
ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
元論文: Salesky et al. 2021. Robust Open-Vocabulary Translation from Visual Text Representations
以前、分かち書きに頼ることなく「文字」から高品質な事前学習を実現する CANINE という手法を紹介したばかりですが、今度は、トークンどころか「文字」という概念も使わない新しい形の機械翻訳モデルが登場しました。ジョンズ・ホプキンズ大学の研究者によって提案された、テキストを画像化してここから直接翻訳するこのモデル、「自然言語処理」と「画像処理」の境界を曖昧にしてしまう非常に興味深いものですので、論文速報として紹介したいと思います。
ニューラル機械翻訳はノイズに弱い

機械翻訳モデルは、ミススペルや文字の入れ替えなどのノイズに弱いということが知られています。これは、近年のニューラル機械翻訳モデルがサブワード分割を用いて訓練されていることが主な原因です。例えば、上の Figure 1 に示したように、単語に対して母音化、ミススペル、見た目の似た文字(エルとイチなど)、似た部首などが含まれた場合、BPE (Byte-pair encoding) を使って分割すると、全く違った分割になってしまいます。これらの分割の違いをモデル側で吸収するのは、トークンに頼っている限り、非常に難しいと考えられます。
一方、人間が言語を認識プロセスは、「文字の入れ替え」や「見た目が似た文字」などに対して非常に頑健であることが知られています。これは、我々が言語を認識する際には、主に視覚情報に頼っているからであり、視覚情報をうまく使うと、上記のようなノイズにうまく対応できるのではと考えられます。
これまでも、主に中国語など、表記体系の複雑な言語において、「文字の形」を畳み込みニューラルネットワーク (CNN) などでモデル化する研究がありました (例: Liu et al. 2017)。今回紹介する論文では、この考えをさらに押し進め、テキストを画像としてレンダリングし、その画像を「スライス」に分割、OCR (光学文字認識) の技術を使って埋め込み表現に変換し、そこから直接翻訳してしまいます。
なお、OCR の技術を使うといっても、画像から文字を認識するわけではなく、あくまで中間的な潜在表現を抽出するために使われている点に注意が必要です。
画像から直接翻訳する仕組み
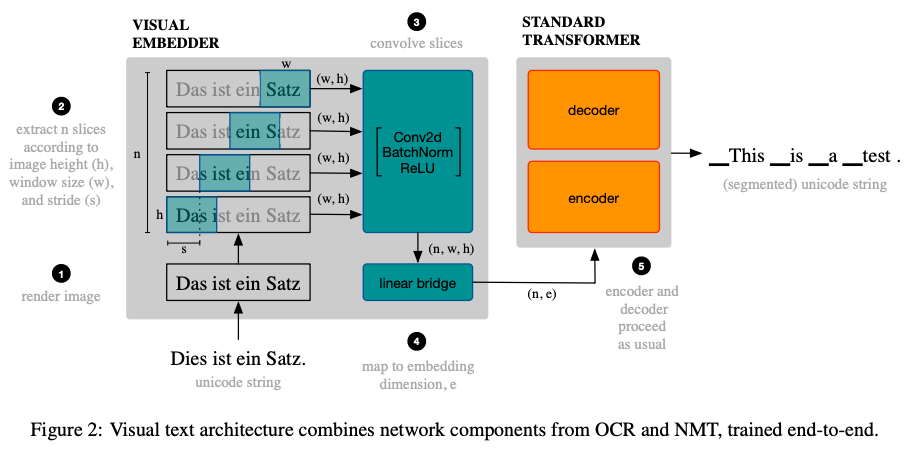
本手法の概要図を上に示します。まず、テキストを画像化し、その上で高さ $h$, 幅 $w$ のウインドウをスライドさせ、画像を順に「スライス」として切り出していきます。ウインドウは $s$ ピクセルずつスライドさせます。ここで、$w > s$ として、スライス同士が少しだけオーバーラップするようにします。ここでの $w$ と $s$ は、ハイパーパラメータとして言語ペアごとに調整します。音声認識にて、波形からスペクトログラムを経て特徴量を抽出する過程に似ていますね。
次に、こうして抽出されたスライスを、畳み込み層を使ってさらに処理します。この層は、二次元の畳み込み、バッチ正規化、ReLU を組み合わせた標準的なものです。この層は何層も組み合わせても良いのですが、ほとんどの言語ペアにおいて、1層だけ使う場合も複数使う場合も大差なかったということで、実験では主に1層だけ使っています。
最後に、畳み込み層から得られた出力を線形変換し、エンコーダーに入力します。機械翻訳においてエンコーダーに入力されるのはトークンを埋め込みに変換したものですが、ここではスライスから畳み込み層→線形層を通じて埋め込みを計算している点が異なります。最後に、エンコーダー・デコーダーに基づく通常の系列変換モデル(トランスフォーマー)を使って翻訳します。出力は、通常の機械翻訳と同様、トークン(サブワード)列です。
もちろん、これらの前処理層は、エンコーダー・デコーダーと共に、エンドツーエンドで、通常のクロスエントロピーを用いて学習されます。ちなみに、この畳み込み層を完全に取り除くと、Vision Transformer (Dosovitskiy et al. 2020) とかなり似た構造になります。通常のトランスフォーマーベースの系列変換モデルに CNN が一層増えただけなので、パラメータと計算量はほとんど同じで済みます。
テキストベースの翻訳精度と同等
実験では、(1) TED トークの多言語翻訳データセット MTTT、(2) ノイジーなテキストの機械翻訳データセット MTNT、(3) 特許申請書の多言語コーパス COPPA-V2 を使い、翻訳精度を評価しています。実装には fairseq を使い、ベースラインは基本的には IWSLT 14 de-en のデフォルトのハイパーパラメータに従っています。テキストのレンダリングには pygameを、フォントには Google Noto フォントファミリーを使っています。
まず、MTTT コーパスを使って、テキストベースの手法(ベースライン)と画像ベースの手法を比較しています。ほとんどの言語ペアに対して、BPE の語彙サイズを最適化したテキストベースの手法と同等の翻訳精度 (BLEU 値) を出せたということです。
(ちなみに興味深いのは、これまで推奨されていたバッチサイズ 4,096 トークンに対して、それよりも大幅に大きい 16k トークンのバッチサイズを使うと、特に中国語・韓国語・日本語での性能が大幅に向上したということです)
ノイズに対する頑健性

次に、提案手法のノイズに対する頑健性を調べるために、2つの実験をしています。一つ目は、入力テキストに人為的にノイズを加えた場合の頑健性の調査です。まず、ユニコード上でコードポイントは異なるが見た目の似た文字に置き換えるノイズを加えています。例えば、上の Figure 4 では、ラテン文字を形の同じキリル文字に置き換えており(赤色で示した文字)、見た目では全くわかりません。加えるノイズの割合を徐々に増やしていくと、テキストベースの手法では精度が大幅に低下するのに対して、画像ベースの手法では精度をほぼ一定のレベルに保っています。
また、この他にも、文字を l33tspeak で変換する、language → langauge のように文字を置換する、先頭と末尾を保って順番を入れ替えるケンブリッジ文 などのノイズを加えた場合も実験しています。置換およびケンブリッジ文の両方において、入れるノイズの量を増やすほど、画像ベースの手法の優位性が大きかったということです。
最後に、自然とノイズが入ったデータ (MTNT と COPPA-V2) を使い、モデルの頑健性を調べています。ドイツ語→英語とロシア語→英語の場合において、文字ベースの手法とほぼ同程度の精度が実現できたということです。
(萩原注: ただ、提案手法は、日本語や中国語からの翻訳には総じて弱いようで、これは主に漢字という表記体系の複雑さに起因しているかもしれません)
おわりに
はじめに書いたように、畳み込み+トランスフォーマーによってテキストを文字単位で画像のように処理してしまう手法、CANINE が提案されて間もないのですが、このように「文字」という概念も使わず、画像として処理するという手法は非常に興味深いです。現段階では、まだ「テキストベースの手法を大幅に上回る」ということではありませんが、論文にも書いてあるとおり、この研究はまだ始まったばかりであり、今後、アーキテクチャの検討や事前学習などのテクニックにより、さらに性能が向上していく可能性があります。もしかしたら、言語やドメインによっては「画像から翻訳」がデフォルトになるような日も来るかもしれません。
一方で、コンピューター・ビジョンや音声認識の分野では、画像や音声を離散化して、まるでテキストのように扱う手法 も提案されており、ここでは自然言語処理の分野とは逆の流れが起きているという点は注目に値します。離散化→トランスフォーマーによるモデル化、という手法が非常にうまく行くためですが、このように、今後も言語・画像・音声の分野の垣根がどんどんとなくなっていることが分かります。
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人