テキストの記述にしたがって高品質な画像を生成する「画像生成 AI」が話題です。DALL·E, DALL·E 2, Parti, Imagen など、研究ベースで多くの手法が発表されており、Craiyon, DALL·E 2, Stable Diffusion, Midjourney など、実際に一般消費者が使える AI 画像生成サービスも広く普及してきました。
本ブログでは、昨年の早い段階から、テキストからの画像生成に関連する研究・技術を何度か取り上げてきました。研究ベースでは以前から開発が進んでいましたが、去年の VQGAN+CLIP を皮切りに、オープンソースのモデルが多数開発され、臨界点を超えて普及が急速に進んだ感があります。
これまでに解説した画像生成技術については、以下の記事をご参考ください。
 萩原 正人
萩原 正人 萩原 正人
萩原 正人 萩原 正人
萩原 正人 藤井 亮宏
藤井 亮宏 藤井 亮宏
藤井 亮宏
現状のテキストからの画像生成 AI は、指示を全て (英語の) テキストで書かなければならず、また、生成される画像の細かな制御が難しいという問題があります。最近の論文では、言語に加えて「物体」「概念」を使って画像を生成したり、プロンプトを使って画像の細かな編集を可能にしたりと、生成される画像の質に加え、その「制御性」に改善を加える方向にシフトしつつある印象です。本記事では、この「テキストからの画像生成」技術に関して、次の発展フロンティアとなる技術を、比較的最近発表された論文から読み解きます。
ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての高品質な記事を毎月5〜6本配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
テキストを使わず、物体の表現から画像を生成する DALL·E
元論文: Singh et al., 2021. Illiterate DALL-E Learns to Compose
上で見てきたように、様々な「画像生成 AI」が発表され、広く利用されていますが、これらは当然のことながら、「全てテキストで指示を与えなければいけない」という点がネックになることがあります。非現実的な状況を自然言語で指示することができるのはこれらのモデルの大きな利点であるのですが、画像を細かにコントロールしなければならない場合、テキストを工夫する「プロンプト・エンジニアリング」に時間と費用を割かないといけないという問題があります。
「読み書きできない DALL·E は、構成することを学習する」と題された本論文では、テキストを使わずに、物体の表現だけからシーンを構成し、画像を生成できる DALL·E 的なモデル SLATE (SLot Attention TransformEr) を提案しています。
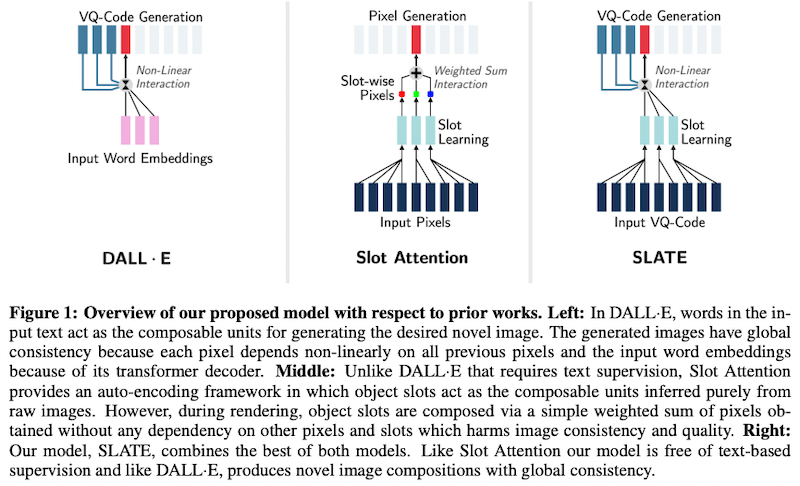
これまでも、スロット注意 (Slot Attention) 機構を使って物体中心学習 (object-centric learning) を実現するモデルが提案されていました (Locatello et al., 2020)。これらのモデルでは、まず、エンコーダーが入力の画像を受け取り、「物体表現の集合」をスロットとして生成します。ここから画像を再構成するためには、スロットごとに画像とアルファマスク (混合率・透明度をピクセルごとに示したもの) を生成する「ピクセル混合デコーダー (pixel-mixture decoders)」と呼ばれるネットワークを使い、画像を生成します (上図中央)。ネットワーク全体は、画像を再構成できたかどうかを損失関数として学習されます。
しかしながら、これらのモデルでは、(1) スロットが「物体」の概念を学習するために、意図的に弱いデコーダーを使わなければいけないジレンマ、(2) 概念間でピクセル同士が独立なため、全体として画像の一貫性が無くなるという問題がありました。
そこで本論文の SLATE では、スロット注意 (Slot Attention) 機構をベースとしながらも、DALL·E で利用されている強力なデコーダー (Image GPT) を使うことによって、この2つの問題を同時に解決しています (上図右)。デコーダーの詳細については、DALL·E (初代) と同様、画像全体を離散的 VAE を用いてトークン表現に変換してから、トランスフォーマーの自己回帰的なモデルによって、ラスター順 (左上から順に) 生成します。自己回帰的に画像を生成することによって、ピクセル間が独立ではなくなり、画像全体の質・一貫性が向上する、ということです。

従来手法 (スロット注意) と本手法を使って生成された画像を上に示します。最も右の画像が再構成後のもの、それ以外は、各スロットから生成された画像と注意の重みを可視化したものです。提案手法 (Our Model) の方が、特に Bitmoji の顔構成データセットにおいて、より高画質な画像が生成できていることが分かります。
実験では、提案モデルの SLATE で生成された画像と、従来手法で生成された画像のどちらかがより「リアルか」を測定するために、Fréchet Inception Distance (FID) (Heusel et al. 2017) と、人間による判断を使って評価しています。その結果、比較した7つのデータセットにおいて、FID および人手評価の両方において、本手法の優位性が確認できたということです。
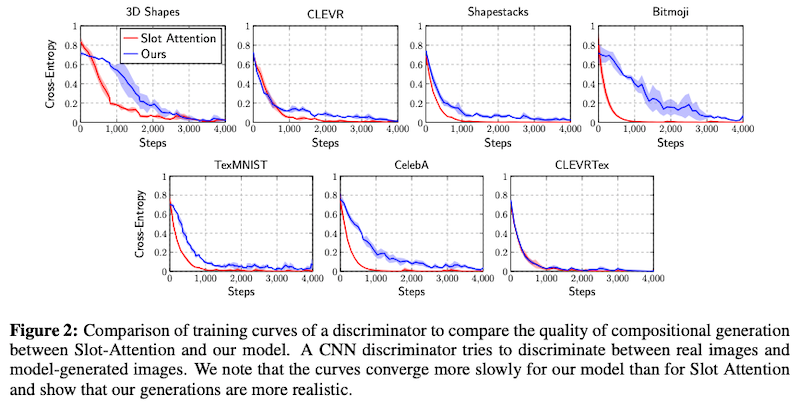
また論文では、CNN を使って、本物の画像と、提案手法や本手法によって生成された画像とを識別するモデルを訓練した時の、学習曲線 (損失の低下具合) を使って評価しています。生成された画像がリアルであれば、識別が難しくなるので、学習曲線がよりなだらかになる、と考えられるからです。上の Figure 2 で示したように、提案手法 (青色) の曲線の方が傾きがなだらかであり、提案手法がよりリアルな画像を生成できていることが分かります。
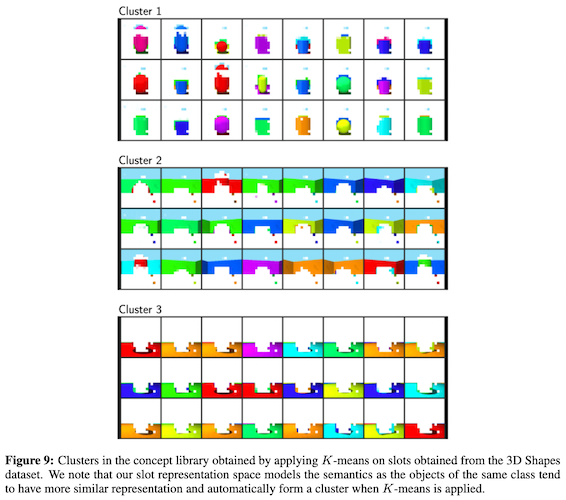
なお、本手法によって得られた物体概念表現を、K-means などのアルゴリズムを使ってクラスタリングすることにより、「視覚概念」のライブラリを構築することが可能です。上図に示したように、3D Shapes のデータセットから「壁」「物体」「地面」などの概念のクラスタを構築できています。
本研究、個別のデータセットを使った比較的小規模なものが多いのですが、DALL·E, DALL·E 2 のように巨大な画像のデータセットを使って学習した結果どのような物体概念が学習できるかは、非常に興味深いところです。
潜在空間上で高解像度・高速な生成を実現する拡散モデル LDM (Latent Diffusion Model)
元論文: Rombach et al., 2021. High-Resolution Image Synthesis with Latent Diffusion Models
DALL·E 2 や Parti など、最近の画像生成 AI で広く使われている拡散モデル (diffusion model)。訓練が安定しており、GAN で良く見られるモード崩壊 ("mode collapse"、似たようなデータしか生成しなくなる現象) が起きにくいなど、数々の利点があります。
一方で、現在主流の確率拡散モデル (Ho et al. 2020) では、画像のノイズを徐々に除去するように、すなわち、画像の RGB ピクセル空間上で直接、ノイズから画像を生成します。そのため、ニューラルネットワークをこの高次元空間上で訓練し、生成時にも何度も推論パスを実行しなければならないため、計算量が膨大になるという問題があります。また、画像を尤度ベースの生成モデルで表現しようとすると、情報量のほとんどが、ほとんど人間には知覚できない画像のディテール (高周波成分) を表現するのに無駄に使われてしまうという問題があります。
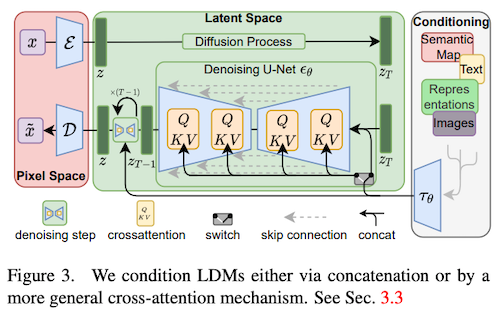
そこで本論文では、入力画像と知覚的にはほぼ同一でありながら、より計算コストの低い潜在空間上で学習・推論する潜在拡散モデル (latent diffusion models; LDM) を提案しています。LDM は、一言で言うと、「VQGAN の拡散モデル版」です。VQGAN (Esser et al., 2020) と同様の仕組みを使い、入力をより低次元・意味的な潜在表現 $z$ に変換し、その上で、ノイズから潜在表現を生成する拡散過程を学習します。生成された潜在表現は、デコーダーを用いて画像へと変換されます (上図)。
このように潜在空間上で拡散モデルを定義することにより、(1) 人間には知覚できない画像のディテールに左右されず、意味的に重要な情報のみをモデル化できる、(2) 潜在空間は画像よりも解像度が低く、計算量が低い、というメリットがあります。
なお、LDM では、通常の拡散モデルと同様、U-Net ベースのバックボーンを使っています (上図)。VQGAN ではトランスフォーマーを使って潜在表現の分布をモデル化していますが、トランスフォーマーは原理的に1次元の系列にしか対応していないのと違い、CNN ベースの U-Net では2次元の構造を捉えられるため、潜在空間に圧縮した場合でも非常に質の高い再構成ができるということです。

提案モデルの LDM によって生成された画像のサンプルを上に示します。条件無し画像生成では、従来の GAN や拡散モデルと同等もしくはそれ以上の質の生成ができるということです。また、潜在表現に変換する際に、入力する画像を4〜16倍ほどダウンサンプリングした場合に、生成の質と速度のバランスが最も良いという結果でした。

なお、本モデルは、U-Net の各層に、(オリジナルのトランスフォーマーで提案された) クロス注意機構を導入することにより、より詳細な条件付きの画像生成ができるようになります (上図の QKV で表してある層がそれに対応します)。例えば、テキストを入力として、トランスフォーマーによりエンコード、それを条件として画像生成することにより、DALL·E のようなテキストからの画像生成が可能になります。
これによって生成された画像のサンプルを上に示します。画像中に表示されるテキストも含め、入力に忠実かつ高品質な画像が生成できていることが分かります。MS COCO を用いたテキストからの画像生成の評価では、従来の CogView (Ding et al., 2021) や GLIDE (Nichol et al., 2021) 等のモデルよりも高品質な生成ができることを確認しています。
本モデル、他にも、レイアウトからの画像生成や、超解像化 (superresolution) や画像修復 (inpainting) などにもほぼそのまま応用でき、目覚ましい効果を上げています。論文中にふんだんにサンプルがあるので、興味のある方はそちらをご覧ください。
また、本モデルを LAION-400M を使って訓練したモデルが公式のリポジトリ から利用できます。
プロンプトを使って拡散モデルの生成画像を直接編集
元論文: Hertz et al., 2022. Prompt-to-Prompt Image Editing with Cross Attention Control
DALL·E 2 や Imagen など、最近のテイストから画像を生成するモデルでは、画像の詳細を変更しようとして、入力テキスト (プロンプト) を少しでも変更すると、画像全体が大きく変わってしまい、画像の細部の調整がほぼ不可能であるという問題があります。画像を同一に保つために、乱数シードを固定しても、プロンプトを変更するだけで全く異なる画像が生成されてしまいます。

拡散モデルベースのテキスト→画像生成手法では、上の LDM で見たのと同様、テキストを条件付けとし、1ステップ前の画像とテキストのクロス注意 (cross attention) の重みを計算、次のステップの画像を計算します (上図)。ごく最近 Google Research から発表されたこちらの論文では、この注意マップ (attention map) が、どの物体を画像のどこに配置するかという画像の構成を大まかに決定している、ということを発見しています。
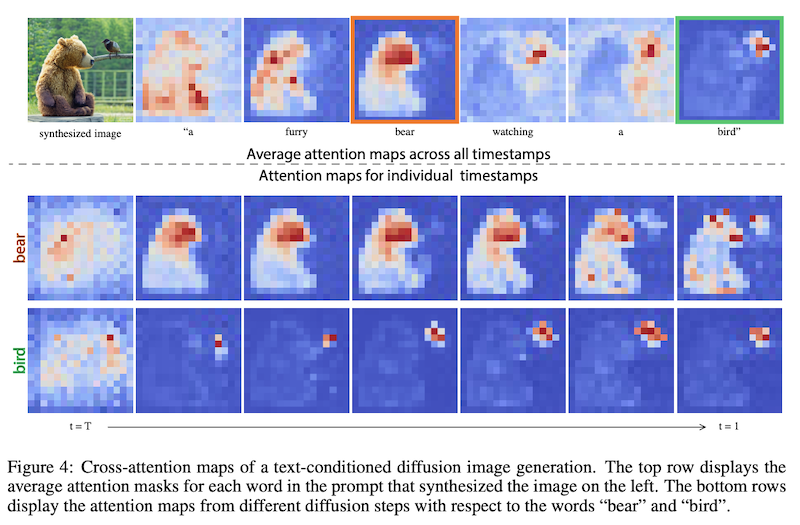
具体的に、「a furry bear watching a bird (鳥を見ている毛深い熊)」というプロンプトで、注意マップを可視化したのが上の図です。「bear (熊)」と「bird (鳥)」に対応する注意マップが、それぞれの物体に対応していること、また、画像の構成は、ステップ数が小さい段階、すなわち、拡散過程の初期の画像がまだノイジーな段階から既に決まっており、その後大きく変わることはない、ということが分かります。
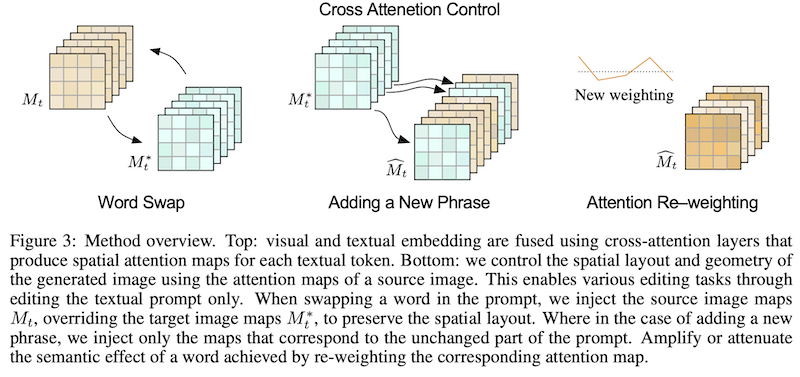
この性質を利用して、本論文では、注意マップを人為的に操作することによって、画像の構成を保ちつつプロンプトの指定通りに画像を編集するシンプルな手法を提案しています。具体的には、編集前のプロンプトと編集後のプロンプトを使い、2つの拡散過程(ノイズからの画像生成)を走らせるわけですが、その間で、プロンプトの編集パターンに応じて、編集後の拡散過程の注意マップを操作します。次の3パターンの編集に対応しています:
- 単語の置き換え ... 「a big red bicycle (大きな赤い自転車)」を「a big red car (大きな赤い車)」に変更するように、プロンプトの単語を置き換えた場合。この場合、古いプロンプトの注意マップを、新しいプロンプトにそのまま使います。
- 単語・フレーズの挿入 ... 「a castle next to a river (川のそばにある城)」を「children drawing of a castle next to a river (川のそばにある城を描いた子供の絵)」に変更するように、プロンプトに単語やフレーズを挿入した場合。この場合、古いプロンプトに存在する単語 ("castle", "river" など)は古い注意マップを使い、新しい単語 ("children drawing") は新しいプロンプトの注意マップを使います。
- 注意の重み変更 ... 「a fluffy red ball (ふわふわの赤いボール)」の「ふわふわ度」を変更したいように、プロンプト中のある単語の重みを変更したい場合。この場合、注意マップの形状はそのままに、重みを定数倍した注意マップを、新たな拡散過程に挿入します。

本手法を使って生成された画像の例を上の示します。左上から「通りが混雑している」の「混雑」の重みを下げる、「自転車に乗っている猫」の「自転車」を「車」に置き換える、「川のそばにある城」に「子供の描いた絵」を追加する、「デコレーションされたケーキ」に「ゼリービーンズ」を追加する例ですが、いずれも編集前の画像の構成を保ちつつ、変更後のプロンプトに忠実かつ高い品質の絵が生成できていることが分かります。

なお、この「注意マップの置き換え」は、新しい拡散過程の全ての時間ステップに挿入されるわけではない点に注意が必要です。拡散過程の前半の段階で画像の構成がおおよそ決定されることを考えると、拡散過程の前半の数ステップだけ、注意マップを置き換え、後半は新しい拡散過程に画像を生成させることによって、ある程度、画像の構成の自由度を新しいプロンプトに任せることができます。
上の図では、注意マップを挿入するステップ数の割合を変化させ、生成画像がどのように変化するかを調べています。全く挿入しない場合(左)では、画像の構成が完全に変わってしまっているのに対し、全てのステップに挿入する場合(右)では、構成の自由度が少なすぎ、逆に編集後のプロンプトに忠実な画像が生成できない (例えば、「車」が「自転車」のままになってしまっている) ことが分かります。

最後に、本手法を使って、本物の(すなわち、AI モデルによって生成されたものではない)画像を編集することも可能です。このために、逆向きの拡散モデルを適用し、注意マップを計算、プロンプトの編集に使います。これによって、上の Figure 10 のように、高品質な編集ができる場合もあれば、Figure 11 のように、画像の再構成があまりうまく行かない場合もあったということです。
「画像」を単語に変換して概念を指定する 「反転」拡散モデル
これまで見てきたように、テキストによって概念や情景を記述して画像を生成するモデルがさかんに研究・開発されています。これらのモデルは当然のことながら「テキストで全てを指定しなければならない」という欠点があります。「こんな感じの物体を別の構成・スタイルで描いてほしい」「この画像のようなスタイルで、記述する内容を描いてほしい」など、テキストで記述できない物体・構成・スタイルなどを指定することはできません。

この研究では、ユーザーが3〜5枚の画像として指定した「概念」をある種の「単語」として圧縮して表現し、それを画像生成 AI の入力の一部として利用できる画像生成モデルを提案しています。
言葉では少し分かりにくいので、具体的な結果 (上の Figure 1) で見てみましょう。最初の結果は、人の座った形の像の画像を4つ与え、概念化し、$S_*$ という仮想的な単語 (埋め込み) で表します。これをプロンプト内で、「$S_*$ の油絵」「$S_*$ のアプリのアイコン」「$S_*$と同じ姿勢で座ったエルモ」「かぎ針編みの $S_*$」のように使い、望みの画像を生成できます。次の例では、キャラクターの画像で与えられる概念を $S_*$ という単語で表現し、「ボートに乗って釣りをしている2匹の $S_*$」「$S_*$ のバックパック」「$S_*$ のバンクシー風の作品」「$S_*$ テーマの弁当箱」などの画像を生成しています。
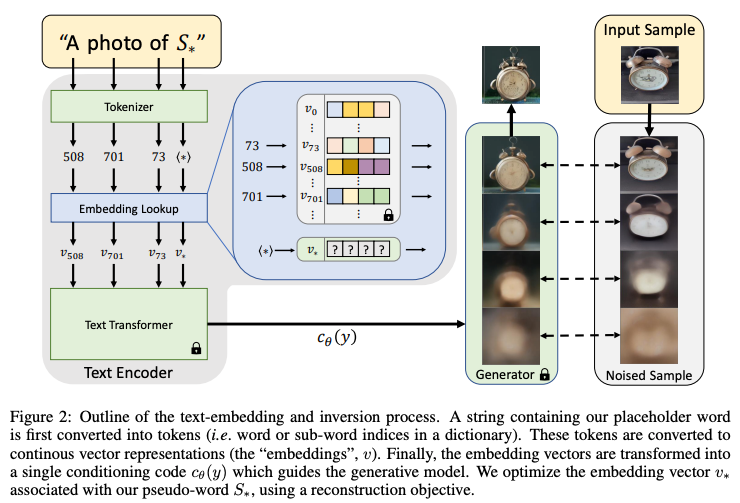
本手法のコアとなるのが、与えられた画像を概念に変換する「反転 (inversion)」と呼ばれる操作です。ここでは、概念を、仮想的な単語の単語埋め込み (word embeddings) として表します。上の図では、これが $v_*$ によって表されています。この単語埋め込み $v_*$を、「$S_*$ の写真」のようなプロンプトとともにテキストエンコーダーへと入力、そのテキストを条件として画像生成した結果、元の画像が復元できるように、$v_*$ を通常の確率的勾配降下法などを使って最適化します。この時、テキストエンコーダー (BERT) と拡散モデル (上で紹介した LDM) の重みは固定したままです。

本手法をスタイル転移 (style transfer) に応用することも可能です。上の図では、入力画像からスタイル $S_*$ を抽出し、「$S_*$ のスタイルで描いたパリの町並み」「$S_*$ で描いたブラックホールの絵」などの画像を生成することが可能です。

さらに、絵のセットを2種類与えて、$S_{style}$ と $S_{clock}$ を概念として抽出し、「$S_{style}$ で撮った $S_{clock}$ の写真」として、複数の概念を組み合わせることも可能です。
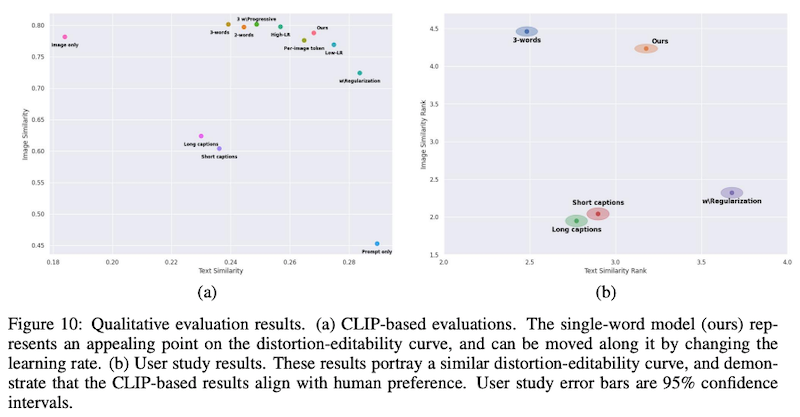
論文では、このように生成された画像がどのぐらいプロンプトに忠実で、かつ画像として質が高いかを、定量的に評価しています。プロンプトへの忠実さおよび画像としての再構成の質の高さは、それぞれ CLIP (Radford et al., 2021) のテキストおよび画像埋め込みの距離として測定できます。 その結果を表したのが、上図 (Figure 10) の左です。プロンプトへの忠実さと画像の再構成の質は、トレードオフの関係にありますが、提案手法 (Ours) は、その両者とも比較的高く、良いバランスを達成していることが分かります。
また、人手評価によって、「概念として与えた画像と類似しているか」「プロンプトと類似しているか」という2つの概念によってシステム出力をランキングした結果が上図 (Figure 10) の右ですが、こちらでも、提案手法が良いトレードオフを達成していることが分かります。
関連記事
藤井 亮宏 萩原 正人
萩原 正人