ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
昨年の5月に、カーネギーメロン大学の言語技術研究所 (LTI) が主催で、低リソース自然言語処理ブートキャンプ (CMU Low resource NLP Bootcamp) が開催されました。カーネギーメロン大の一線の研究者による、低リソース自然言語処理のチュートリアルと、実際のデータセットやライブラリを使った演習が盛りだくさん。内容は「ニューラルネットワーク一辺倒」という感じではなく、古い技術から広く浅く、事前知識の無い人にも分かりやすく説明してくれる形式になっています。また、言語学や外国語に興味のある人にも面白い内容だと思います。
以下では、それぞれの講演を、まとめ訳と共に紹介します。
(特に、最後の講義 8 では、音声認識の仕組みを、数式をほとんどつかわず直感的に説明していて、個人的にはかなり感銘を受けました)
講義 1. NLP タスク
-
最も話されている言語が、資源がたくさんあるとは限らない
- 例:(ベンガル語、インドネシア語)
- 他にも 6,000以上の言語がある
-
自然言語処理のシステムを開発する方法
- ルールベース (epitran 発音推定システム)
- 機械学習 類似した言語の訓練データを使う
-
機械学習ベースの NLP システムを評価する方法
- 訓練セット、開発セットで検証、テストセットで評価
- 実際には、訓練セットが手に入らない事がある→ゼロショット学習
-
機械翻訳
- 対訳データから学習
- タスクとしてはシンプル。系列変換
- fairseq, Joey NMT
- 対訳データを探すのは比較的容易 (ニュース、政府の公式文書、Wikipedia, 字幕、宗教書)、対訳コーパスサイト Opus
- 質問: 言語学者は役に立つか? 答え: もちろん。言語の前処理、データの作成、結果の解析、etc.
- 機械翻訳の評価: 人手評価と自動評価 (BLEU, METEOR, etc.) 完全な自動評価は難しい
-
音声認識
- 音声+書き起こしのデータから訓練
- 異なる話者、ノイズ、会話のデータ
- ニュース、オーディオブック、字幕
- CMU Wilderness
- Mozilla Common Voice
- パイプライン: 特徴量抽出 → エンコーダー → デコーダー (CTC) (ESPNet 色々なモデルを実装)
- 評価: 単語誤り率, 機械翻訳の評価より単純
- 音声+書き起こしのデータから訓練
-
音声合成
- 訓練データ: 同じ話者、キレイ、明瞭な発話のデータ
- パイプライン: エンコーダー → デコーダー → ボコーダー
- 評価: 人手評価がメイン
-
質問応答 (QA)
-
会話システム
- タスク志向会話 vs 自由会話
- 会話データセットのサーベイ
- モデリング
- 文脈をエンコード
- 信念トラッキング、データベースアクセス
- 発話生成
- 性能評価
- タスク志向: タスク完成率, 完成までの時間, ユーザー満足度
- 自由会話: リファレンス(回答)とのオーバーラップはうまく行かない。人手評価が主流
- パーソナルアシスタント (Google アシスタント)
- 音声認識、質問回答、音声合成
-
テキスト分類
- 感情分類, トピック分類, 言い換え同定, テキスト含意分類 (自然言語推論)
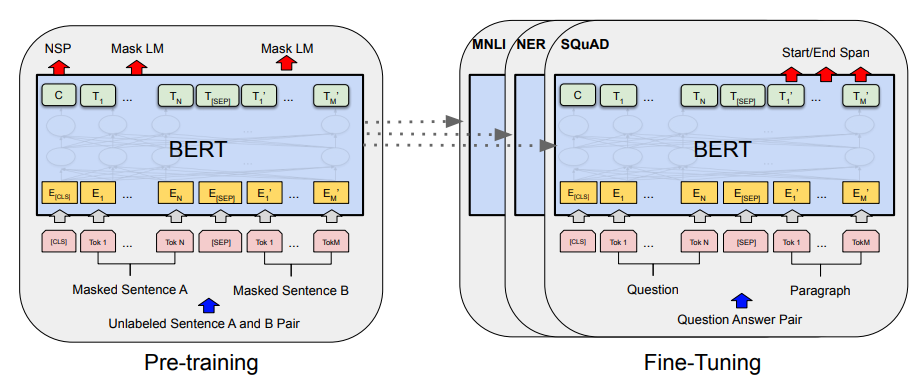
- BERT によるエンコーディング → 分類
-
テキスト分析
- 系列ラベリング → 単語ごとにタグを付与 (例: 品詞推定、固有表現抽出)
- 構文解析 → テキストから構文木を推定
- Universal Dependencies Treebank
- 評価: タグの精度、固有表現の F値、係り受け解析の UAS/LAS, 構文解析のフレーズ F値
講義 2. 言語学 (音声学・音韻論・形態論)
-
言語の構造
- 言語には豊かな構造がある
- 言語の構造を科学的に研究するのが言語学
- 話し言葉は書き言葉より重要 話し言葉が先にあった
- 複数のレベルの表現 (音声学 → 音韻論 → 形態論 → 構文 → 意味 → 談話)
-
音声学
- 調音音声学 (発音に関する音声学)
- 人間が音声を生み出す仕組みを研究する
- 声道のどこで調音するか、どのように調音するか、で分類
- 母音: 前後、広さ、円唇の3軸で分類
- 子音: 破裂音、鼻音、摩擦音 etc. 有声 vs 無声
-
国際音声記号 (IPA)
- あらゆる言語の音を4つのパラメータで記述し、記号を付与
- 多くの言語が声調言語 (ピッチで単語を区別する) vs イントネーション (ピッチでニュアンス等を表現)
- なぜ正書法をそのまま使わないか? 英語や中国語など、正書法と音が乖離している
- 変換: ルールベース (Unitran, Epitran)、機械学習 (英語やアラビア語など、関係が複雑な言語)
- 用途: 言語の記録、アノテーション、比較、音声認識、言語間の転移学習
-
音韻論
- im-possible, in-tolerable, in-conceivable, il-legal, ir-regular
- 異音: 英語の破裂音は、場所によって有気・無気が変わる (例: pin, nip, spin) → 音は別だが、音素は同じ
- 韓国語の r/l は、同じ音素だが、場所によって音が変わる
- 同じ形態素の音素が変わる 例: 英語の複数形、三単現の -s (/s/ vs /z/)
- 音韻学者は、なるべく単純で多くの現象を説明できるルールを好む (同化現象)
- 音素は、それぞれ独立ではない(素性によって記述できる)
- Python ライブラリ PanPhon
- なぜ役に立つか? 固有表現の発音は言語間であまり変わらない (例: 「新疆」の発音)
-
形態論
- listeme (リストの要素)、語彙素 (lexeme)、語 (word)
- 例: タガログ語 接頭辞 ma- を付けて単数に、その語の音節を重ねて複数形に
- 例: アラビア語 語幹 ktb → katab, kutib, kattib, etc. 語幹+パターン 形態論 (最も複雑)
- 派生形態論 (例: -er, re-, -ly) vs 屈折形態論 (例: 格, 数, 性, etc.)
- 形態論の分類 (孤立語・膠着語・屈折語)
- 抱合語: 目的語の情報などが動詞によって表現される言語
講義 3. 機械翻訳
-
はじめに
- 機械翻訳を暗号解読問題ととらえる (Warren Weaver)
- 対訳例を見ることによって翻訳が可能
- ロゼッタストーン: 古代ギリシア語、エジプト語で同じ内容が書かれている
-
雑音のある通信路モデル
- $ \arg \max_e p(e|f) = \arg \max_e p(e) \times p(f|e) $ (ベイズ則の適用)
- $ p(e) $ = 言語モデル, $ p(f | e) $ = 翻訳モデル
- 翻訳モデル: 適合性 (意味の一致) を表す。
- どう計算するか?文を単語に分解し、翻訳される回数を数える
- 単語アラインメント (どの単語がどの単語に対応するか) を考え、単語が独立に翻訳されると仮定
- 単語の並び替え、欠落、挿入など、1対1に対応しない
-
単語翻訳モデル
- IBM Model 1 (最も単純な単語翻訳モデル)
- パラメータ $p(e|f)$ をどうやって学習するか? アライメントと対訳の確率を求めるのは、鶏と卵の問題
- 対訳コーパスから EM アルゴリズム で繰り返し的に求める
-
フレーズベース機械翻訳
- 複数の単語 (フレーズ) をまとめて翻訳できるようにする
- 入力文をフレーズに分解し、最もスコアの高い経路を求める
- 単語アライメントに、事前分布を仮定 (英語とフランス語のように語順の似た言語)
- 文法を考慮
- 実習: fast_align を使った単語アライメント
-
評価
- どのように翻訳の良さを判断するか
- BLEU スコア: 翻訳文、参照訳とのオーバーラップ (ユニグラムの精度) を数える
- 問題: ユニグラムの精度だけを使うと、"the the the the the" のような文も高く評価されてしまう
- 問題: 翻訳文が短いと、高く評価されてしまう → 短さに対するペナルティ
-
ニューラル機械翻訳
- 2014年まで: 単語とフレーズ単位の機械翻訳が主流
- 2014年から: ニューラル機械翻訳
- ニューラルモデル: 人間の脳のニューロンに着想。線形の重み+非線形変換。これを重ねたものが深層モデル
- 系列: リカレントニューラルネットワーク (RNN)
- 言語の表現: ワンホット・ベクトル vs 埋め込み表現
- 訓練: 入力から予測 $y^*$ を出力し、損失関数 ${\rm loss}(y, y^*)$ を計算。誤差逆伝播法を使って重みをアップデート。
-
ニューラルモデル
- エンコーダー (符号器) とデコーダー (復号器) の組み合わせ
- 問題: 長い文があると、すべての意味を固定サイズのベクトルに詰め込むのが難しい → 注意機構
- 注意機構: デコーダーの各ステップにおいて、エンコーダーの潜在表現を参照して、文脈ベクトルとして使う
- トランスフォーマー: 入力を順に処理するかわりに、自己注意機構を使い、自分自身から作った文脈ベクトルを使う
- どのモデルが一番良いかは、データの量や言語の種類による
-
ニューラル機械翻訳の研究トレンド
- 文脈の考慮
- 形態論が複雑な言語への適用
- コーパスの確率のかわりに、翻訳の質を最適化
- マルチリンガルモデル
- 文書翻訳
- ドメイン適用と頑健さ
講義 4. 言語学 (統語論・形態統語論)
-
品詞
- 文法的な単語のカテゴリ (名詞、動詞、形容詞 etc.)
- 例: 名詞句: 限定詞+名詞
- どう定義する?「名詞はモノで、動詞は動作」とすると、「なぜ「アイデア」はモノで、「望む」は動作なのか」という疑問が発生してしまう
- 単語の「振る舞い」で定義する。例: 名詞は複数形になる、限定詞が付く、主語や目的語になる、形容詞で修飾できる
- Stanford Parser による分かち書き+品詞付与の例
- 下位分類がある 例: 代名詞、動名詞、不可算名詞 etc.
- 完全に離散的に分類できるものではない (例: like は形容詞か前置詞か)
- Penn Treebank で使われている品詞 (英語)
- Google の Universal タグセット (言語非依存の17個のタグ) 言語間の転移に最適化されているが、言語学的に正しいかは疑問
- 品詞は普遍的か? 言語によっては、例えば名詞と動詞の区別が無いものもある
-
形態統語論
- グロス (注釈) - 単語ごとに対象言語で語釈を書く
- 英語で "they" や "in" と書くと誤解が生じる → "3.PL" や "LOC" と書く
-
形式と意味
- 動作主 (agent) が被動者 (patient) に何かした、という基本的な意味でも、言語によって表現が異なる (語順、格マーカー、一致)
- コピュラ (繋辞)
- WALS 言語を類型論によって分類したデータベース
- スワヒリ語、ヒンディー、ヨルバ語でのグロスの例
講義 5. ニューラル表現学習
-
はじめに
- テキスト → ニューラルネット → ベクトル表現
- 単語、フレーズ、文、文のペア
-
単語の表現学習
- 単語をベクトルに変換
- 意味的な合成をする関数を学習できる → 様々なタスクに有効
- シンボリック (ワンホット) vs 分散表現 (実数ベクトル)
- 教師なし vs 半教師あり
- 非文脈化 (表現が文脈に依存しない 例: word2vec, GloVe) vs 文脈化 (表現が文脈に依存 例: ELMo, BERT)
- カウントベース (PLSA, LSA, GloVE) vs 予測ベース (word2vec, NNLM)
-
単語の表現学習手法
- NNLM ... ニューラルネットで言語モデル、分散表現を副産物として学習
- word2vec ... CBOW と Skip-Gram
- GloVe ... ベクトルの内積が、共起に対応
- ELMo ... 次の単語を予測する言語モデル
- BERT ... RNN のかわりにトランスフォーマー
- 言語モデル、機械翻訳: 事前学習を使わない
- 非文脈化表現: 高速、学習が簡単、BERT が存在しない時にも使える、ドメイン適応
- 文脈化表現: 高性能、高コスト、数ショット学習
-
文の表現学習
- 文 → ベクトル表現
- 感情分析、意味マッチング、要約、機械翻訳の基礎
- 教師あり (NBOW, LSTM, トランスフォーマー) vs 教師なし (Paragraph Vector, SkipThought)
- トポロジー構造 (系列、木構造、グラフ構造)
- NBOW (Neural Bag-Of-Words) ... 単語ベクトルの単なる平均
- CNN の基礎
- トランスフォーマーの基礎
講義 6. マルチリンガル自然言語処理
-
自然言語処理
- 人間とコンピューターとのコミュニケーション (マシン語→高級言語→自然言語と進化してきた)
- 対話システムを作るために必要な技術: 音声認識、言語解析、対話処理、情報検索、音声合成
- 他の応用: 機械翻訳、情報抽出、質問応答、文書要約、感情分析、etc.
- 現在の会話システム: 退屈な会話を生成
- 音、形態素、単語、構文、意味、談話
- 難しさ: 曖昧性: "bank" (土手?銀行?) "I saw a man with a telescope." (望遠鏡を持っているのは誰か?)
-
言語の多様性
- 世界中には6,000以上の言語 (パプア・ニューギニアでは 839 もの言語) 類型論的に非常に異なる
- トークン化すらも簡単ではない(例: 中国語、ヘブライ語)
- ヘブライ語: 母音を明記しない
- ロシア語: 形態論 名詞ごとに、7つの格×単複の区別がある
- ケチュア語: 膠着語。語幹に語尾がつき、非常に長くなる
- 日本語: 構文が英語と全く逆
- 言語の方言・亜種: アメリカ英語、スコットランド英語、Hinglish (インド英語の混合)
- 言語 x ドメイン x タスク、の3次元 どのように全ての組み合わせに対してソリューションを提供するか?いくつかの軸をまとめて解決 例: マルチリンガルモデル
-
低リソース自然言語処理
- 例: 機械翻訳 高リソース=数百万の対訳ペア、低リソース=数千の対訳ペア
- 英語→フランス語→英語 と逆翻訳してもほぼ同じ。英語→スワヒリ語→英語 と逆翻訳すると意味が全く変わる
- 一般的に、訓練データの量が少ないほど、翻訳の質が悪くなる
- なぜ重要か? 翻訳、音声システム、会話、教育、災害対策 (例: ハイチ地震)、言語・文化保存
- 最新の NLP モデルは対象の訓練データを必要とする 書き言葉が無い場合も
-
新たな言語に対する自然言語処理を開発するには
- まず、どの言語か?どういった形態論的・統語的特徴を持つか?
- 訓練データは存在するか? Yes → 教師ありアプローチ
- 他の類似した言語のデータは存在するか? Yes → 転移学習アプローチ
- 単言語データは存在するか? Yes → 教師なしアプローチ
-
感情分析
- ABSA Sentiment Analysis データセットを使った多言語感情分析の例
講義 7. 音声合成
-
音声合成の歴史
- 物理的に音声を合成する機械 (von Kempelen の機械)
- フォルマント合成 → ダイフォン音声合成 → 単位選択 → 統計モデルによる波形生成 → ニューラルネットによる波形生成
- 研究を進める: ツール・データセットの開発、評価、実際のシステムに組み込む、新たな方向性を探す
-
オープンソース・ツール&データセット
- Festival 音声合成システム
- Festvox 音声作成プロジェクト
- CMU Flite 軽量の音声合成エンジン
- CMU ARCTIC 音声合成用データセット
- Blizzard Challenge 音声合成のコンペ
- 評価: 平均オピニオン評点 (Mean Opinion Score; MOS), SUS 文 (意図的に理解しにくい文)
-
音声合成手法
- 単位選択法 → 限られた分野
- ニューラルモデル (Tachotron, WaveNet) → 多くの訓練データが必要
- テキスト解析: 母音(アラビア語)、単語の分かち書き、数字の読み上げ (英語で "1996" をどう読むか)、コードスイッチなどの問題
- コーパスの設計: 発音のしやすさ、音素のカバー率、高頻度語
-
書き言葉の無い言語の音声合成
- 音声処理技術はテキストの存在を前提としている
- 表記体系が、他の言語を借りたものである例 (中国標準語 vs 上海語、スペイン語 vs ケチュア語、イラク方言 vs 標準アラビア語)
- 表記体系の統一 → 識字率の向上
- 書記素 (grapheme) ベースの生成システム (例: Unitran ユニコード文字を音素に)
- Wilderness データセット: 600以上の言語の聖書の読み上げデータセット
- クロスリンガル音素ラベリング: 他の言語の音素ラベルを使い、音声を合成
講義 8. 音声認識
-
文字列マッチング
- 2つの文字列間の「距離」を計算 → アラインしてコストを計算 (編集距離)
- コストが最小になるアラインメントを求める → 指数関数的に大きくなる
- 動的計画法: 動的時間伸縮法 (Dynamic Time Warping; DTW)
- 先頭から考えた部分文字列どうしがアラインメントされていると仮定 → 次の文字をアライン (編集距離に似ているが、1:複数の文字の置き換えを許容する)
- ベクトルの系列どうしでも同じアルゴリズム (コストの計算だけが異なる)
-
DTW と音声認識
- 単純な音声認識 (例: 数字の0〜9の桁): あらかじめパターンを録音しておき、新しい単語が来たらパターンと DTW マッチング、コストが最小のものを使う
- 音声を特徴量に変換しておく
- 単語ごとに複数のテンプレートを保持しておく
- テンプレートで全てカバーできるとは限らない → 汎化したい
- テンプレートを複数の部分文字列に均等に分割、特徴量ベクトルの平均を求める
- セグメンテーション自体を最適化したい → セグメント k-means → セグメントから求めた平均を使って、再度セグメントする → 繰り返し
- セグメントの長さがバラバラになってしまう → 挿入コストをセグメントの長さによって調整
-
隠れマルコフモデル
- セグメント k-means から学習可
- 遷移確率と出力確率を定義
- データは正規分布に従うと仮定したが、他のモデル(ニューラルネット)でも可
- コストの最小化 = 確率の最大化
- 複数の単語の認識: テンプレートをつなげて一つのグラフを作る
-
単語系列の認識
- 単語ごとに独立してテンプレートを記録 テンプレートをつなげてグラフを作る
- 単語ごとの部分グラフに分解できる → 単語をラティス構造に変更可
- 単語列の事前確率は、Nグラム言語モデルで表現する
-
Kaldi を使った音声認識システム構築の実習
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人