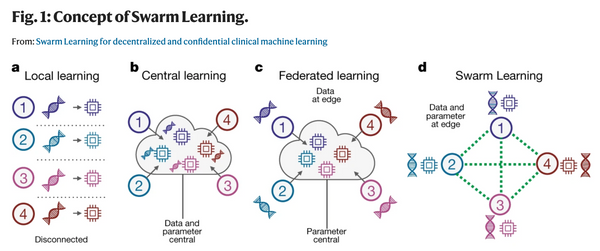
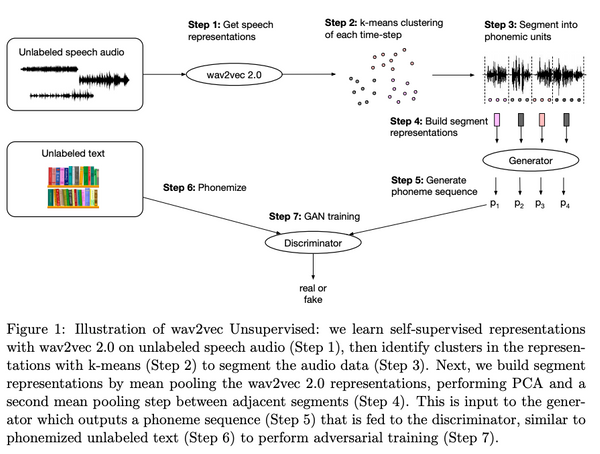
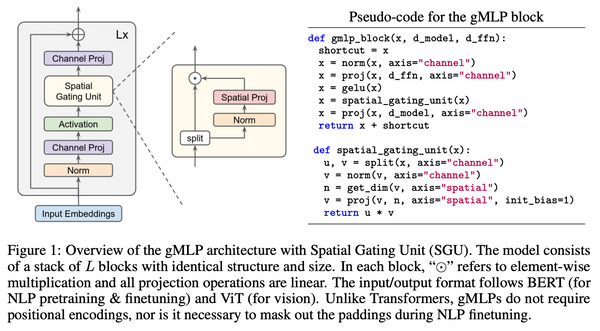
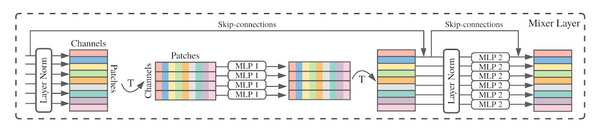
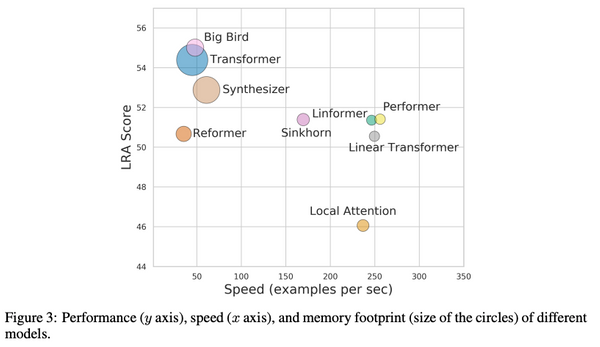
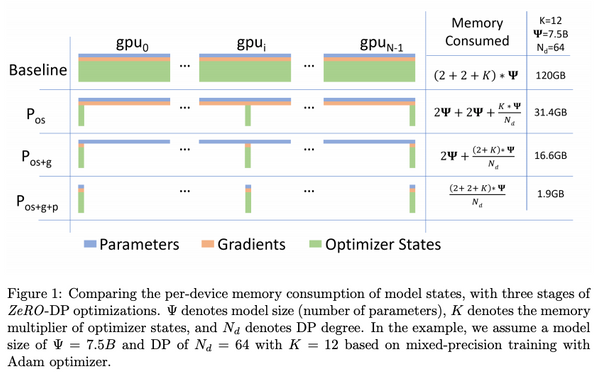
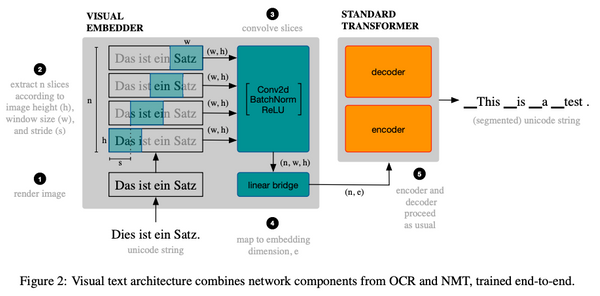
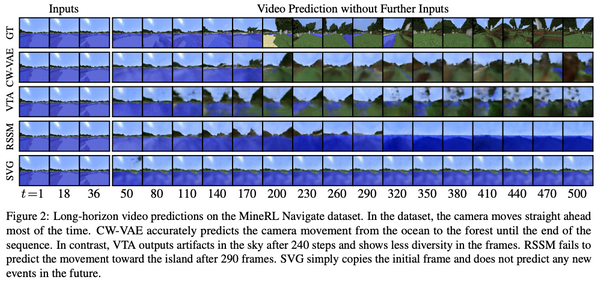
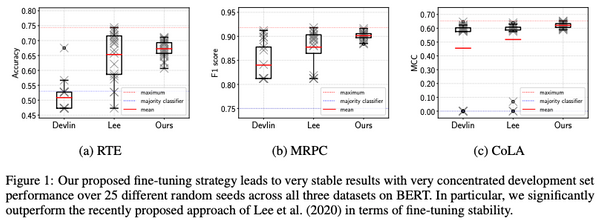
現代の機械学習においては、大規模なデータセンターの計算資源を大量に使い大規模なモデルを中央集権的に訓練するという方法が主流になっています。しかし、この方法では、計算資源や予算を潤沢に持った一部の大企業などでしか強力なモデルを訓練できないという問題があります。また、訓練データもサーバーに集約しなければならないため、プライバシーの問題もあります。これらの問題に対処するために、最近になって、中央集権的なサーバーを持たずにモデルを訓練する手法がいくつか出現し始めました。本記事ではその中でも特に最近になって提案された「群体学習」と「DeDLOC」について、関連手法をおさらいしながら解説します。