
登場してから何かと世間を賑わせている Stable Diffusion。高品質な画像生成もさることながら、比較的軽量で、メモリの少ない GPU 等でも手軽に動かせたり、モデルとコードが全て OSS として公開されており、カスタマイズ等が可能であったりと、様々な方面にインパクトを与えています。Stable Diffusion は、技術的には、過去2年間ほどで研究開発が急速に進んだ「拡散モデル」の応用ですが、その基礎から理解しようとすると、文献をどこまでさかのぼり、どの論文をどのような順番で読んだら良いか困ってしまう方も多いのではないでしょうか。
本記事では、この Stable Diffusion の背景となる技術を基礎から理解したい方向けの、必読論文のリストとその概要を紹介します。なお、論文自体の解説記事ではないため、各論文の詳細については、リンク先の解説記事や元論文を参照いただければと思います。
ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての高品質な記事を毎月5〜6本配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
はじめに
本記事で紹介する必読論文のリストは、以下の通りです。
- 基礎編
- U-Net (Ronneberger et al., 2015)
- ビジョン・トランスフォーマー (Vision Transformer; ViT; Dosovitskiy et al., 2020)
- CLIP (Radford et al., 2021)
- 拡散モデルの基礎
- NCSN (noise conditional score networks; Song and Ermon, 2019)
- DDPM (denoising diffusion probabilistic models; Ho et al., 2020)
- 拡散モデルの発展
- DDIM (denoising diffusion implicit models; Song et al., 2020)
- Improved DDPM (Nichol and Dhariwal, 2021)
- ADM (ablated diffusion model; Dhariwal and Nichol, 2021)
- GLIDE (Nichol et al., 2021)
- Stable Diffusion
- LDM (latent diffusion model, Rombach et al., 2021)
基礎編
まず、前提知識として、機械学習の基礎と、ニューラルネットワークの基礎 (CNN、トランスフォーマー等) はあるものとします。
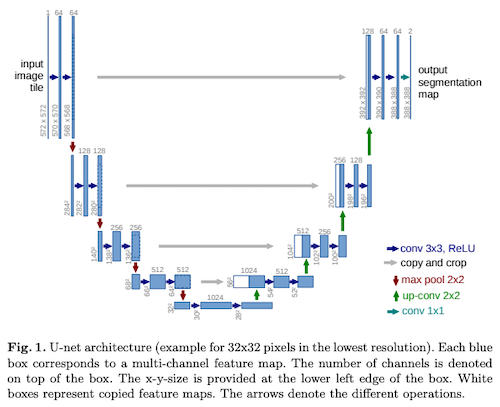
- U-Net (Ronneberger et al., 2015) ... U-Net は、画像を同じサイズの別の画像に変換するために良く使われるニューラルネットワークです。多くの画像セグメンテーションモデルや、画像変換でおなじみの pix2pix (Isola et al., 2017) などで広く使われているモデルです。アルファベットの「U」の字のように、エンコーダーで徐々に高抽象度・低解像度の情報を抽出し、デコーダーで元の解像度に戻すという構造をしているためこう呼ばれます。
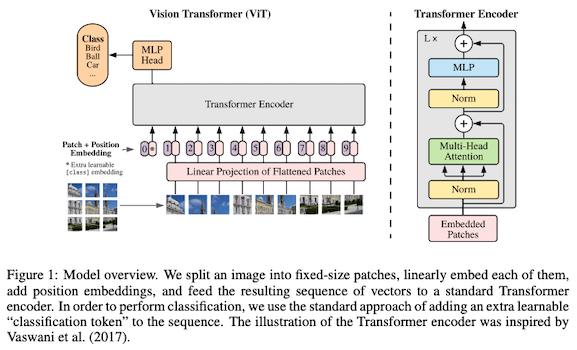
- ビジョン・トランスフォーマー (Vision Transformer; ViT, Dosovitskiy et al., 2020) ... ビジョン・トランスフォーマー (ViT) は、トランスフォーマーを画像分類タスクに応用したものです。画像を 16×16 ピクセルのパッチに分割し、それをあたかも言語の「トークン」のようにトランスフォーマーに入力し、高い分類精度を達成しました。
 藤井 亮宏
藤井 亮宏
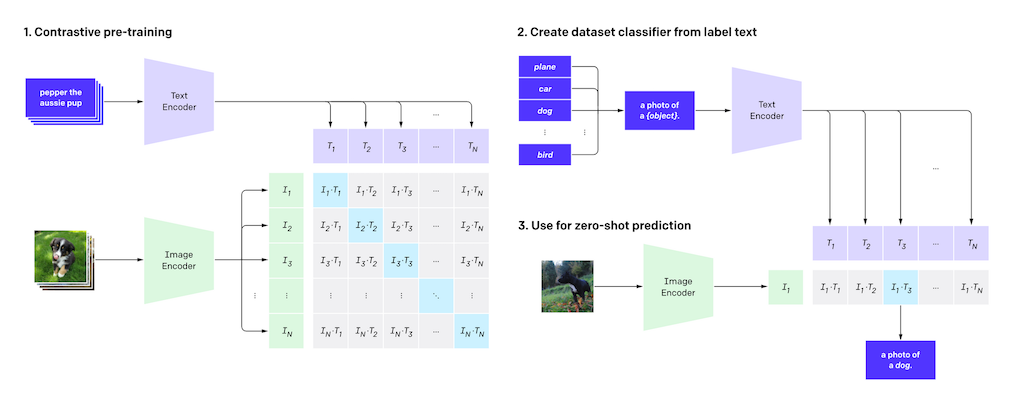
- CLIP (Radford et al., 2021) ... CLIP は、入力されたテキストと画像が、どの程度意味的に類似しているか (テキストがどの程度うまく画像を描写できているか) を計算するモデルです。テキスト・エンコーダー (トランスフォーマー) と画像・エンコーダー (ResNet もしくは上述のビジョン・トランスフォーマー) を使い、両者を共通の潜在表現 (ベクトル) に変換し、類似度を計算することによってこれを実現します。CLIP は、Stable Diffusion の「言語理解コンポーネント」(テキストエンコーダー) として使われています。
萩原 正人
拡散モデルの基礎
現在、普及しているテキスト→画像生成モデルのほとんどは、拡散モデル、正確には、「ノイズ除去拡散確率モデル」 (DDPM; denoising diffusion probabilistic models, Ho et al., 2020) に基づいています。拡散モデルで最も重要な論文を一つだけ挙げるとすれば、間違いなくこの論文になるでしょう。
ただ、この論文、いきなり読み始めると、大量の数式と難しい概念が出てきて挫折してしまう可能性が高いため、拡散モデルの概要を他の論文やチュートリアル等でおおよそ理解してから挑戦することをオススメします。
拡散モデルに取り組む前に、概念的に知っておくと役に立つのが、「スコアベースの生成手法 (Song and Ermon, 2019)」です。このモデルは、 NCSM (noise conditional score networks; ノイズ条件付けスコアネットワーク) とも呼ばれています。
画像などの個々のデータは、多次元空間上の点で表されます。高画質な画像を生成するためには、この「点が多くあつまっていそうな領域」から新たな点を生成すると上手く行くと考えられます。このように、現実のデータのあつまり (分布) をどのようにデータから推定し、そこから新たな点をサンプルするか、というのが、生成モデルの本質的な問題です。

スコアベースの手法では、ノイズのような適当なデータから始め、徐々に変形させていくことによりデータを生成します。上の図で言えば、2次元の適当な位置からスタートして、リアルな画像のある領域 (赤色の濃い領域) に行く問題を考えます。
ここで、2次元空間上の各点において、リアルな画像の方向、すなわち、黒い矢印で表されるデータの密度の高い方向に行くベクトルを推定できれば、それを辿っていくだけでデータが生成できます。この「どちらに進んだらリアルな画像に近づくか」を表した方向を「スコア」と呼びます。
現実のデータにノイズを加える (データ空間上でぼかす) ことにより、この「スコア」を推定するのが、「スコアマッチングによる生成手法」の考え方です。後で分かりますが、この「どちらに進んだらリアルな画像に近づくか」という方向は、ニューラルネットワークで推定することができ、ノイズを除去していくことでデータを生成する拡散モデルと、このスコアマッチングによる生成は、数式の係数などの細かい違いを除いて、基本的に等価であることが知られています。
なお、このスコアベースの手法については、著者の一人による非常に分かりやすい YouTube の講演動画があります。
萩原 正人
ここでやっと、「ノイズ除去拡散確率モデル」 (DDPM; denoising diffusion probabilistic models) に移ります。DDPM は、Ho らによって 2020 年 6 月に提案されたモデルで、下画像のように、ノイズ画像 ${\bf x}_T$ から元画像 ${\bf x}_0$ を復元させるステップを何回も繰り返し徐々にノイズを除去していくことによって画像を生成します。
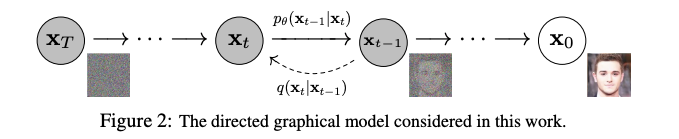
具体的には、元画像 ${\bf x}_0$ にノイズを乗せる関数 $q$ を $T$ 回適用し、ノイズ画像 ${\bf x}_T$ を生成します。これは、ガウシアン (正規分布) に従うデータを生成して足し算すれば良いだけなので、人為的に簡単に生成することができます。この過程を、前向き過程 (forward process)、もしくは拡散過程 (diffusion process) といいます。
そのノイズを関数 $p$ によって復元する、すなわち、現在の画像から、ノイズとして乗っている部分を推定するニューラルネットワークを学習し、ノイズ成分を引いていくことにより、ノイズからの画像生成が可能になります。上図では、右向きの矢印に相当しますが、これを逆向き過程 (reverse process) と呼びます。
数学的に式変形を進めると、最終的には、「ノイズを人為的に乗せた画像から、元の画像を復元する」という問題に帰着でき、その「復元した実際の画像と予測の差分」という損失関数 (ニューラルネットワークの訓練に使われる「ゴール」) が導かれるという分かりやすいモデルです。
拡散モデルの基礎、および、発展手法のいくつかについては、日本語では、以下の解説動画が丁寧・正確で分かりやすく感じました。数式も含めて、もう少し深く理解したい方にオススメです。
- 【Deep Learning研修(発展)】データ生成・変換のための機械学習 第7回前編「Diffusion models」
- 【Deep Learning研修(発展)】データ生成・変換のための機械学習 第7回後編「Diffusion models」
萩原 正人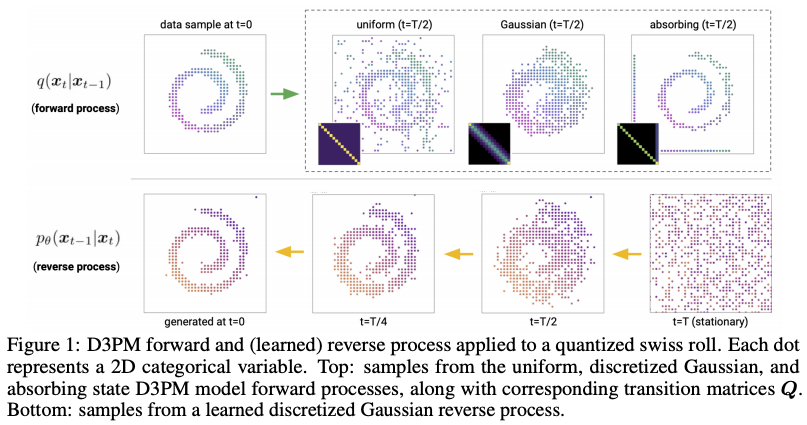
拡散モデルの発展
この拡散モデル DDPM については、その後も、改善手法が大量に提案されています。ここでは、Stable Diffusion に至るまでに提案された発展的な論文のうち、重要なものを紹介します。

- 高速な生成を可能にした DDIM (Denoising Diffusion Implicit Models; Song et al., 2020)
DDPM の問題点の一つとして、徐々にノイズを除去しながら画像を生成するのに 1,000 ステップなどの長い時間がかかる、という問題があります。そこでこの論文では、DDPM を一般化したモデルを考え (上図)、その中から DDIM と呼ばれる特殊な場合を考えることにより (1) 品質を保ったままのステップ数の削減 (2) 生成を決定的にし、同じノイズから同じ画像が生成できるようなモデルを提案しています。
- 改善型 DDPM (Improved DDPM, Nichol and Dhariwal, 2021)
こちらの論文では、オリジナルの DDPM にいくつかの改良を加えると、高速・高品質の画像生成が可能になることを示しています。具体的には、拡散過程で付加するノイズスケジュールを調整したり、ステップ幅 (時間) のサンプリング方法を改善したり、といった工夫により、尤度 (データがモデルにフィットする度合い) を改善できることを示しています。また、ノイズ除去に使う UNet のサイズを増やすことによって、生成画像の質が予測可能な形で改善することを示しています。

- GAN を超えた拡散モデル ADM (ablated diffusion model; Dhariwal and Nichol, 2021)
「画像生成において、拡散モデルが GAN を超えた」と題されたこちらの論文では、拡散モデルにさらに複数の変更を加えることにより、BigGAN-deep (Brock et al., 2018) に匹敵するような画像生成の質 (上図参照) を可能にしています。
変更点の一つは、「分類器誘導型 (classifier-guided)」と呼ばれる生成です。これは、画像を入力し、「コーギー犬」「フラミンゴ」「ハンバーガー」のような、その画像のクラスを出力する分類器が利用できる場合、その分類器の出力が大きくなるように拡散モデルを誘導することによって、あるクラスの高品質な画像が生成できるようになるというものです。もちろん、分類器による誘導を使う場合、ラベル (画像の正解クラス) の付いたデータセットが必要になります。
- 分類器不使用型 (classifier-free) の拡散モデルと GLIDE

なお、その後ほどなくして、分類器を別途訓練しなくても、生成モデル自体に条件付けの機構を組み込み、希望のクラスの画像を生成することができる「分類器不使用型 (classifier-free)」の拡散モデルが提案されました (Ho and Salimans, 2021)。
さらに、ここまでに紹介した拡散モデルは、条件なしで、もしくはクラスによって条件付けて画像を生成したものが主流でした。ここで、画像とテキストの類似度をとらえる CLIP をテキストエンコーダーとして使い、分類器不使用型の拡散モデルを使うことによって、自由なテキストによる画像生成を実現する GLIDE (Nichol et al., 2021) が発表されました。
拡散モデルと、「テキストからの画像生成 (text2image)」を組み合わせたものは、ネット上のコミュニティによって草の根的に開発されたものが 2021 年の夏頃から既に存在していまいましたが、論文として正式に発表されたものとしては GLIDE が最も代表的なものです。
藤井 亮宏
この頃になって、OpenAI および Google の各社から、高品質な「テキスト→画像」生成モデルが次々と発表されました。OpenAI の DALL·E 2 は、基本的に GLIDE と同じ仕組みでテキストから高品質な画像を生成します。また、Google の Imagen も、拡散モデルをベースとしながら、強力なテキストエンコーダーが画像生成の質に重要な役割を果たしていることを示しました。
なお、Google からは、Parti と呼ばれる画像生成モデルもすぐに発表されていますが、これはトークン化した画像を順に生成する自己回帰的なモデルであって、拡散モデルではない点に注意が必要です。以下の表では、これら3つのモデルの簡単に比較しています。
| 手法 | リリース日 | タイプ | ゼロショット MS COCO FID | モデルサイズ | 訓練データ |
|---|---|---|---|---|---|
| DALL·E2 | 2021/4/13 | 拡散モデル | 10.39 | 12B | 2.5億のテキスト・画像ペアをWebで収集 |
| Imagen | 2022/5/23 | 拡散モデル | 7.27 | 7.6B | LAION-400M + Google社内データ |
| Parti | 2022/6/22 | 自己回帰 | 7.23 | 20.6B | LAION-400M, FIT400M,JFT-4B (+ Google社内データ?) |
萩原 正人 藤井 亮宏
藤井 亮宏 藤井 亮宏
藤井 亮宏
潜在拡散モデルと Stable Diffusion
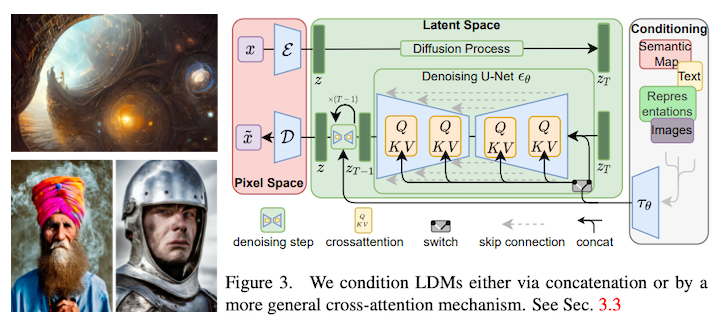
ここでついに「ラスボス」の登場。Stable Diffusion の元になっている潜在拡散モデル (LDM; latent diffusion model, Rombach et al., 2021) です。
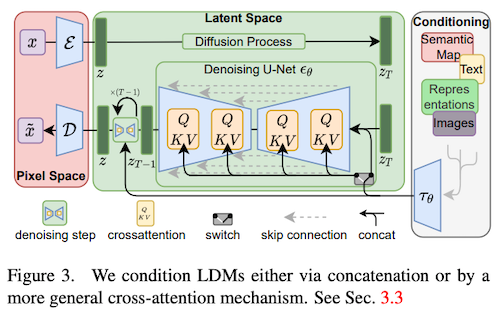
これまでの拡散モデルでは、画像をピクセルの配列として直接扱い、ピクセル単位でノイズの付加と除去を計算しました。しかし、この方法では、知覚的に重要ではない画像のディテールを表現するのにモデルの表現力が使われてしまったり、変数の次元が多く、計算量が多くなってしまったり、という問題があります。
そこで、こちらの論文で提案されている潜在拡散モデルでは、画像をVQGAN (Esser et al., 2020) と同様の仕組みを使い、低次元の潜在表現 (画像の大まかな特徴をとらえたベクトル) へと変換し、その潜在空間内で拡散モデルを適用します。つまり、ノイズから画像を生成する代わりに、ノイズから潜在表現をまず生成し、それを画像へと戻す、という2段階のプロセスを経て画像を生成します。
萩原 正人
なお、Stable Diffusion の技術詳細については、公式論文等は出ていませんが、以下のページに詳しい解説があります:
なお、Stable Diffusion は、LAION-Aesthetics と呼ばれる「美しい」画像のみを集めたデータセットを用いて学習されている点も特徴的です。このデータセットは、「美しさ」の人間による判定を模倣するように訓練したモデルを使い、大きい画像キャプションデータセットである LAION から作られているということです。このように、訓練データ自体をキュレーションするというのも、論文にはなりにくいですが、高品質なモデルを開発するためには非常に重要な作業であるといえます。
(なお、本記事の執筆には、birdMan 氏のツイートも参考にさせていただきました。この場を借りてお礼申し上げます)
関連記事
萩原 正人 萩原 正人
萩原 正人