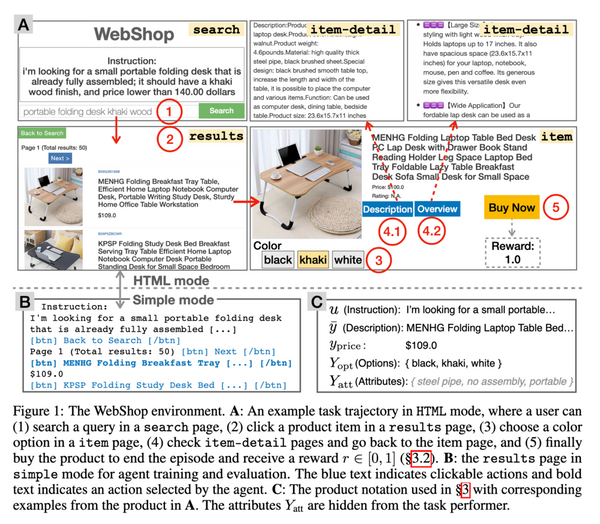
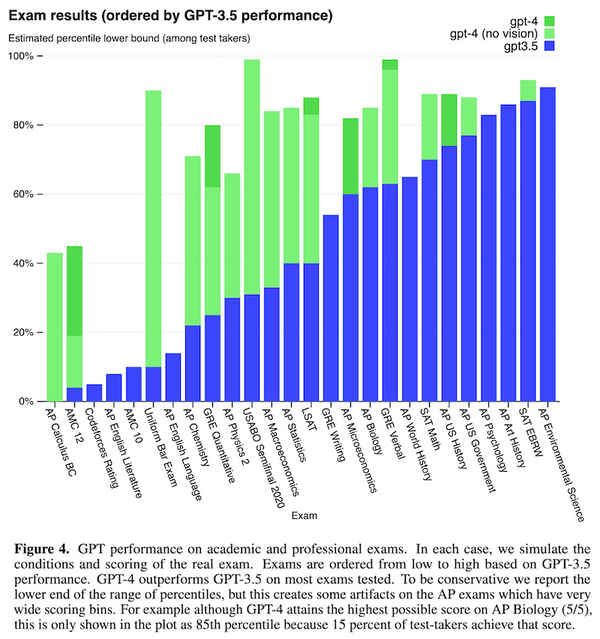
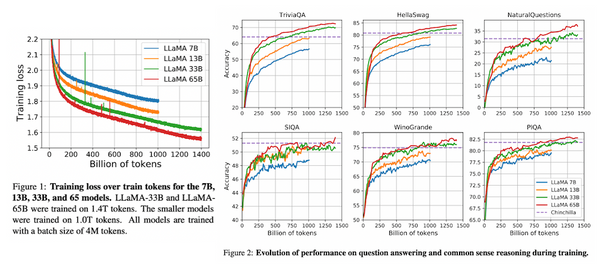
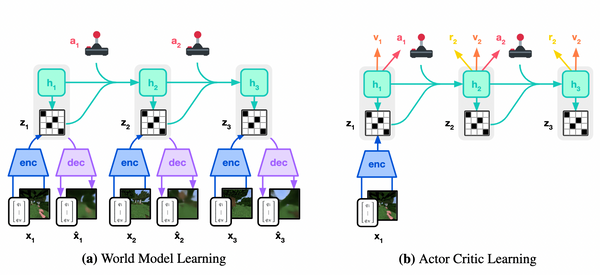
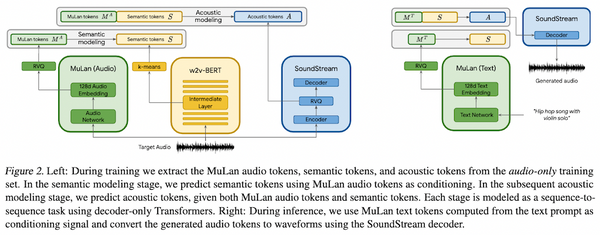
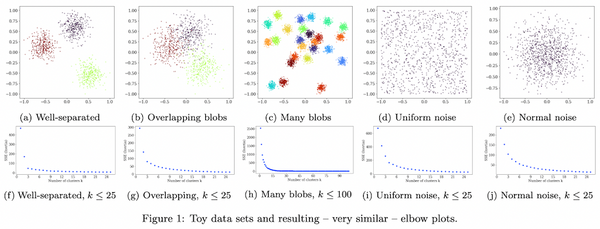
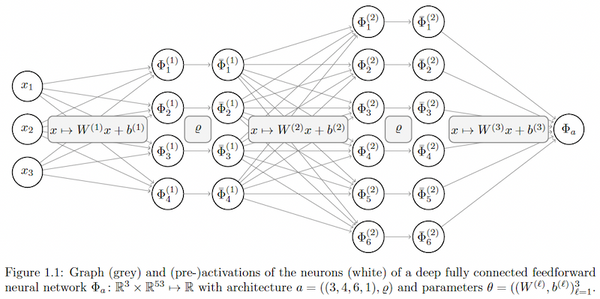
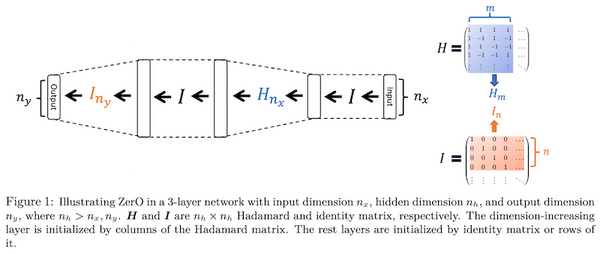
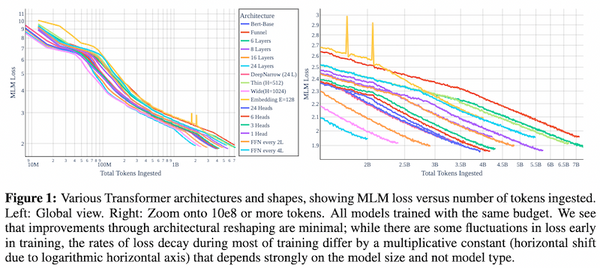
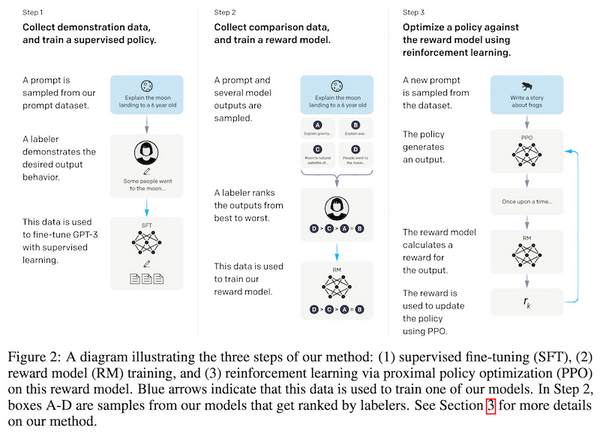
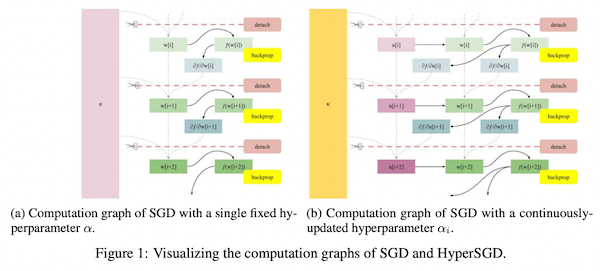
先週、OpenAI から最新の大規模言語モデル GPT-4 が発表されました。現時点で性能レベルで最高と考えられる GPT-4 では、知能試験で人間を上回る成績を残し、学術系のベンチマークにおいてもこれまで発表された言語モデルを大きく上回る SOTA を更新しています。一方、発表された論文内には、モデルのスケール、訓練データや計算量についての情報が全く無く、「これはアカデミックの論文ではなく、単なるプロダクト宣伝である」という批判もコミュニティ上で続出しています。本記事では、この GPT-4 について、テクニカル・レポートを読み解き、分かる範囲でその技術を解説したいと思います。