パーティー」と呼ばれる、論文の読み会を週一回開催しています。私個人的には、あまり論文を読みません。人づてに聞いて分野の進歩を知ったりすることの方が多いです。
Anandkumar 氏: 異なる分野の人々が参加する論文の読み会では、多様なトピックが議論されて良いですよね。私もあまり論文は読みませんし、学生にも、arXiv に上がっているだけの論文を読むのはおすすめしていません。まず自分でアイデアや問題を考え、他の人が同じようなアイデアを発表してないかチェックします。もし他の人が同じようなアイデアを発表していても、それは自分のアイデアが正しかったということなので、良いことです。
Efros 氏: 私も論文はあまり読みませんし、学生が有望なアイデアを教えてくれます。「時間」をフィルタとして使い、古い論文を読むようにすると良いです。
GAN の「芸術」への応用
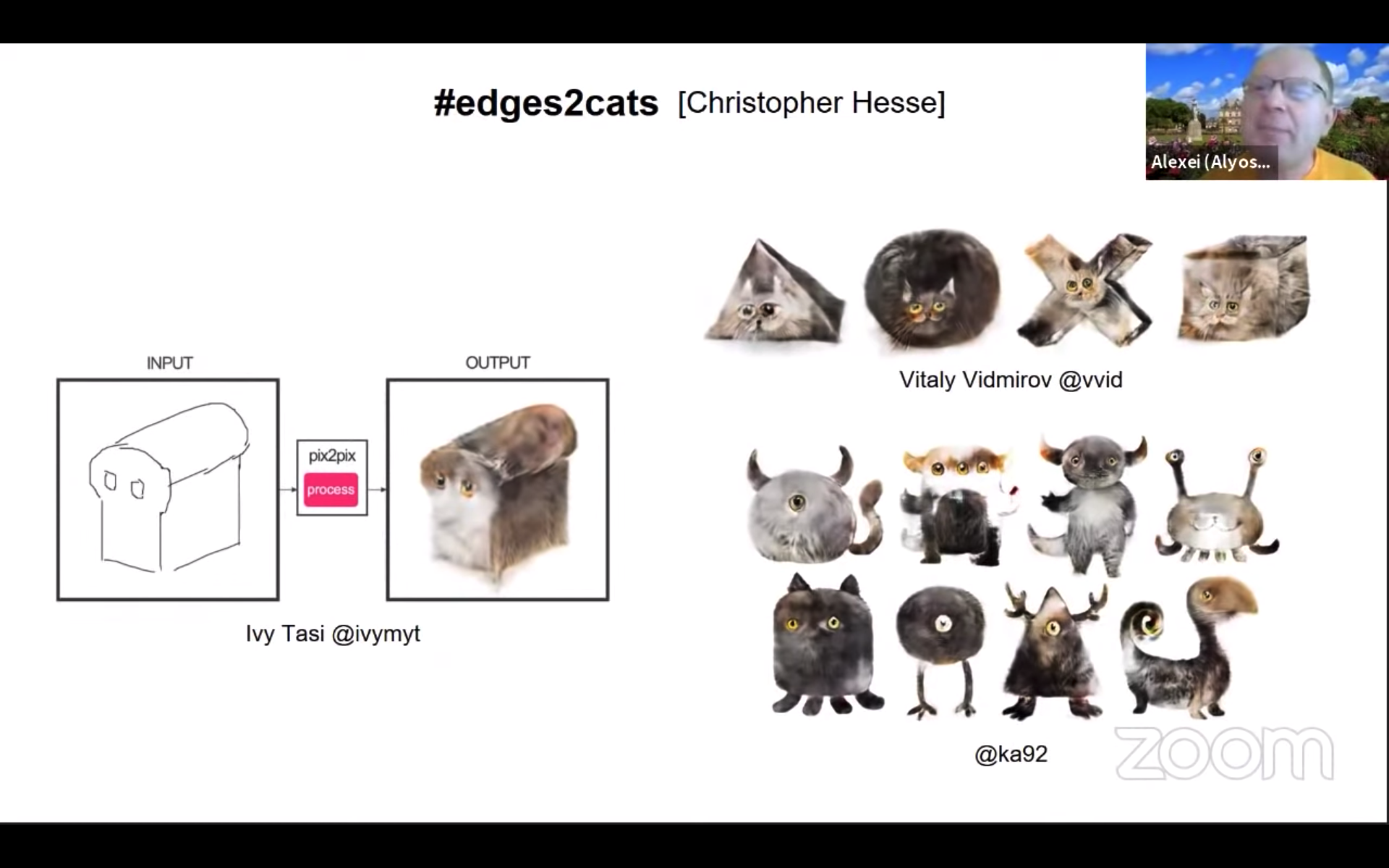
Efros 氏: 私たちが pix2pix のコードを公開してからすぐに、edges2cats という、線画からネコの画像を生成するアプリが開発されました。これが世に出ると、我々が想像もしなかったような作品が次々と生み出されました。数多くのアーティストが、GAN を芸術作品の作成に使い始めたのです。まるで、新しい「ブラシ」を手にいれたようです。
Joel Simon 氏は、GAN の潜在空間を使うことによってアートを融合させることのできる Artbreeder というサイトを開発しています。アーティストのコミュニティが、この GAN という新しい技術に乗り、我々技術者が想像もしなかったことを生み出しているのは、素晴らしいことです。
GAN を画像生成ばかりに使わない
質問: 分野の初心者に対するアドバイスは?
Ng 氏: 最初に CycleGAN の論文を見た時、「馬をシマウマの画像にしたい人がどのぐらい居るのだろう」と思いました。しかし、今週、CycleGAN のアイデアを使い、CT 画像を相互変換する論文が発表されました。
GAN に入門するのは、今が良いタイミングだと思います。芸術・医療など、我々が思いもしなかったものに応用される余地がたくさんあります。Efros 氏の言うように、自分のアイデア、夢を追い求めるのを期待しています。
Anandkumar 氏: 基礎を大切にしてください。GAN はゲーム理論に基づいていますが、そこで重要な概念を理解することは、より複雑な GAN のモデルを訓練するのに役立ちます。
Goodfellow 氏: 研究にしろ、開発にしろ、皆と違うことをどうやってするかを考えるべきです。明らかなことを追ってばかりいると、アイデアで先を越されてしまいます。人に先を越されない一つの方法は、GAN を画像ばかりに適用するのをやめることです。産業デザインや医薬など、画像以外の分野への応用を考えることです。そちらは、ずっとブルーオーシャンで、あなたのキャリアを考えた時、より大きな「利息」を生み出すでしょう。
Efros 氏: 一点、CycleGAN などを医療の分野に適用することには注意すべきです。GAN は、基本的に「幻覚」を生み出す技術です。単に、馬をシマウマに変換するだけではありません。人の命がかかっているんです。
研究者になりたいのなら、自分がやっていることを楽しむことが大切です。研究をするということは大変です。自分が好きなことではないと続きません。
Goodfellow 氏: (医療について)だからこそ、医療の専門家と機械学習の専門家が協業することが大切なのです。
Anandkumar 氏: 協業する場合、「パッケージを作って引き継ぎ」ではなく、密に連携することが大切です。まず、いきなり GAN から始めないこと。まず単純な教師ありの設定から始め、精度を見る。多様性を考慮すること。
質問: NLP への GAN の応用は?
Goodfellow 氏: NLP は、GAN を応用するのが難しい分野の一つです。空欄を埋めるようにテキストを生成する MaskGAN という手法があります。しかし、その後、同じ著者の一人が、GAN は最尤推定法と比べて優れているとは言えないという旨の研究 (Caccia et al. 2018) を発表。今、主流のテキスト生成モデルと比べて、GAN は NLP への適用が難しいというのが現状です。
(萩原注:このあたりの文献については、以前の記事でも言及しました)
質問: ニューラルスタイル変換について、オリジナルの手法と GAN との違いは?
Efros 氏: コンピューター科学者の考えるアルゴリズムと、アーティストの芸術への応用は別に考えると良いでしょう。アーティストにとって、どのような技術が使われているかは重要ではありません。それを使って何をするかです。オリジナルのニューラルスタイル変換の手法そのものは「芸術」ではありません。研究者は「ブラシ」という道具を提供できますが、実際に作るのはアーティストです。
質問: ビデオや 3D データへの GAN の応用は?
Anandkumar 氏: データ、計算資源、アルゴリズムの「三位一体」全てが揃い始め、今は非常に面白い時代です。また、Nvidia DLSS (ディープラーニング スーパー サンプリング) に代表されるように、グラフィックスと人工知能の融合も始まっています。効率的なレンダリング、マルチモーダルなデータの処理なども取り組んでいます。単にリアルに、高速に画像を生成するだけでなく、新たな形・概念を生成するということが次の領域です。
質問: 「ディープフェイク」などに代表される、倫理面での問題は?
An 氏: 多くの人工知能技術が、良いことにも使えば、悪い目的にも使えます。社会の皆が、応用が社会のためになるかどうかをチェックするべきです。企業などの団体が、倫理委員会などを設立するという流れは普及していません。個別のエンジニアが、問題に対して声を上げられるようにするべきです。私自身も、世界をより良くしないプロジェクトをいくつか中止したことがあります。技術は非常に強力なので、倫理面を心配するのは他人任せにするのではなく、我々皆が考えるべきことです。
おわりに
以前の記事でも紹介しましたが、単に「リアルな画像生成器」であった GAN は、「損失関数をデータから学ぶ汎用的な枠組み」として、画像生成以外にも様々な分野で使われるようになりました。パネリストからも話があったように、今後の「画像以外」への応用も楽しみです。
なお、「NLP は、GAN を応用するのが難しい分野」という話がありましたが、「敵対的損失関数を使った最適化」という手法は、NLP の様々な手法において使われはじめています。人工知能の各分野は、このように、有望な手法を他の分野から借りて発展するということが良くあります。他分野の手法を追ってみると、これまでになかった良い発想が得られるかもしれませんね。
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人