
ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
世界中ではおよそ 7,000 種類もの言語が話されています。近年、自然言語処理の分野では、強力なシステムやモデルが提案され、様々なタスクにおいて人間の精度に迫るものも出てきました。しかし、これらの進歩のほとんどは、英語や中国語など、資源が豊富にある (resource rich な) 言語を対象にしており、世界中で話されている言語の大多数に関しては、高性能なモデルはおろか、入力メソッドやスペルチェッカーなど、コンピューターによってそれらの言語をきちんと扱うことのできるインフラすら存在しません。
本記事では、Google DeepMind のリサーチ・サイエンティストである Sebastian Ruder 氏による Why You Should Do NLP Beyond English という記事をベースとして、英語だけを対象にして自然言語処理の研究開発をするのがなぜ問題なのか、について、関連文献などを紹介しながら追ってみたいと思います。
言語間の格差
近年の機械学習・自然言語処理モデルの多くは、訓練するためにラベル付けされた大量のデータを必要とします。一方で、大規模なラベル付きのデータは、英語、中国語、フランス語のような、一部の「勝ち組」言語にしか存在しません。このことが、言語間の「格差」をさらに大きくする原因にもなっています。
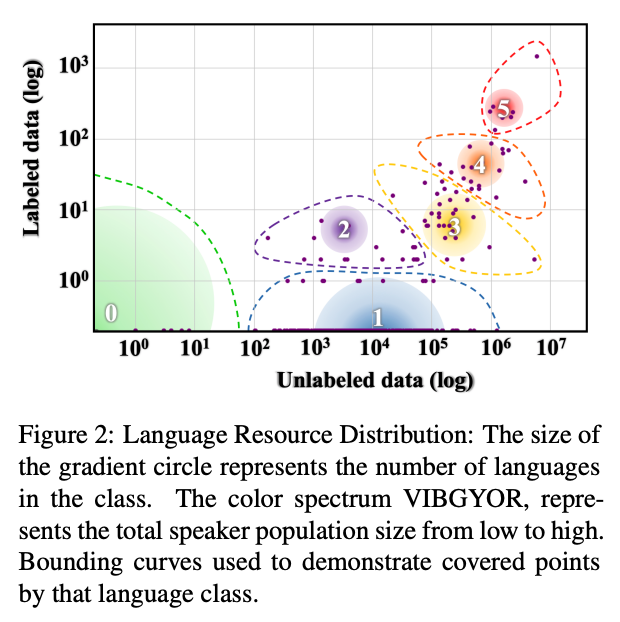
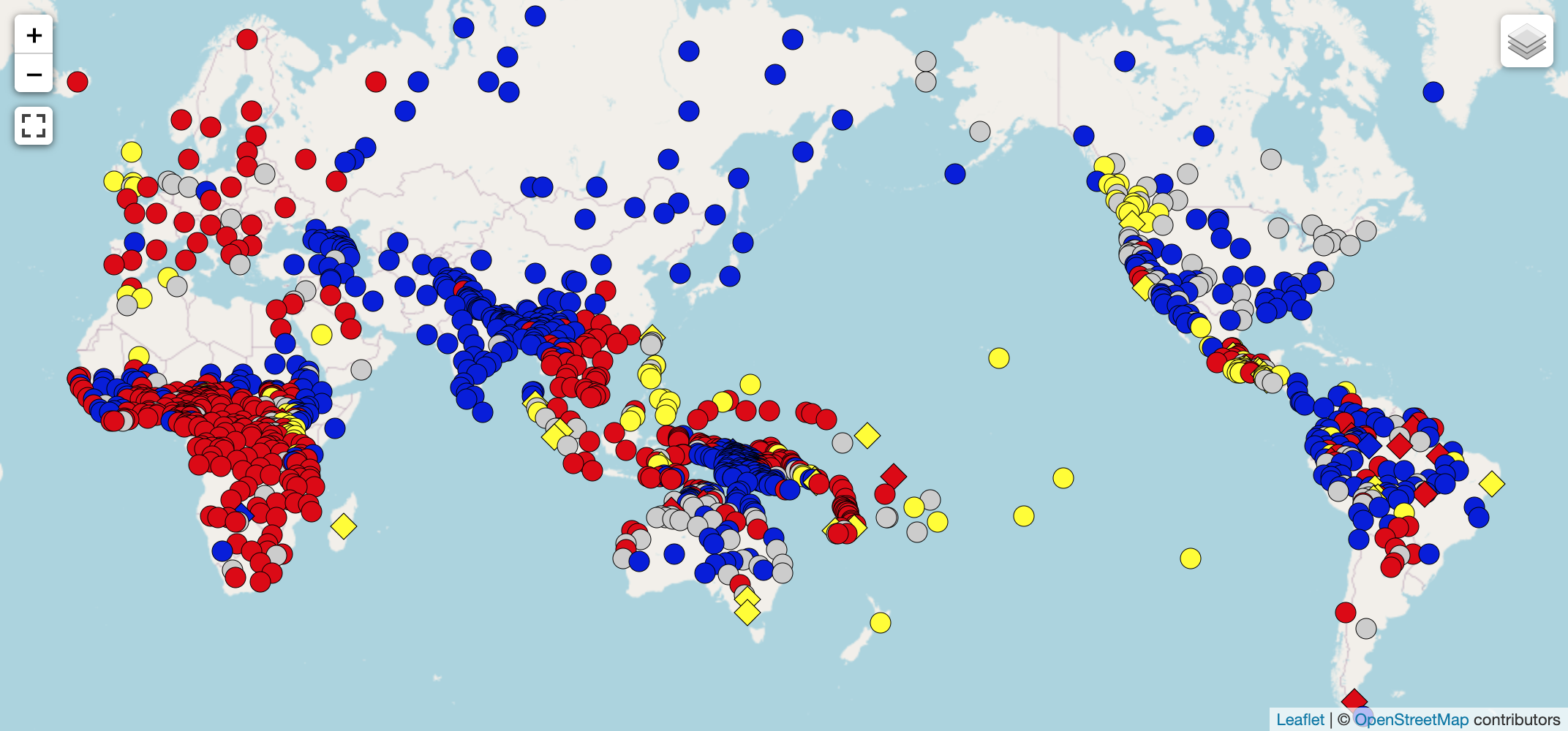
「自然言語処理の世界における、言語的多様性と受け入れの現状と展望 (The State and Fate of Linguistic Diversity and Inclusion in the NLP World)」と題された Joshi 氏らの ACL 2020 の論文 では、世界の各言語を、その言語に存在するラベルなしデータ(Wikipedia など)の量と、ラベル付きデータ(アノテーションされたコーパス)の量の2軸に基づいてプロットしており、そこからできるクラスターをもとに世界の言語を以下の 6 カテゴリに分類しています (Figure 2)。
- カテゴリ0「置いてけぼり」言語
- カテゴリ1「食いつなぎ」言語
- カテゴリ2「有望」言語
- カテゴリ3「成長株」言語
- カテゴリ4「負け組」言語
- カテゴリ5「勝ち組」言語。これには、英語、フランス語などのメジャーな言語の他に、日本語も含まれる。
カテゴリ0の言語を話す人は、世界の人口の 15% に上るということで、これらの言語の資源上の立ち位置が、言語システムへのアクセスの不平等さへと直結している現状が読み取れます。
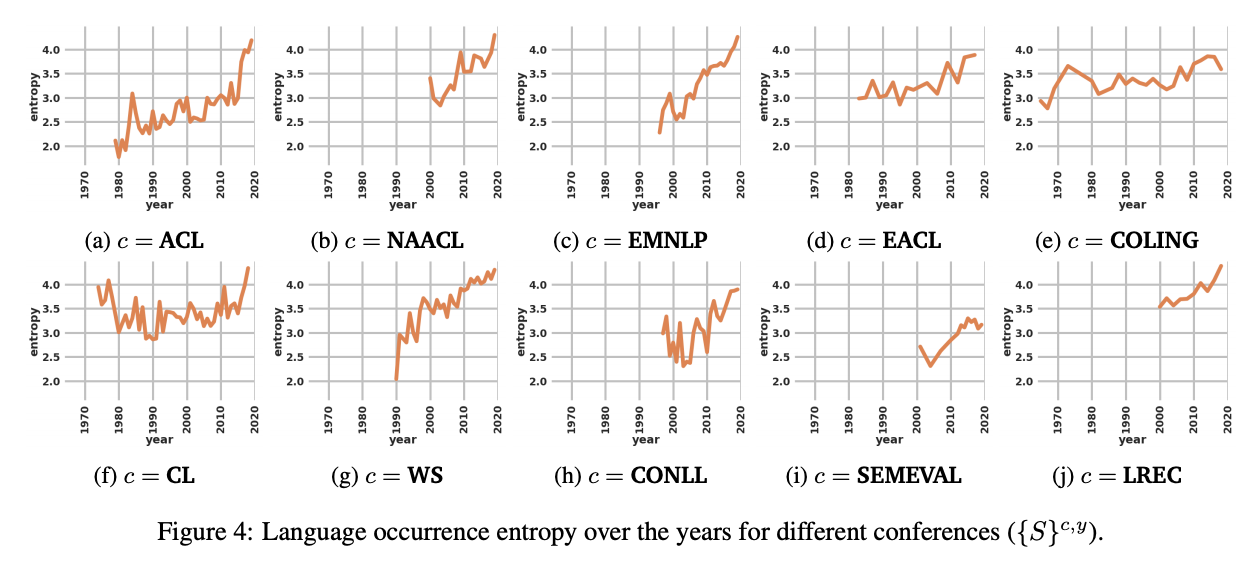
また、Sabrina J. Mielke 氏による ACL に採録された論文の分析では、ACL 2016 の 69% の論文が英語でしか評価していないことを指摘しています。また、Joshi 氏らの同論文では、自然言語処理分野の様々な学会 (ACL, NAACL, EMNLP など) に対して、論文中で扱われる言語の「多様性」をエントロピーを用いて測定し、その経年変化を分析しています (上の Figure 4 を参照)。後に始まった NAACL や LREC などの会議において言語の多様性が高いこと、トレンドとして見た場合、多言語手法の普及などの要因によって、言語の多様性は増大していること、などを明らかにしています。
英語の問題点
「対象にしている言語の名前を(たとえ英語であっても)明記すること」という 「BenderRule」で有名なワシントン大教授の Emily M. Bender 氏。The Gradient に掲載された同氏の記事では、
English is Neither Synonymous with Nor Representative of Natural Language
(英語は、「自然言語」と同義でもなければ、自然言語の中での代表的な存在でもない)
という警告とともに、なぜ英語が「言語の代表的な存在ではないか」という点を解説しています。
- 「手話」ではない。手話は、書き言葉、話し言葉と並んで重要な言語の一形態であるが、英語を対象とした研究において話題に上ることがほとんどない
- 表記体系が確立しておりおおよそ音に基づいている。中国語や日本語の漢字などの表意文字や、正書法を持たない言語も数多くある。
- 空白によって分かち書きされている。中国語、日本語、タイ語などは単語の分かち書きからスタートしなければならない。
- ほとんどのコンピューターで扱える ASCII コードしか使わない
- 形態論的な屈折がほとんど無い
- 語順が比較的固定されている
- データベースのフィールド名や、オントロジーの項目名は英語で書かれているのが普通であるので、それらと「たまたま」一致する可能性がある
- 大量の訓練データが存在する
なるべく言語特有の知識を入れないシステムが「言語非依存」である、という考えが広まっていますが、それに対して Bender 氏は、2009年の論文にて、「言語学的に経験不足であることは、言語学的に独立であることを意味しない」と反論しています。実際には、言語類型論の成果を利用すべきである、と述べています。
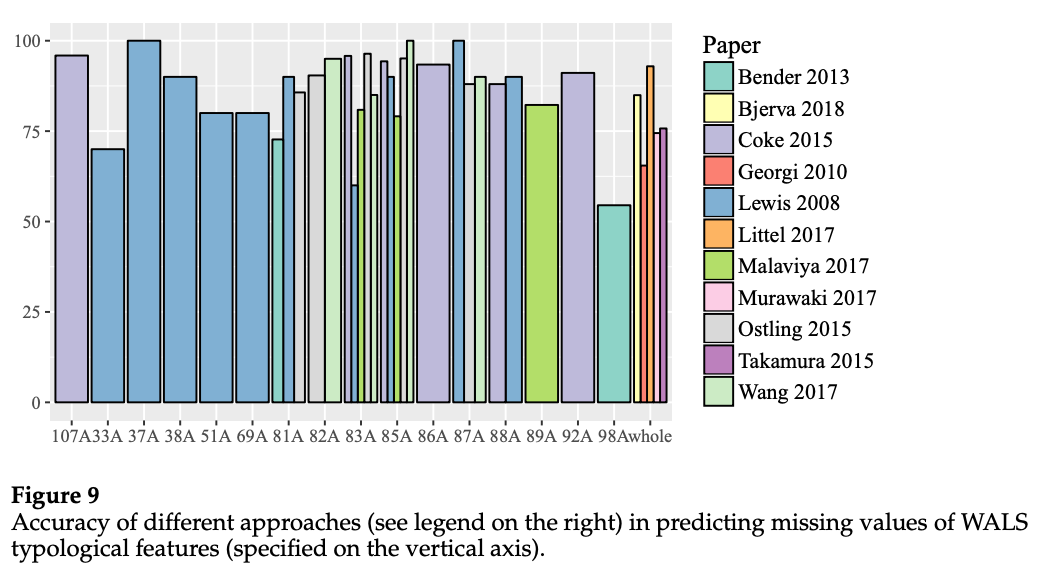
ちなみに、言語類型論 (typology) とは、世界の言語の構造的・意味的な特徴を分類し、各言語に共通する要素、言語によって異なる要素を分析する学問です。「世界言語構造地図」(World Atlas of Language Structure; WALS)では、世界の言語を、類型論に基づいた言語的特徴 (feature) によって分類しています。例えば、「主語・目的語・動詞の語順」という特徴には、言語によって、「SOV」「SVO」などの特徴値 (category) が対応づけられています。
自然言語処理の分野では、言語類型論に関する研究を扱うワークショップ・研究会 SIGTYP が 2019年と 2020年に開催され、研究分野としての広がりを見せています。言語類型論の情報に関する研究のサーベイについては、Ponti らの 2019年の論文 が詳しいです (上図は、言語の特徴推定精度を手法ごとに比較したものです)。
英語「だけ」で自然言語処理をすることの問題点
これまで、英語は世界の言語の中でも代表的な存在ではないという点を中心に紹介しました。一方、ACL などのメジャーな国際学会などで発表される研究・システムのほとんどが英語に関するものです。現状のように、英語「だけ」で自然言語処理の研究開発を進めていくと、何が問題なのでしょうか。
最もわかりやすい点としては、「英語以外の言語におけるシステムの性能が下がる」ことでしょう。上記 Joshi 氏らの論文では、1139個の類型論的な特徴値のうち、カテゴリ0, 1, 2 (低資源言語の3グループ)にしか存在しないものが549個もあることを指摘しています。そのうち、最も「見逃されている」特徴は「144E: SVO 言語における複数の否定形構造」 というものですが、これはウォロフ語、アイスランド語、キリヴィラ語 など、地理的に離れた少数の言語に存在しています。英語などメジャーな言語のみで訓練・テストされた自然言語処理のモデルが、このような言語においてうまく動かない可能性があるのは想像に難くないでしょう。
実際、文レベルの埋め込みを93言語に対して学習した Artetxe 氏と Schwenk 氏の論文 によると、このようにメジャーな言語によってカバーされていない「無視された」特徴を多く持つ言語に対して、類似文検索の誤り率が高かったという点を指摘しています。
本来、自然言語処理の応用は、医療や、翻訳、教育など、全ての人に利用可能になるべきものであると上記の Bender 氏は述べています。
上記の Ruder 氏の記事においても、英語以外の言語で言語処理をするべき理由を、以下の観点から説明しています:
- 社会的観点: 「デジタル言語格差」とも呼ばれる現象によって、技術アクセスの少ない言語や、非主流のアクセント、方言などの話者が不利になる。
- 言語学的観点: 上記 Bender 氏の記事にもある通り、英語(やその他の高資源言語)は世界の言語の代表的な存在ではない。英語以外の言語も扱うことにより、システムが多様な言語現象に対して頑健かどうかがテストできる。
- 機械学習的観点: 機械学習モデルの設計の際には、対象となる言語の特徴が前提として入り込む。Nグラム言語モデルやニューラルモデルは、形態論が複雑な言語に対してうまく行かない。BERT などの事前学習モデルは、比較的綺麗な大量のラベル無しコーパスを必要とするが、そのようなデータはほとんどの言語に対して存在しない。
- 文化的観点: テキストによって表現された情報は、その文化における「常識」や「普通」などの価値観を含んでしまう。
- 認知的観点: 人間の子供がいかなる自然言語でも学習できるように、自然言語モデルも、特定の言語に固有の構造だけではなく、異なる特徴を持つ言語に一般化できるべきである。
自然言語処理コミュニティとしてできること
これまで、自然言語処理のコミュニティでは、英語以外の言語について研究することは、「言語依存の」研究であり、重要ではないと見なされる傾向がありました。ある分野の「最先端 (state of the art)」といえば、デフォルトで「英語における最高性能」のことを指しています。
多くの研究者が現状に警鐘を鳴らし、風向きが変わったのは最近のことだと言えるでしょう。例えば、EMNLP 2020 の査読者向けのガイドライン では、「論文が、英語以外の言語についてのものである」という点は「論文を不採択にする正当な理由ではない」と明確に述べています。
Ruder 氏は、上記を踏まえた上で、私たちにできることとして、以下を提唱しています:
- データセット: データセットを作る際は、予算の半分を使って同じデータセットを他の言語で作る。
- 評価: あるタスクにおける性能を評価する際には、違う言語の同じタスクで評価してみる。
- BenderRule: 対象にしている言語の名前を(たとえ英語であっても)明記する(上で紹介済み)
- 仮説: モデルが使う仮説を明示し、どれが言語に依存でどれが一般化可能かを考える。
- 言語的多様性: 複数の言語を扱う場合、それらがどのぐらい多様かを見積もる。
- 研究: 低資源言語の問題を解決するような手法を研究する。
ちなみに、BenderRule について、Bender 氏本人も、「BenderRule は、必要最小限の最初のステップである。理想的には、訓練データの収集方などを明らかにするデータ表明 を使用すべき」と述べています。
日本語話者として私たちにできること
最後に、このような現状を踏まえた上で、日本語話者として我々にできることについて、少し私の意見も入れて考えてみたいと思います。
- 日本語話者としての視点を大切にする
本ブログの読者の皆さんは、日本語を母語として育ち、学校教育の中で英語を学んだという方が多いと思います。ご存知の通り、日本語と英語は言語学的に見て非常に「遠い」言語です。言語類型論的分類でも、語順、形態論、音韻論、など、多くの特徴において異なっています。
このような非常に異なる2つの言語をある程度知っているということは、ある意味非常に恵まれていると言えます。平均的な日本語話者の「言語感」というのは、例えば英語単言語話者のそれと比べてもずっと「言語非依存」であると私は思っています。例えば、日本語と英語では表記文字が違うことを知っていますし、日本語には分かち書きが必要であることも知っています。例えば「目的語」ような概念を表す時も、言語によってそれを語順によって表したり助詞のようなマーカーで表したりすることを体感的に知っています。このことが、自然言語処理モデルやシステムを設計する上で、非常に重要な視点となります。
一つ、具体的な例を挙げます。Google から最初に公開されたマルチリンガル版の BERT では、日本語に対して、濁点が取り除かれ、漢字も文字ごとに空白が挿入されるという処理が前処理として行われていました。一応モデルとしては動きますが、日本語話者の我々からすると、正直「使い物にならない」処理であると言えます。これは、「言語非依存」であることを追求した結果、個別の言語に対して不適切な処理を行ってしまった例だと言えましょう。
日本語と英語という異なる言語から来る視点を大切にし、システムやモデルの開発において、言語依存の部分とそうでない部分を見極め、論文やプロダクトとして発信していくというのは、我々にできる重要なことだと思います。
- 日本語と、さらに他の言語でも検証する
上記の Joshi 氏らの論文では、「言語と著者」の関係に関する統計を ACL Anthology のデータセットから抽出し、各言語がどのようなコミュニティによって研究されているかを分析しています。その結果、日本語をはじめ、標準中国語、トルコ語、ヒンディー語などの言語においては、他の低資源の言語と同じかそれ以上に、よりフォーカスされたコミュニティによって研究がなされているということが分かりました。これは、言語を専門に研究している繋がりの強いコミュニティがあることを示していますが、一方で、言語に閉じたコミュニティになってしまっている点も表しています。
上で述べたように、日本語話者としての独自の視点を広く活かすとともに、今の日本の研究コミュニティに必要なのは、その知見を他の言語にも活かすことのできる「オープンさ」なのでは、と思わされる結果です。
- 日本語のデータセットを作る
英語における自然言語処理の発展の一因として、多数のデータセットの開発・公開や、GLUE のような標準ベンチマークが普及していることが挙げられるでしょう。日本語においても、多数のデータセットが開発され、公開されていますが (例えば、京都大学の黒橋・褚・村脇研究室 では、日本語のコーパスや翻訳、自然言語理解用のデータセットを多数公開しています)、これらの公開・利用は主に日本国内に閉じてしまっている傾向があります。
日本語話者として多様な言語の自然言語処理技術に貢献するには、日本語のデータセットを作り、それを英語で論文等として発表し、様々な言語モデルに対するベンチマークとして使ってもらうという取り組みが重要であるように思います。
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人