

Andrew Ng (アンドリュー・エン) 氏によって設立された Deeplearning.ai では、質の高いオンラインコースなどを提供しており、ご存知の方も多いのではないでしょうか。
今年の7月に、自然言語処理の専攻コースが新たにローンチされました。ローンチに伴って、自然言語処理分野の著名な研究者によるバーチャル・セミナーが開催され、「自然言語処理へ飛び込む (Break into NLP)」というタイトルで講演・パネルディスカッションが行われました。自然言語処理の分野に興味のある方に有用なアドバイスが数多くありましたので、ここで抄訳とともに紹介したいと思います。
基調講演1
(はじめに、Google Brain のサイエンティストである Łukasz Kaiser 氏の基調講演がありました。Kaiser 氏は、TensorFlow の共同開発者、トランスフォーマーの論文の共著者としても有名です。)
2014年に深層学習が普及し始めた当初、NLP コミュニティでは、深層学習に懐疑的な人が多いという状況でした。
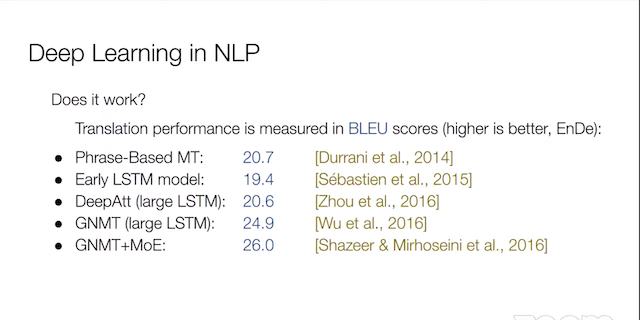
当時、最も性能の高い手法は依然として統計的手法だったからです。例えば、機械翻訳の分野では、BLEU と呼ばれるスコアで翻訳の性能を測定しますが、2014年ごろは、統計的機械翻訳の BLEU スコアが一番高かったのです。その後、深層学習ベースの機械翻訳システムが徐々に開発されてきました。深層学習ベースのシステムは、大きくすればするほど良くなるということが分かっています。2016年ごろ、Google が LSTM ベースの大きなモデルを発表し、統計的システムの性能を超え始めました。ただ、巨大なモデルなため、Google の計算インフラなしでは再現不能という問題がありました。
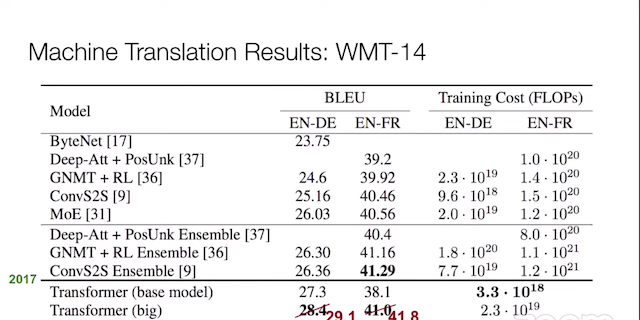
この頃、主に使われた技術である RNN (LSTM) は遅く、長い系列が不得意であるという問題があります。この問題に対処するために、2017年にトランスフォーマーが登場。RNN の「繰り返し」を不要にしてしまいました。BLEU スコアで 30 を達成し、人間の翻訳者に匹敵するほどの性能を上げはじめたのです。トランスフォーマーでは、注意機構で全てを処理します。その後、翻訳だけではなく、たとえばテキスト生成など、他のタスクにも応用されはじめました。
今後の自然言語処理のトレンドとしては、1) 長い系列の処理、2) より強力な推論能力、3) 少数ショット学習、4) より幅広いユースケース(生成、プログラミング言語、etc.)などが挙げられるでしょう。
基調講演2
(次に、Andrew Ng (Deeplearning.ai, Landing.ai の創業者) の基調講演がありました。)
現在、人工知能、機械学習、深層学習の普及が、専門化を後押ししています。自然言語処理、コンピューター・ビジョン、音声処理、構造化データなど、様々な応用分野に適用されています
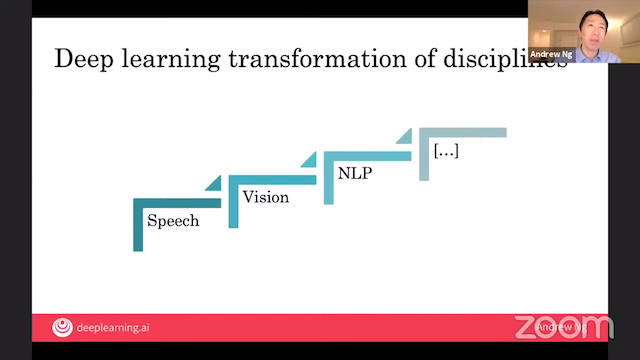
2010年ごろ、深層学習が一番はじめに大きなインパクトを与えたのは音声認識の分野でした。その頃、Ng 氏は Google Brain チームを率いていましたが、その成果は、スマートスピーカー、音声サーチ、などに大きな貢献を果たしました。
次の波は2012年ごろ、 コンピューター・ビジョンの分野に訪れました (例: AlexNet)。この技術は、自動運転、運転者支援、顔認識など、幅広い分野で使われています。
「深層学習の波」は、自然言語処理へは少し遅れて到達しました。他の分野と同様に、「機械学習化」の波が押し寄せると、伝統的にその分野に関わっていた人々からは「これまでの特徴量エンジニアリングの蓄積が無駄になる」という反発・葛藤がありました。この移行には、しばらく時間がかかりました。そのため、自然言語処理は、まだ「手つかずの機会」があると思います。

自然言語処理の業界は、今、非常に勢いがあります。業界規模、論文数などは指数関数的に増えています。また、NLP の応用は、皆が意識することなく一日に何度も使っていると思います。Web 検索、要約、自動補間、スパムフィルタ、機械翻訳、音声アシスタントなどです。私 (Ng 氏) が将来の応用として期待しているのは、教育応用、電子メール、論文の分析、ロボティック・プロセス・オートメーション(RPA)などです。
他に、自己学習 (self-supervised learning) にも、非常に期待しています。これは、大量の教師なしデータからモデルを学習し、その後、他の教師ありタスクに転移させるというアイデアです。人間の子供はほぼ教師なしデータから学習します。この自己学習は、トランスフォーマー、BERT、GPT など、NLP の分野で多大な成果を挙げています。また、以前は、Google などの大企業しか手が出なかったモデル・訓練が現在は個人でも試せる時代になりました。
パネルディスカッション
(続いて、以下の五名によるパネルディスカッションが行われました。)
- Kenneth Church 氏: バイドゥー USA、 Distinguished Scientist
- Marti Hearst 氏: カリフォルニア大学バークレー校 教授
- Łukasz Kaiser 氏: Google Brain サイエンティスト
- Younes Mourri 氏: スタンフォード大 AI 講師
- Andrew Ng 氏: deeplearning.ai 創業者
質問: AI や NLP の分野に入門する学生にどのようなアドバイスを贈る?
Hearst 氏: 「なぜ」この分野に入門したいかを考える良いです。「皆がしているから」は良い理由ではありません。今では、オンラインコースで「お試し」できるので、自分の興味に合っているかどうかが簡単に試せます。自分が NLP に入った理由は、言語、コンピューターとどうやってインタラクトするか、に興味があったから。
自然言語処理には、言語学的側面と、機械学習的側面があります。機械学習から入ってきた人も、言語(言語学)のことを勉強すれば良いです。学際的な分野ですし、世界にインパクトを与える応用があります。
質問: ここ数十年の間に、分野はどのように変わってきたか?
Church 氏: 自分がこの分野に入ったころは、例えばシャノンの情報理論の全盛期の頃。分布仮説 (distributional hypothesis) などもその時生まれました。MIT では、チョムスキー氏やミンスキー氏と働く機会がありました。
1990年以前は、統計を使った論文はほとんどありませんでした。今では、統計的手法を使わない論文を見つける方が難しいでしょう。おおよそ 20年ごとに流行りの波が来ます。その後、「揺り戻し」が起きます。ただ、流行は流行り廃りがありますが、例えばニューラルネットのような重要なコンセプトは常にそこにありました。Hinton 氏と LeCun 氏は、ニューラルネットが廃った時期も、常にアイデアを追求し続けていました。自然言語処理では、Salton 氏のベクトル空間モデルが良い例です。
50〜90年代のように、自然言語処理研究の商業的なインパクトがすぐに出ない時代がありました。データの入手も容易ではありませんでした。今ではすぐに目に見える商業的なインパクトが大きいというのも大きな違いでしょう。
Kaiser 氏: トランスフォーマーが提案される前には、RNN が「全て」でした。系列を順に処理するというアイデアは直感的ですが、遅いという問題がありました。トランスフォーマーで使われている注意機構は、実はアラインメントという古い概念から来ています。アラインメントの微分可能なバージョンです。注意機構は、うまくいき、かつ速いという利点があり、NLP の問題設定によく合っていました。今では、トランスフォーマーを RNN として理解できる という論文も出されるなど、RNN の揺り戻しが起きています。このように、古い概念を学習・理解することは大切です。
Mourri 氏: 私はモロッコ出身です。昔は、機械学習の学習の資源に恵まれていませんでした。2014年に米国に来た後、講義メモを書いて公開したり、数学・CS・統計などを勉強し、宿題を解いたりして業界に入門し、スタンフォードで教えはじめました。
宿題を作る側の悩みとしては、宿題やコースを作っている間に、分野が進歩してしまうことです。
Ng 氏: 昔に比べ、業界のサイズ、社会的なインパクトがずっと大きくなりました。AI はブラックボックスであり、懐疑的な人も居ます。この問題については、Microsoftの研究者による、埋め込みに対するバイアスの論文 など、バイアスを同定し、除去する研究も出てきています。
業界に入門する時には、流行の波、テクノロジーのタイミングを見極めるのが大事です。例えば「ヘリコプターを発明したのは誰か?」と聞かれれば、ダ・ビンチだと答える人が多いかもしれません。彼は設計こそしましたが、その設計はエンジンなしには動きませんでした。スマートフォンも同じでしょう。初期スマートフォンである アップル・ニュートン は商業的には失敗しましたが、その後十数年後に発売された iPhone が成功を収めたのは、皆さんご存知の通りです。
30年前、深層学習を実応用に適用するのはあまり良いアイデアではありませんでした。自然言語処理に入門するタイミングとしては、今が良いと思います。社会には、AI の力を借りて爆発的に成長しそうな分野がいくつも眠っており、そのようなシグナルを見つけることが大事です。NLP はこのパターンに当てはまっています。
Hearst 氏: タイミングの問題について言えば、あきらかにうまくいかないのに、なぜか人を引きつける技術もあるので注意が必要です。人があまり興味をもたない分野、個人的に直したい問題があるかどうかで分野・プロジェクトを選んだほうが良いでしょう。その場合、最初は、世間にすぐに受け入れられないということを覚悟したほうが良いです。
Church 氏: 「いつ分野に参入すべきか」という問題は、株式投資に似ています。安く買って高く売るのが理想ですが、現状、皆が同じボールを追いかけるという子供のサッカーのようになってしまっています。皆が入門したがっている時に入るのはおすすめしません。
Kaiser 氏: インターネットのせいで、皆が深層学習で自然言語処理をしているように「見える」のですが、今行われているのは、まだ表面をなぞっただけです。言語は非常に深い分野です。GPT-3 のように、リアルに見えるテキストを生成できるが、本当に「意味」を持つかどうか。今、GPT-3 のように、これまでとは違うパラダイムで動くモデルが出はじめています。今後、こういったモデルがすぐに使えるようになります。
Hearst 氏: 言語モデルが全てを解決するような印象を持っている人が多いでしょうが、実際はそうではありません。まだどうやって機械とコミュニケーションするかについては全然分かっていません。「言語理解」という言葉とは逆に、機械は言葉を「理解」していません。
Church 氏: この分野には多くの興味深い未解決の問題があります。個人的には、ベンチマークが目的と乖離し、独り歩きしている点を懸念しており、最近、意見論文を発表しました。目的と乖離したベンチマークにおける本質的ではない進歩で時間を浪費しています。
Ng 氏: 競技プログラミングや機械学習コンペなどでは、目的と乖離したベンチマークを競うことがありますが、これ自体は問題ないと思います。例えば、できたばかりの AI チームの学習のためのマイルストーンとしては使えます。もちろん、そこで終わってしまってはだめですが。
質問: GPT-3 の登場で、他のものがすべて無意味になってしまうと思うか?
Kaiser 氏: GPT は、単なる大きなトランスフォーマー。Web 全体で訓練されているので、高い汎用能力を発揮するのはそこまで驚きではありません。問題は、この出力をどう使うか、自分のタスクをどう解くか、ということです。正規表現、前処理、後処理など必要になってきますし、なぜこのモデルがこういう出力を出すかを理解する必要があります。
質問: 認知科学や、 神経科学との関係は?
Hearst 氏: 初期には NLP に大きな影響を与えました。McClelland 氏と Rumelhart 氏の古典的な本では、認知モデル、言語、思考などが議論されているので、そういったことに興味があれば読んでみるのが良いと思います。
Ng 氏: ニューラルネットは、当初、神経科学に着想を得て開発されました。自分も、昔は着想を得るために 神経科学の論文を数多く読みました。今では、ニューラルネットは独自の進化を遂げており、工学・コンピューター科学の影響が大きくなっています。
質問: トランスフォーマーは色々なスタイルに適用できるか?
Church 氏: トランスフォーマーを使ったスタイル変換などは、既に arXiv に論文があるはずです。ただ、トランスフォーマーの栄華が10年続くとは限りません。このことは、LSTM が証明しています。
未解決な問題として、長い距離の依存関係がありません。Chomsky は、長い依存関係を扱えないので、N-gram を批判していた。今のモデルでは、文レベルの依存関係なら可能だが、例えば本レベルの依存関係は未だに扱えません。
1962年、DARPA は「頑健性」が重要な問題であるとしました。今の機械学習は、平均的なケースを想定していますが、最悪のケースはあまり語られません。「できないこと」をあまり心配していないのです。トランスフォーマーでできないことは数多くあります。
Kaiser 氏: トランスフォーマーは1つのステップです。ちなみに、今年、本のレベルで長い依存関係を扱えるモデル (Reformer) を発表しました。
質問: ある分野を深く追求するか、それとも、浅く広く学ぶべきか?
Hearst 氏: 論文の数が指数関数的に増えており、分野が変わってきています。業界の皆が試行錯誤中で、研究をフルタイムでやっている PhD 学生であっても、業界の進歩に追いついていけないレベルです。ついていけている人は、自分の分野にフォーカスして、解の部分集合にフォーカスしています。
まず、言語学・機械学習、プログラミングなど、基礎を固めるのが大事です。まず幅広く、かつ複数の分野において理解を深めるという T 型の学習をするのが良いでしょう。
おわりに
私 (萩原) も、Church 氏の言う「「いつ分野に参入すべきか」という問題は、株式投資に似ています」という意見に同意します。分野で成果を出している人は、本当にその分野や問題に興味があって、流行がやってくる前からやってきた人が多いように思えます。「皆がやっているから」というのが良い理由ではないのは、株式投資に起こるバブルを見てみれば分かりますね。
私はこの分野に関わってほぼ20年ほどになりますが、「本質的な問題」というのは昔から驚くほど変わっていません。言語の構造をどう表現するか?どのように常識を学習させるか?そもそも言語を理解するとはどういうことか?など、今でも解けているとは言い難い問題が数多くあります。機械学習の手法など、流行り廃りは時代によって変わりますが、特に研究職を目指す、分野に長く関わるのであれば、自分が本当に興味のある問題を突き詰めていくのが良いように思えます。
一方、今が自然言語処理に「入門しやすい」時期であるという点についても同意します。伝統的な機械学習から深層学習への「波」は一巡した感がありますし、今ではトランスフォーマーや BERT、そのオープンソースの実装なども出揃って、急速に実世界への応用が進んでいます。そういう意味で、手持ちの問題に適用して成果を出す、というのが非常にやりやすい環境が整いつつあります。
興味があれば、セミナー内で紹介されている自然言語処理の専攻コースをチェックしてみるのが良いかもしれませんね。
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人