2021年も、人工知能業界では様々な動きがありました。本記事では、最新の深層学習の論文を何百本と読み解いて分かった「2021年の最重要トレンド」を詳細な参考文献と共に紹介します。人工知能の分野は、進歩が早くてキャッチアップが大変ですが、本記事を読めば、大まかなトレンドと重要研究をおさえられるように書きました。なお、厳密には 2021年に発表されたものではなくても、トレンドを理解する上で重要な論文は全て含めるようにしています。
ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての高品質な記事を毎月5〜6本配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
Image by Alan Warburton / © BBC / Better Images of AI / Nature / CC-BY 4.0
テキストと画像の類似関係をとらえる CLIP
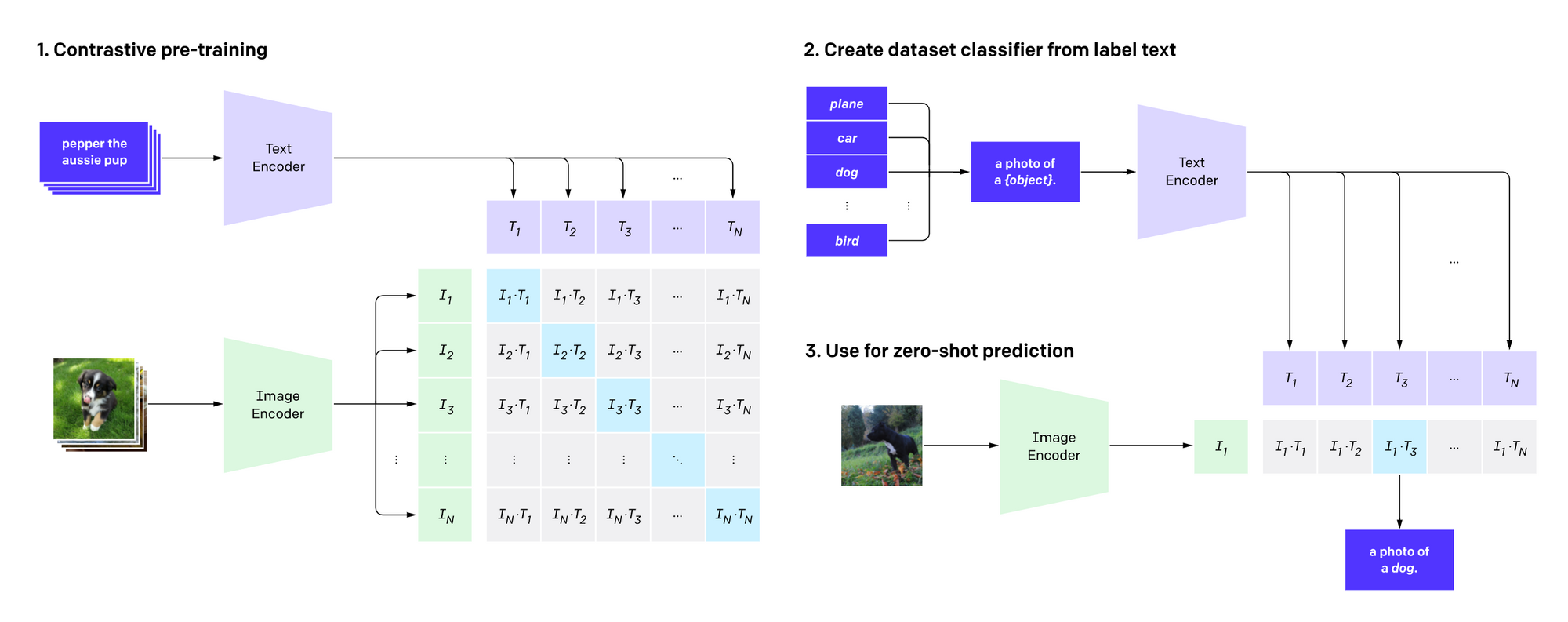
いきなり具体的な手法・モデルですが、AI 業界において今年、最も重要なマイルストーンは、間違いなくこの CLIP (Radford et al., 2021) でしょう。
2021年年初に OpenAI から発表されたこの CLIP、テキストから高画質な画像を生成できるモデル 「DALL·E (ダリー)」の陰に隠れて地味な存在でしたが、本ブログでは発表当初から「学術上・実用上非常に重要なマイルストーン」であると述べてきましたが、予想通り、その後も CLIP の利用が急速に広まっています。Kevin Zakka 氏のブログ記事では、「CLIP の分野への影響力を考えると、DALL·E と同時に発表されたことは逆に不幸である」「従来の固定クラスセットは死んだ」とまで述べています。また、「OpenAI の CLIP は、今年のコンピューター・ビジョンにおいて最も重要な発展である」と主張するブログ記事もあります。
CLIP の仕組みは、非常に単純です。ウェブから豊富に取得できる大量の画像と、それらに結び付けられたテキストを使って、画像とテキストの対応モデルを事前学習します。テキストと画像の内容が一致していれば高い類似度を、そうでなければ低い類似度を返す、それだけのモデルです。
それがなぜここまで有用なのでしょうか。まず、画像→テキストの方向性を考えると、画像を入力し、その画像に最も当てはまるテキストをいくつかの選択肢から選ぶことによって、画像分類が可能になります。従来の画像分類は、決められたクラスから一つの正解を選ぶ多クラス分類の枠組みで解くことが一般的でしたが、CLIP を使うと、範囲の決まっていない自然言語テキストを使って画像を分類できます。これは、対象のタスクのデータを使って CLIP を微調整 (fine-tune) することなく可能なので、「ゼロショット学習」が達成できることになります。
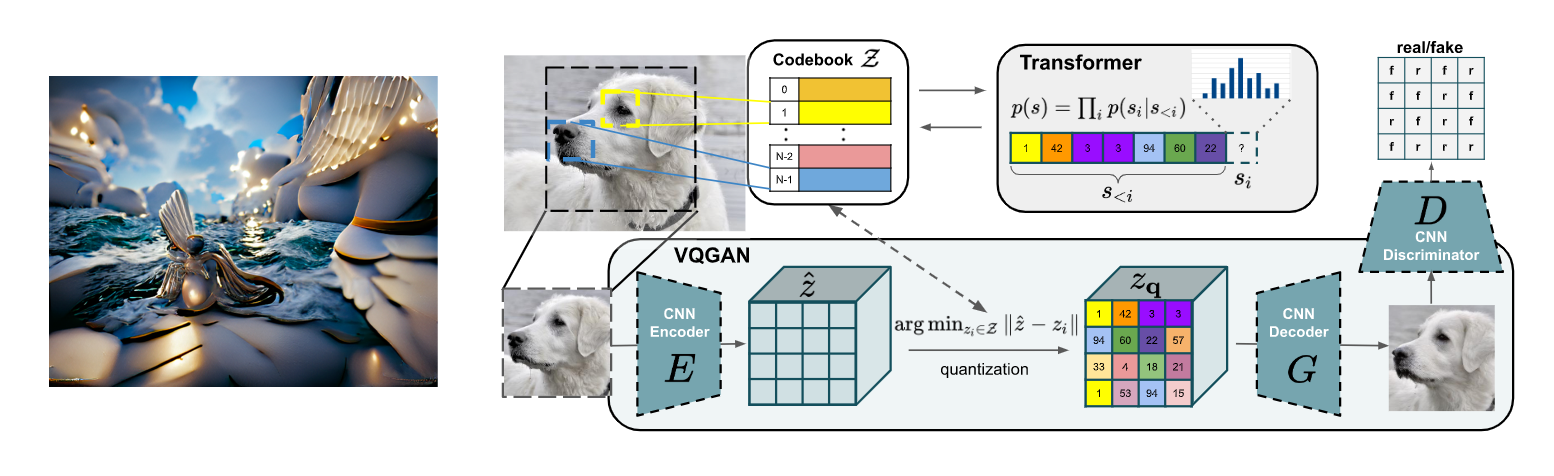
また、その逆の、テキスト→画像の方向性を考えると、あるテキストを入力し、そのテキストとの類似度が大きくなるように画像を最適化すると、自然言語から画像が生成できることになります。正確には、VQGAN (Esser et al., 2020) など、あらかじめ大量の画像によって事前学習された画像生成モデルと組み合わせ、その潜在表現を最適化することによって画像を生成します。この VQGAN+CLIP の組み合わせは、手軽に高品質な画像が生成できるため、今年の中頃にネット上で大きな話題となりました。最近では、強力な拡散モデル (diffusion model, 詳細は後述) と CLIP を組み合わせた「CLIP 誘導拡散モデル」も話題となっています。
このように、画像分類や画像生成以外にも、「汎用の画像理解エンジン」として、様々な利用が広がっています。前述した Kevin Zakka 氏のブログ記事では、ビジョンの分野で、reCAPTCHA を解く、物体検出、顕著性マップ (saliency map)の可視化、画像生成など、様々なタスクへの応用が実際の例と共に紹介されています。また、How Much Can CLIP Benefit Vision-and-Language Tasks? と題された論文 (Shen et al., 2021) でも、CLIP をビジュアル QA、画像のキャプショニング、視覚言語ナビゲーション(環境に置かれたエージェントを言語により誘導するタスク)などのタスクに応用し、強いベースラインに匹敵または超える性能を叩き出しているということです。参照文無しで画像キャプション生成の性能評価を実現する CLIPScore (Hessel et al., 2021)や、NeRF によるシーン生成 (Jain et al., 2021)、身体性 AI (Khandelwal et al., 2021)、ロボティクス (Shridhar et al., 20201) などにも応用されています。
最近では、CLIP を拡張してオーディオ・画像・テキストの3つのモダリティの関係を学習する AudioCLIP (Guzhov et al., 2021) や Wav2CLIP (Wu et al., 2021)、CLIP の学習を効率化した CLIP-Lite (Shrivastava et al., 2021)、自己教師あり学習を組み合わせた SLIP (Mu et al., 2021) など、CLIP の拡張・改善手法も多数提案されています。
 萩原 正人
萩原 正人 萩原 正人
萩原 正人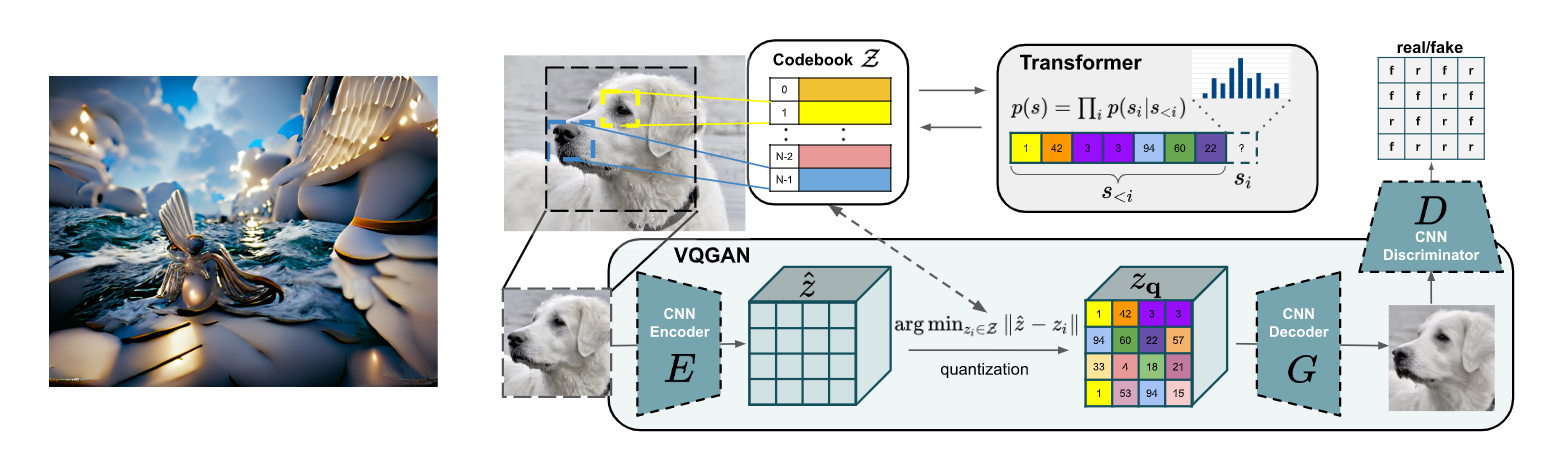
自己教師あり学習・対照学習
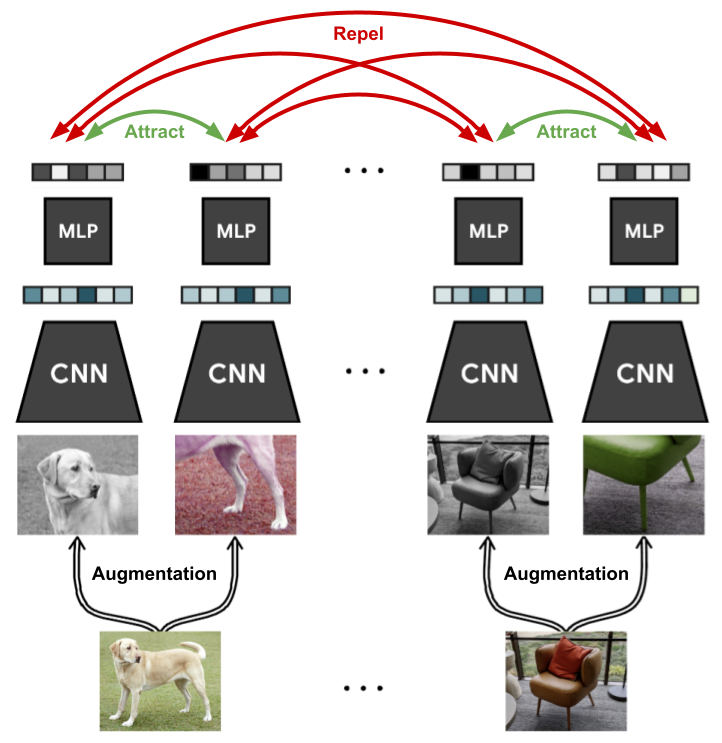
自己教師あり学習 (self-supervised learning) は、データ自身から疑似的な教師信号を作成して機械学習モデルを学習する手法であり、BERT (Devlin et al., 2018)で有名な「マスク言語モデル (masked language model)」など、様々な事前学習手法で幅広く用いられています。自己教師あり学習の中でも、対照学習 (contrastive learning) は、データに対する教師信号の代わりに、データ間の「類似・非類似」関係を使って自己教師あり学習をする手法の総称です (上図)。そのシンプルさと学習された表現の品質の両方から、ここ数年の間に、様々な人工知能タスクで利用が広がっています。
対照学習は、何も今年に入って提案された新しい手法ではありません。伝統的には、自然言語処理分野でポピュラーな Word2Vec (Mikolov et al. 2013) や QuickThorught (Logeswaran and Lee, 2018) などにおいて同様の手法が使われています。
最近では、自然言語処理でも、置換された単語を検出して事前学習する ELECTRA (Clark et al., 2020)、データ拡張と対照学習により高品質な文表現を獲得する CLEAR (Wu et al., 2020)、文書からサンプルしたテキスト断片を使って高品質な文埋め込みを求める DeCLUTR (Giorgi et al., 2020)、エンコーダーに2回入力するだけのシンプルかつ効果的な文埋め込み手法 SimCSE (Gao et al., 2021) など、対照学習に基づく表現学習手法が多数提案されています。
コンピューター・ビジョンの分野では、伝統的に、ImageNet など大量にラベル付けされた画像から「教師あり」で事前学習する手法が一般的でした。しかし、ここ2〜3年の間に、自己教師あり学習および対照学習手法がかなり普及しました。最も代表的なのは、単一の画像に異なるデータ拡張を施して表現学習する SimCLR (Chen et al., 2020, 上図) と SimCLRv2 (Chen et al., 2020) でしょう。他にも、モーメンタム・エンコーダーを使って対照学習する MoCo (He et al., 2019)、自分で潜在表現をゼロから作り上げる自己学習手法 BYOL (Grill et al., 2020)、ラベル無しで知識蒸留して自己教師学習する DINO (Caron et al., 2021)、単純なシャムネットワークに基づく SimSiam (Chen and He, 2020) など、多くの手法が提案されています。
上で紹介した CLIP (Radford et al., 2021) も、画像とテキストという対象の違いはありますが、対照学習を使って訓練されています。
最近では、マスク言語モデル的な考えをコンピューター・ビジョンに使った自己教師あり学習手法である MAE (He et al., 2021) や SimMIM (Xie et al., 2021) なども話題となりました。
萩原 正人 萩原 正人
萩原 正人 萩原 正人
萩原 正人 萩原 正人
萩原 正人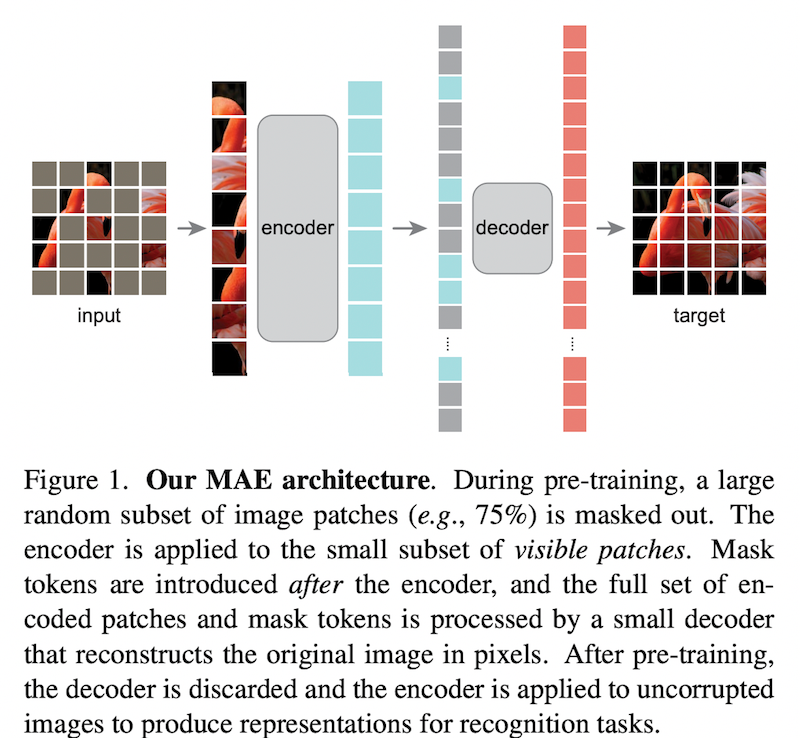
多層パーセプトロン (MLP)
2021年は、多層パーセプトロン (multilayer perceptron; MLP) が盛り上がった年でもありました。線形層と活性化関数のみを使う「元祖ニューラルネットワーク」とも言える単純なモデルでありながら、アーキテクチャに工夫を凝らし、近代的な方法によって訓練すると、驚くべき強力な性能を発揮することが示されたのです。
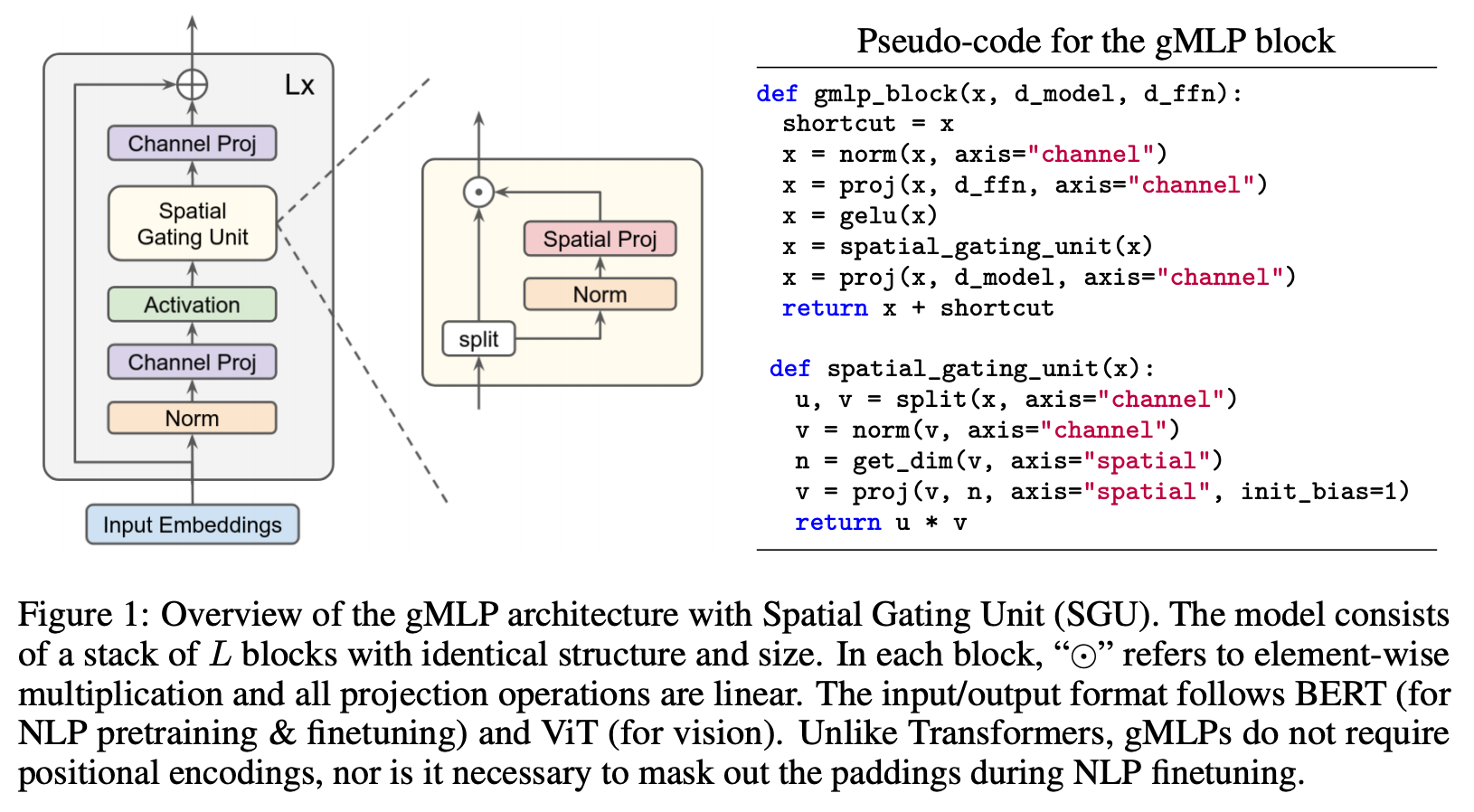
画像分類において、畳み込みニューラルネットワーク (CNN) やトランスフォーマーなどで広く用いられている注意機構などを全く用いずに、画像のパッチ化と、表現を「混ぜる」MLP を組み合わせるだけで、高い性能・速度のトレードオフを達成した MLP-Mixer (Tolstikhin et al., 2021.)、ゲート機構付き MLP を使いトランスフォーマー超えを達成した gMLP (Liu et al., 2021) を皮切りに、多数の MLP モデルが提案されています。Facebook (Meta) AI から発表された ResMLP (Touvron et al., 2021) や、RepMLP (Ding et al., 2021) などもありました。
「ついにトランスフォーマーを超えるモデルが出現するか」と盛り上がった割には、2021年12月現在においては、トランスフォーマーを置き換えて普及するまでには至っていません。最近発表された「新しいパラダイムシフトの準備はできているか」と題された MLP のサーベイ論文 (Liu et al., 2021) では、現在の訓練スケールでは、ある種の帰納バイアス (inductive bias)、すなわち、より良い解を学習しやすくするための構造上の工夫がまだまだ重要であり、かつ、MLP には入力解像度に依存してしまうという未解決の問題がある点を指摘しています。
萩原 正人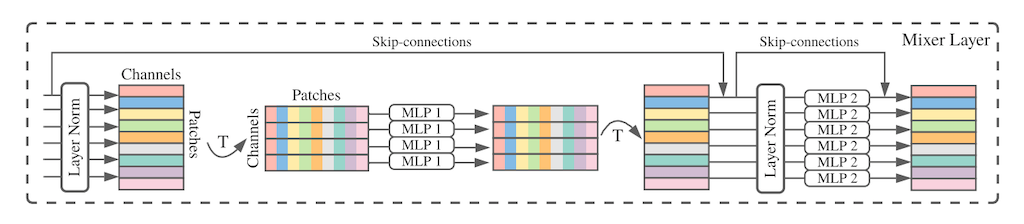 萩原 正人
萩原 正人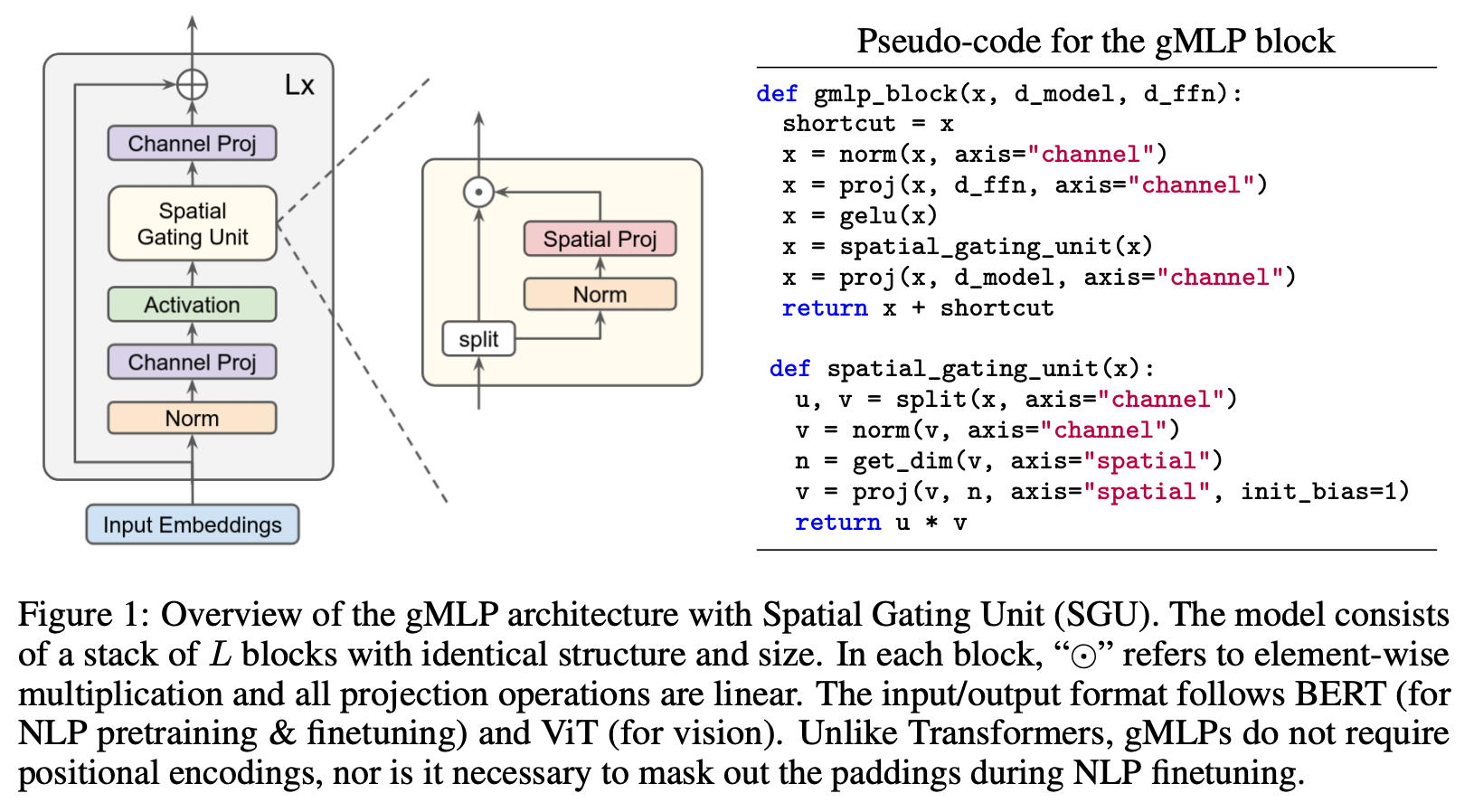
第3の深層学習ライブラリ JAX
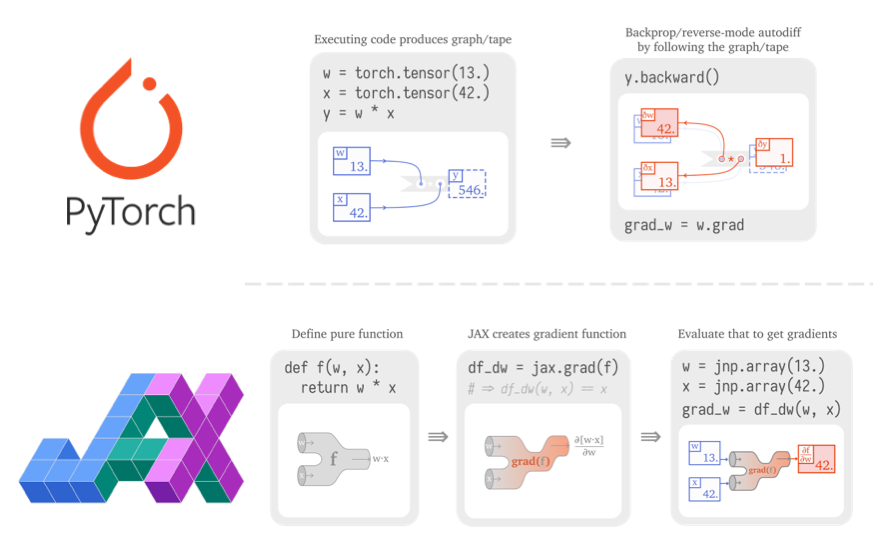
PyTorch と TensorFlow の「二強」でしらばく落ち着くと思われた深層学習ライブラリ・フレームワークですが、去年あたりから「JAX」の名を徐々に聞くようになりました。
JAX は、Google Research によって開発された機械学習用ライブラリで、「GPU/TPU 上で動く自動微分付きの Numpy」と紹介されることが良くありますが、ライブラリのコアは Numpy 的なベクトル・行列演算と、それらに対する自動微分機能です。個人的には、Numpy や PyTorch/TensorFlow などとの最大の違いは、JAX が「(純粋)関数型指向」であり、自動微分や誤差逆伝播に関する考え方が根本的に異なっている点だと思っています。
「PyTorch vs TensorFlow in 2022」と題されたブログ記事 の Hacker News のコメント欄 や、「2022年。あなたは PyTorch 派?TensorFlow 派?」と題された Reddit のスレッド などを読むと、「多くの研究者が JAX に移行し始めている」「JAX を使っている」「JAX が TensorFlow を置き換える」といったコメントが数多く見られることから、コミュニティベースでも徐々に普及が進んでいる様子が読み取れます。
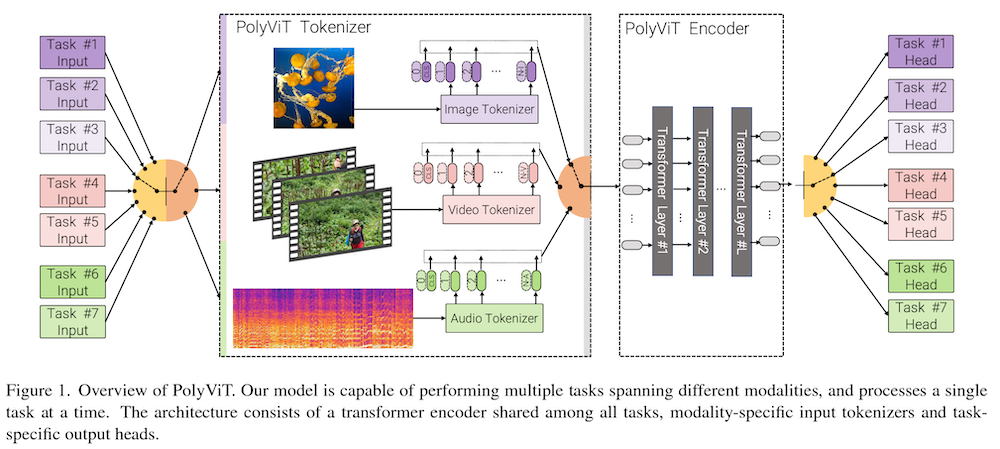
2021年現在でも、DeepMind から発表される多くの良質な研究が、実装で JAX と JAX ベースのニューラルネット・ライブラリ Haiku を使っています。また、JAX ベースの深層学習ライブラリ Flax は、ビジョン・トランスフォーマーの実装や、上で紹介した MLP-Mixer の公式実装 でも採用されています。最近では、Google から、JAX ベースのコンピューター・ビジョン用ライブラリである SCENIC (Dehghani et al., 2021) が発表され、画像・ビデオ・音声タスクをビジョン・トランスフォーマーで統一的に解く PolyVit (Likhosherstov et al., 2021) の実装などにも使われています。
自然言語処理 (NLP) の分野でも、NLP 用フレームワークとして人気の高い HuggingFace Transformers でも Flax が公式に採用されていたり、「現時点でオープンソースで利用できる最強の言語モデル」とも言える GPT-J が、JAX ベースのニューラルネット・ライブラリ Haiku と、JAX の並列化機構 xmap を使ったモデル並列化を使っていたりします。今年の6月に発表された Cloud TPU VM によって TPU が使いやすくなったのも普及を後押ししています。
機械学習ライブラリは、ネットワーク効果によって、ある臨界点を超えると瞬く間に普及する傾向があります。「2022年は JAX の年」になるか、今後の発展が楽しみです。
萩原 正人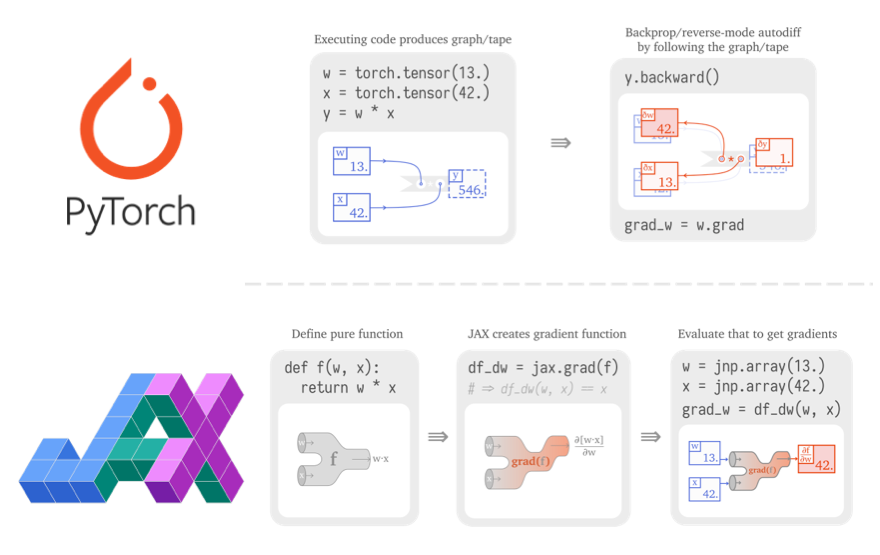 萩原 正人
萩原 正人
拡散モデル
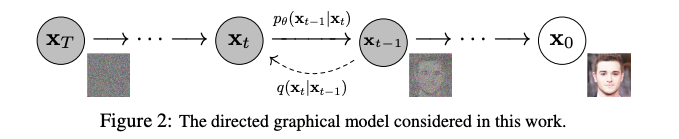
データに徐々にノイズを加え、その過程の逆を学習することにより画像や言語を生成する「拡散確率モデル」もしくは単に「拡散モデル (diffusion model)」。「画像生成で GAN を超えた」「尤度ベースで SOTA」「言語生成にも適用可」などの非常に画期的な手法・論文が次々と発表されて盛り上がっており、2021年の大きなトレンドの一つと言えるでしょう。
拡散モデルの基礎的研究が盛り上がったのは 2019年〜2020年にかけてでした。「どちらに行けばデータが密か」を示すベクトル場であるスコアを用いた「スコアマッチング」に基づく生成モデル (Song and Ermon, 2020) と、拡散確率モデルを用いた高品質な画像生成手法 (Ho et al., 2020) を皮切りに、画像生成を中心に拡散モデルの応用研究が盛り上がりました。
一方、自己回帰モデルなど他の尤度ベースの手法と比べて良い尤度を達成できないという問題がありました。2021年には、この問題に対して、OpenAI から拡散モデルの尤度を改善する論文 (Nichol and Dhariwal, 2021) と、「画像生成において、拡散モデルが GAN を超えた」と題された同著者らの論文 (Dhariwal and Nichol, 2021) が出版され、話題になりました。
また、テキスト生成・離散データに拡散モデルを適用した D3PM (Austin et al., 2021) や、音声生成に応用した DiffWave (Kong et al., 2020) や WaveGrad (Chen et al., 2020) など、他のモダリティへの応用も進んでいます。
最後に、最近では、上述の VQGAN+CLIP を使った画像生成と同様に、拡散モデルをテキストからの画像生成に応用した「CLIP 誘導拡散モデル (clip guided diffusion)」も出現しています。
萩原 正人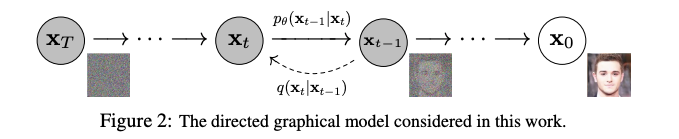 萩原 正人
萩原 正人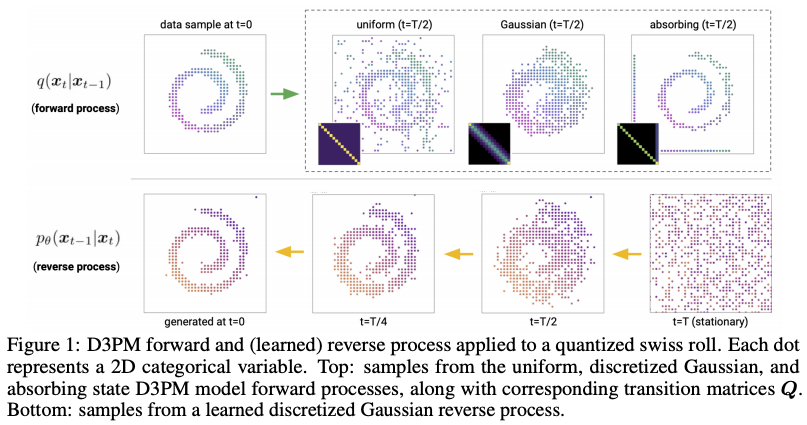
データ・セントリックな AI
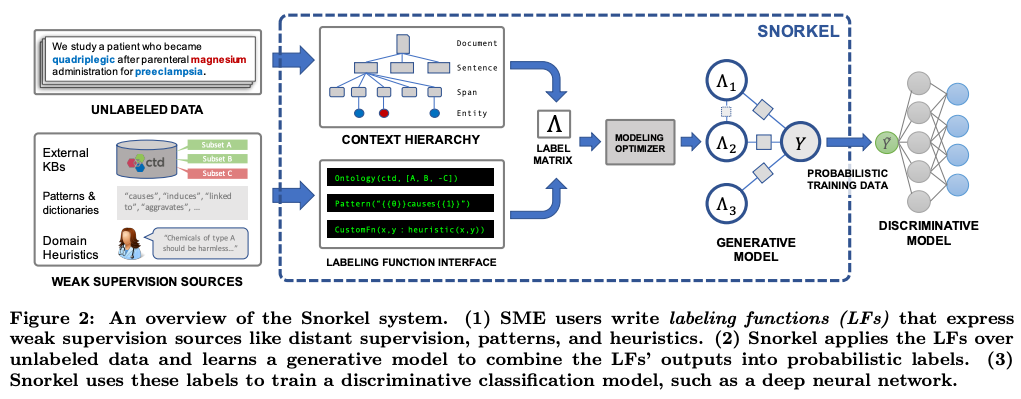
モデル中心だったこれまでの AI 開発の考えに疑問を呈し、データを中心に据える「データ・セントリックな AI」が新たにトレンドとなっています。
伝統的にも、データを中心に据える「データ・プログラミング」の手法 (Ratner et al., 2016, Ratner et al., 2017) があり、その技術を元に生まれたスタートアップ Snorkel.ai は、評価額 $1B (1千億円以上) を達成しユニコーンの仲間入りを果たしています。
「データ・セントリックな AI」の今年の立役者は、何と言っても DeepLearning.ai / Landing.ai をリードする Andrew Ng 氏でしょう。今年の3月に公開された A Chat with Andrew on MLOps: From Model-centric to Data-centric AI というトーク・セミナーにおいて、「データ・セントリックな AI」を明確なコンセプトとして提唱し、急速にその考えが広まっています。
本セミナーで、Ng 氏は、主導したあるプロジェクトを紹介しています。コンピューター・ビジョンを使って製品の欠陥を検出するシステムを開発していました。2週間の開発期間の後、データを固定してモデルを改善した場合には精度向上が得られなかった一方で、モデルを固定してデータを改善した場合、16.9% の性能向上が得られたということです。
また、Landing.ai / DeepLearning.ai 主催で、データ・セントリックな AI コンペ も開かれました。標準データセットをダウンロードし、モデル側を改善する Kaggle 等における通常のコンペの全く逆、すなわち、「モデルを固定し、データの側を改善することにより結果を向上させる」タイプのユニークなコンペです。今年の後半には、国際会議 NeurIPS 2021 に併設してデータ・セントリック AI ワークショップも開かれました。「標準ベンチマークのテストデータも間違いだらけ」であることを示した論文 (Northcutt et al., 2021) も話題となりました。
「AI にとって、データが大切」というのは、今さら言うまでもないかもしれません。実世界の問題に AI を応用する際には、「データの改善」と「モデルの改善」を天秤にかけ、データの改善の費用対効果が高いことは、多くの方が実感していることでしょう。しかし、今年に入って、これを「データ・セントリックな AI」という明確なコンセプトを打ち出すことによって、その考えを普及させた功績は大きいと思います。
萩原 正人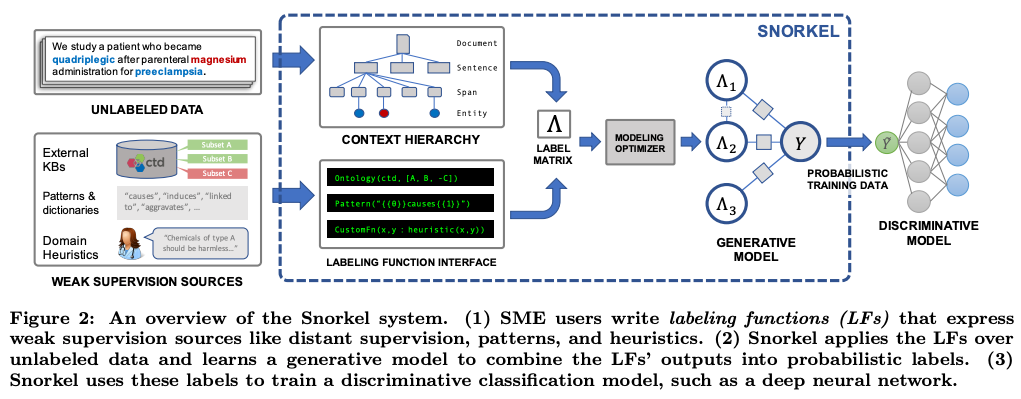
音声の教師無し表現学習
2021年は、音声(スピーチ、オーディオ、音楽)に対する教師無し表現学習が大きく躍進した年でもありました。
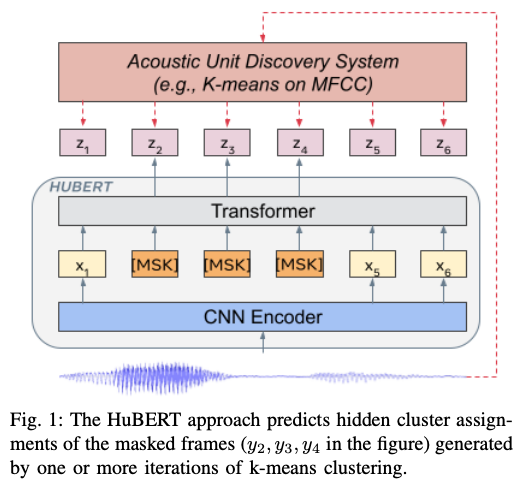
2020年から、wav2vec 2.0 (Baevski et al., 2020) をはじめとし、音声の自己教師あり学習がさかんに研究され、様々なタスクに応用されてきました。テキストや画像などと同様に、アノテーションの無い大量のデータを集め、そこから事前学習することによって、音声認識など様々なタスクの性能が示されたのです。その勢いは、2021年になっても衰えるところを知りません。クラスタリングに基づくシンプルな離散コードから高品質な音声表現を事前学習する HuBERT (Hsu et al., 2021) をはじめとし、音声パッチをマスクすることによって事前学習する SSAST (Gong et al., 2021)、スピーチ・環境音・音楽の全てに汎用的な音声表現を学習する手法 (Wang et al., 2021) などが提案されています。
音声の表現学習手法が強力になっていくのに伴って、それらの手法に基づいた教師無しの音声タスクも様々なブレイクスルーがありました。
今年の中頃には、ラベル無しで音声認識を実現した Facebook の wav2vec-U (Baevski et al., 2021) が発表され、注目を浴びました。ここでも、wav2vec 2.0 によって学習された強力な音声表現が元となっています。また、スピーチの処理において、テキストに全く頼らない「テキストレスな NLP」に関する手法も今年になって急速に発展しました。音声入力のみから言語生成する GSLM (Lakhotia et al., 2021)、離散潜在コードを使って音声から音声に直接翻訳する手法 (Lee at al., 2021a, Lee et al., 2021b) などが代表的な手法です。世界には書き言葉を持たない言語が多数存在しており、それらの処理に対する応用が期待できます。
これらの音声に対する教師無し表現学習手法のほとんどが、Facebook/Meta AI から発表されており、他の研究機関等と比べて頭一つ抜けている印象があります。
萩原 正人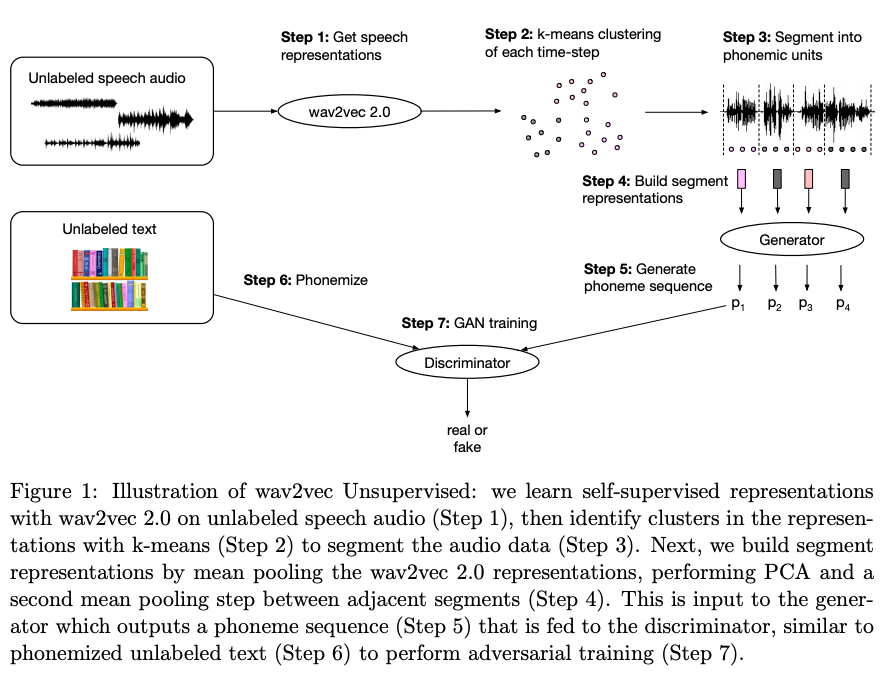 萩原 正人
萩原 正人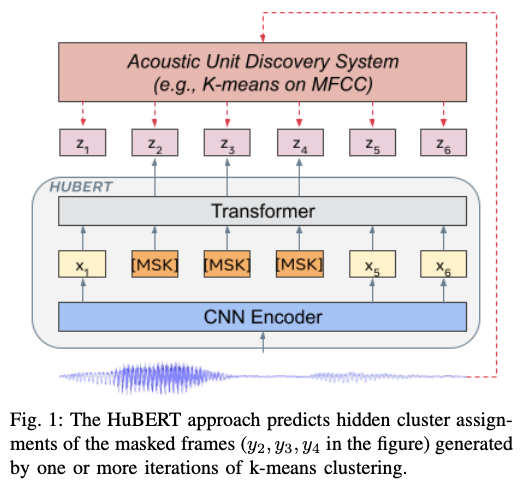 萩原 正人
萩原 正人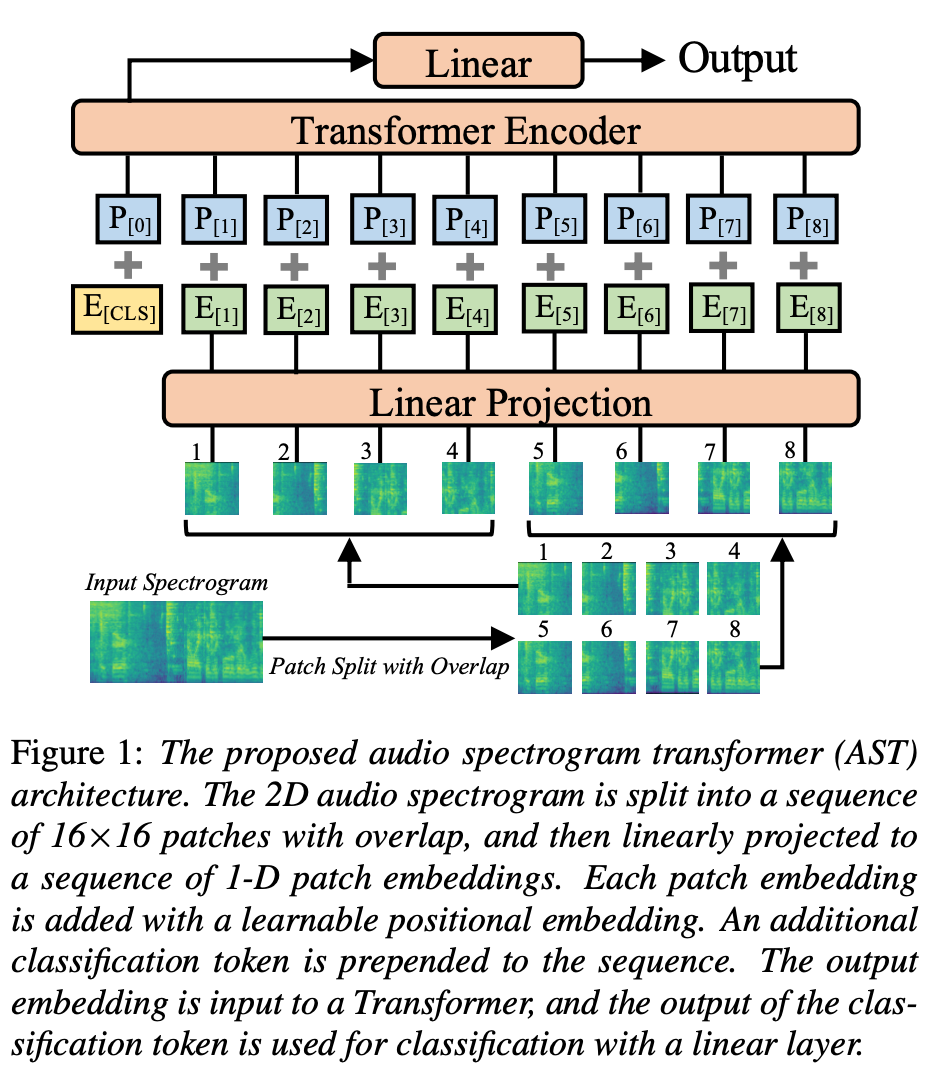
巨大言語モデル、指示チューニング
2020年に業界に衝撃を与えた GPT-3 が発表されてしばらく経ちますが、その後も巨大言語モデルの研究開発は着実に進められています。
今年に入って、大規模なデータセットやモデルを開発する草の根的な AI 研究者・開発者コミュニティである EleutherAI (イルーサー AI) が、「現時点で使える最強のオープンソース言語モデル」と言って間違いない言語モデル GPT-J-6B (60億パラメーター) をリリースしました。GPT-J-6B は、上述したように、JAX/Haiku を使って実装されています。また、AI21 Labs (イスラエルの自然言語処理スタートアップ) から超巨大言語モデル、Jurassic-1 (Lieber et al., 2021) もリリースされました。GPT-3 とほとんど同規模 (パラメータ数 178B) の言語モデルでありながら、様々な工夫が施されています。さらに、12月には、280B パラメータの最新大規模言語モデル Gopher (Rae et al., 2021) が DeepMind からリリースされ、様々な自然言語理解タスクにおいて、GPT-3 の性能を上回ることが示されました。
2021年現在、GPT-3 はもはや「最新の大規模言語モデル」ではなく、新しいモデルや様々な改善手法を比較する対象である「ベースライン」として用いられているのです。
また、上記の研究のように、単にサイズを大きくしたり細かな工夫を加えるだけでなく、大規模言語モデルをどのように上手く使って対象となるタスクを上手く解くか、という工夫に関する研究開発も進んでいます。「指示」を使って大規模言語モデルをチューニングし、ゼロショット汎化能力を高める FLAN (Wei et al., 2021)、多数のタスクで大規模系列変換モデルをチューニング、ゼロショット汎化能力を高める T0 (Sanh et al., 2021)、事前学習と大規模マルチタスク学習を組み合わせた ExT5 (Aribandi et al., 2021) などが代表的な論文です。
なお、これらの手法のいくつかは、GPT-3 的な、トランスフォーマー・デコーダーのみを用いた言語モデルではなく、T5 (Raffel et al., 2019) のようなエンコーダー・デコーダーからなる系列変換モデルに基づいています。2021年は、マルチリンガル版の T5 である mT5 (Xue et al., 2021) やバイト列を直接扱える ByT5 (Xue et al., 2021) も発表され、これらのモデルの利用も拡大しています。
萩原 正人萩原 正人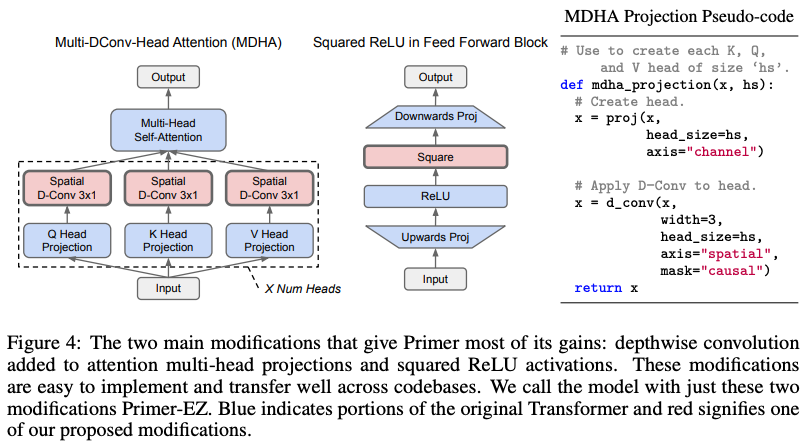 萩原 正人
萩原 正人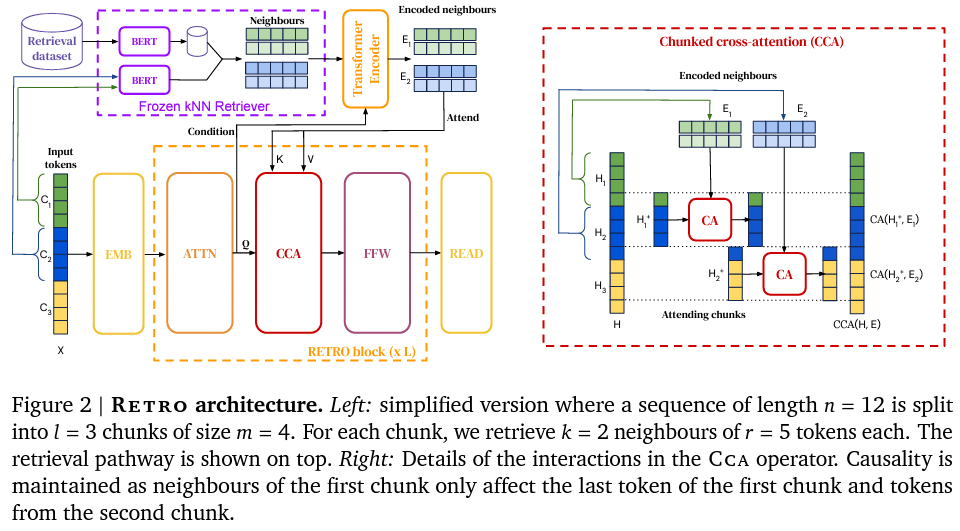
ノンパラメトリックな手法
近年の大規模な言語モデルは、知識を全てニューラルネットワークの重みのようなパラメータとして表現するものがほとんどです。これらの「パラメトリックな」モデルは、驚くべきほど大量の知識をパラメータとして保持できますが (例: Roberts et al., 2020)、知識を大量に必要とする質問応答のようなタスクにおいては、性能を向上させるためにモデルのサイズを指数関数的に大きくしなければならないという欠点があります。
そこで、2020年頃から、知識をモデルのパラメーターとして全て表現するのではなく、何らかの外部知識として表現して利用する「ノンパラメトリック」手法が近年さかんに研究されています。これらのモデルは、外部知識を検索するので、「検索ベース」の手法とも呼ばれます。
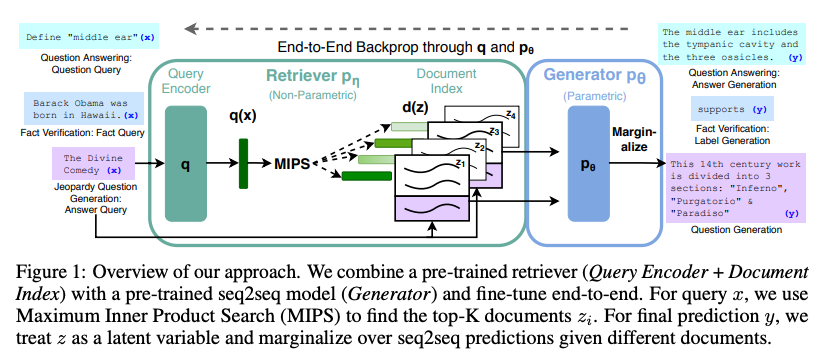
代表的な手法として、近傍検索に基づく言語モデル (kNN-LM, Khandelwal et al., 2019)、近傍検索に基づく機械翻訳 (kNN-MT, Khandelwal et al., 2020)、検索を用いた言語生成 RAG (Lewis et al., 2020, 上図)、検索+パラフレーズを使って事前学習する MARGE (Lewis et al., 2020) 等があります。
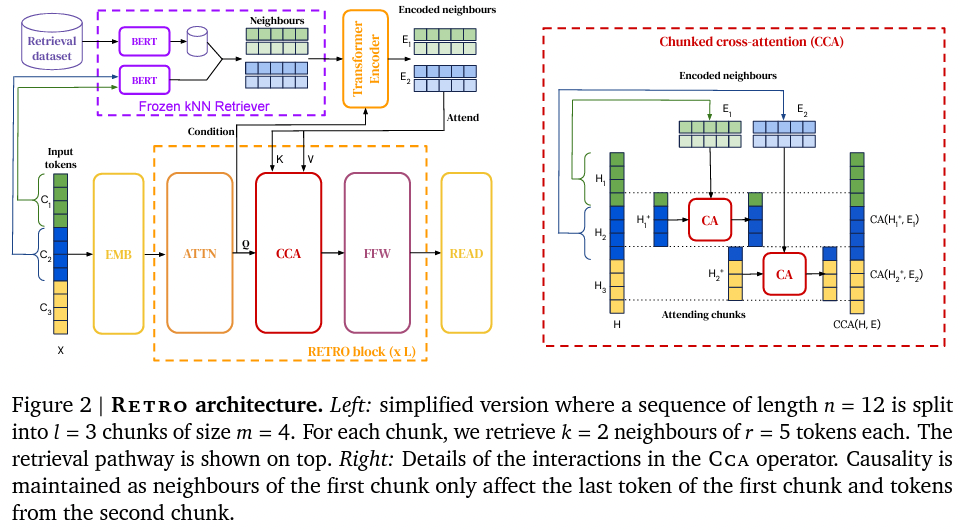
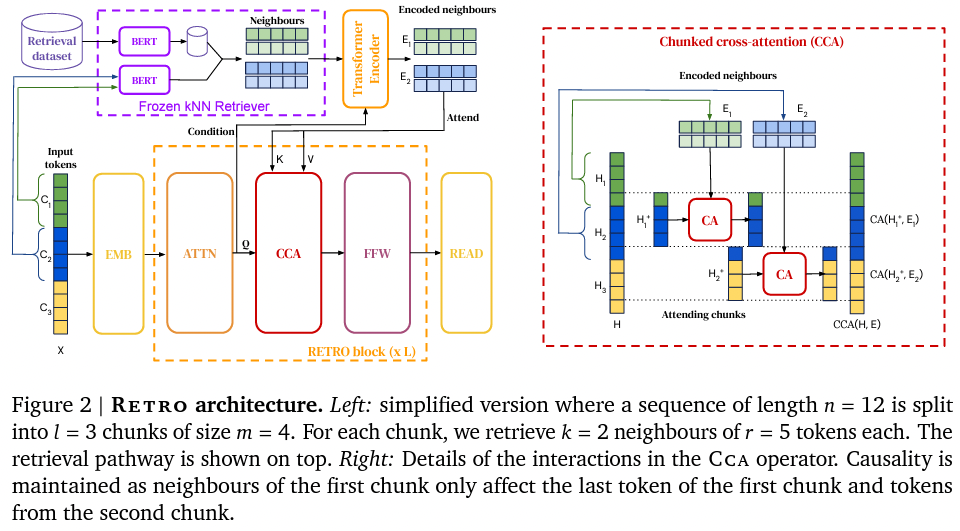
また、最近では、2兆トークンからなる DB を検索する大規模言語モデル RETRO (Borgeaud et al., 2021) が発表されました。これらのモデルは、パラメータ数を増やすことなく、言語モデルの性能を上げることができる、DB を後付けで追加・置換できる、などの利点があります。
萩原 正人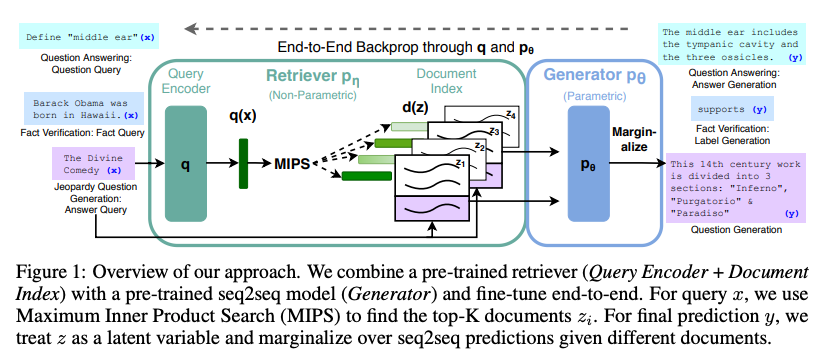 萩原 正人
萩原 正人人工知能で進む「分野の大統一」
最後に、近年の人工知能の最も重要なトレンドである「分野の大統一」に触れておきましょう。2021年現在、人工知能の分野では「大統一 (great consolidation)」が進みつつあります。最近、Andrej Karpathy 氏 (Tesla AI のトップ) が「現在進行形で進んでいる AI 分野の統合がすごい」という内容のツイートを投稿しています。現在の業界の状況を端的に良く表していますので、以下で抄訳します:
The ongoing consolidation in AI is incredible. Thread: ➡️ When I started ~decade ago vision, speech, natural language, reinforcement learning, etc. were completely separate; You couldn't read papers across areas - the approaches were completely different, often not even ML based.
— Andrej Karpathy (@karpathy) December 8, 2021
10年ほど前は、画像・音声・言語・強化学習で、自分が詳しくない他の分野の論文を読むことはほぼ不可能でした。アプローチが全く異なっていたからです。2010年代から、機械学習、特に、ニューラルネットワークベースの手法が徐々に普及し始めました。分野ごとに異なるアーキテクチャを使ってはいましたが、論文が少しずつ似たものになってきました。2年ほど前から、どの分野でも、トランスフォーマー・ベースのモデルが普及し始め、アーキテクチャ的にも差異がほとんど無くなりました。分野内でも、分類・検出・セグメンテーション・生成など、昔はタスクごとに手法が異なっていましたが、今はほとんど変わりません。
現在において、分野毎に異なるのは、データと、入力・出力をどうやって変換するか、位置エンベディングとマスクをどうやって設計するか、ぐらいです。異なる分野であっても、論文や研究者・良いアイデアは、全て関係しています。改善手法や新しいアイデアはすぐに分野を超えて共有されます。
人間の大脳新皮質は、モダリティにかかわらず非常に均質な設計になっています。もしかしたら、自然も同じようなアーキテクチャにたどり着いたのかもしれません。このような大統一によって、ソフトウェア・ハードウェア・インフラの重要性がさらに増し、それらによってさらに進歩が加速します。
自然言語処理の分野で機械翻訳用に提案された「元祖」トランスフォーマー (Vaswani et al., 2017) は、その強力なスケール性と汎化能力により、またたく間に他のタスクや分野にも広がりました。
CNN ベースの強力なモデルが既に普及していたコンピューター・ビジョンの分野でも、画像をパッチに分割してビジョン・トランスフォーマー (Dosovitskiy et al., 2020) や DeiT (Touvron et al., 2020)を皮切りに、一気にトランスフォーマーの波が押し寄せた感があります。同様のアイデアは、スペクトグラムをパッチに分割して音声解析する SST (Gong et al., 2021) を通じて音声分野にも広まり始めました。
これらのトランスフォーマー・ベースの手法によって、入力を分類できるようになりました。一方、自然言語処理分野の GPT のように、新しい画像や音声をトランスフォーマーを使って生成・変換するにはどうしたら良いでしょうか?答えは簡単で、「画像や音声などの入力を離散的なトークンに変換し、そのトークン列を言語のようにトランスフォーマーによってモデル化する」です。この枠組み、具体的な名前が付いていませんが、ここ2年ほどの深層学習業界で最も重要なトレンドだと個人的には思っています。
この離散トークン列への変換は、潜在表現を離散トークンに結びつける自己復号器 (オートエンコーダー) である VQ-VAE (van den Oord et al. 2017) が使われるのが一般的で、dVAE (離散変分自己符号化器; discrete variational autoencoder) と呼ばれることもあります。この仕組みは、VQGAN (Esser et al., 2020)、 DALL·E (Ramesh et al., 2021)、CogView (Ding et al., 2021)、NÜWA (Wu et al., 2021) などの画像生成モデルで広く使われています。また、時間軸に拡張することによってビデオを生成する VideoGPT (Yan et al., 2021) も提案されています。
また、音楽の分野では、離散化とトランスフォーマーを組み合わせて音楽をオーディオから直接生成する Jukebox (Dhariwal et al., 2020)、音声の分野では、前述の HuBERT (Hsu et al., 2021) の表現を使った音声生成 (Lakhotia et al., 2021) にも同様の仕組みが使われています。
なお、入力を離散トークン化すると、自然言語処理の分野でポピュラーな BERT のマスク言語モデルように、一部をマスクして文脈から復元することにより、高品質な表現を学習するのが容易になります。この仕組みを利用して、ビジョン・トランスフォーマーを BERT 的に事前学習する BEIT (Bao et al., 2021)、ビデオに対する BERT 的な事前学習 VIMPAC (Tan et al., 2021) などが提案されています。
入力を離散トークン化する手法は、VQ-VAE だけではありません。前述の HuBERT (Hsu et al., 2021) や wav2vec-U (Baevski et al., 2021) では、学習された表現に対して k-means を実行して得られたクラスタを単に使っています。他にも、音声に対する可変レート離散表現を学習する SlowAE (Dieleman et al., 2021)、離散コサイン変換 (DCT) を使って画像を離散・スパース表現する手法 (Nash et al. 2021) などが提案されています。
最後に、トランスフォーマーの波が押し寄せているのは、言語・画像・音声などのドメインだけではありません。表形式データに自己注意機構を使った TabTransformer (Huang et al., 2020) や NPT (Kossen et al., 2021)、トランスフォーマーを使った推薦システムのためのフレームワーク Transformer4Rec (Moreira et al., 2021)、強化学習をトランスフォーマーの枠組みでモデル化する Decision Transformer (Chen et al., 2021) など、様々な分野・タスクでトランスフォーマーが使われています。
一方、画像認識の分野では最近、「重要なのはパッチ化であって、アーキテクチャ自体ではない」という趣旨の論文 (Anonymous, 2021) や、「トランスフォーマーの自己注意機構をプーリング層に変えても問題無い」という結果 (Yu et al., 2021) など、アーキテクチャの前提を疑うような研究も出てきています。また、前述した多層パーセプトロン (MLP) ベースのモデルに関する研究も着実に進んでいます。
現状のところ、系列化できて十分な (事前) 学習データ量が手に入るタスクであれば、「とりあえず何でもトランスフォーマー」の傾向はしばらく続きそうですが、その覇権がいつまで続くか、今後も目が離せませんね。
萩原 正人 萩原 正人萩原 正人
萩原 正人萩原 正人 萩原 正人
萩原 正人