

ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
7/6〜7/10 にかけて、自然言語処理分野のトップ会議である ACL 2020 が開催されました。今回はコロナウイルスの影響により初のオンライン開催となり、開催側、参加側とも試行錯誤の部分が大きかったと思います。口頭発表のビデオは基本的に全て事前に録画され、Q&A のディスカッション等はテキストベースのチャット、もしくは Zoom などのオンライン会議システム上で行われました。
個人的には、研究者仲間とコーヒーを飲んだり食事をしたりしながら交流を深められる従来の会議スタイルが懐かしく思う反面、こうしてオンライン開催にすることで、世界各国の様々な人々が公平に参加できるようになるというのは、とても良いことだと思っています。
合計で 779本の論文が採択され、かつ、チュートリアルや併設ワークショップ等も多数開催されたため、スキマ時間にビデオを効率良く見ても、とても全てチェックできるような量ではありません。本記事では、ACL 2020 に参加して研究をチェックして分かった「自然言語の最新トレンド」を、以下の3つの点に絞って解説したいと思います。
- トレンド1. 事前学習言語モデル (PLM) の台頭と、少ないデータでの訓練
- トレンド2. 指標至上主義からの脱却
- トレンド3. 知識ベースとグラフ
ACL のまとめの記事としては、アレンAI の Vered Shwartz 氏が Highlights of ACL 2020 と題した記事を書いていますし、Michael Galkin 氏が、ACL 2020 の知識グラフ系の研究をまとめてくれている ので、そちらも参考になるかと思います。本記事の執筆の際にも参考にさせていただきました。
会議全体のトレンド
ACL 全体では、3,429件の投稿があり、そのうち779件が採択されました。投稿数だけを見ても、これは2年前と比べて倍増している計算になります。いかにこの分野の成長が速いかがわかる数字です。
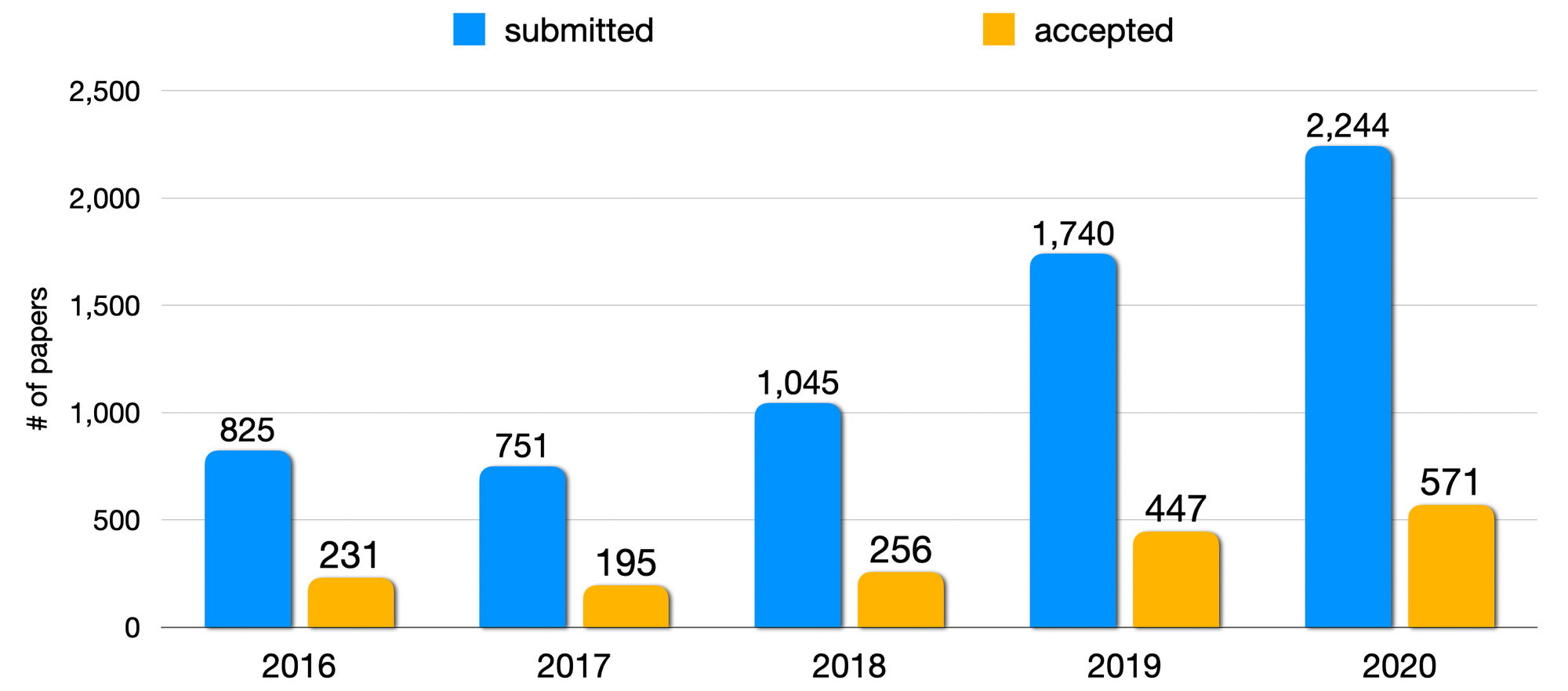
国・地域別での投稿数を見てみると、米国・中国が並んで突出しています。数年前からAI分野では「米中二強」なのですが、今年も(そしてしばらくは)その傾向が続きそうです。日本も投稿数で6位、採択数で5位と健闘しています。ACL の他の統計については、このページから見られます。
ACL に採択された論文のトピックの傾向については、Joohong Lee 氏がこちらにまとめてくれています。

全体で見ると、"generation" 「生成」、"dialog" 「対話」、"graph" 「グラフ」 "knowledge" 「知識」などが目立ちます ("translation" 「翻訳」や "machine" 「機械」はいつも多いので今回は特別取り上げません)。
上記の Shwartz 氏のブログにも言及がありますが、トピックの推移を時系列で見ると、分野全体では、「タギング」「構文解析」などの下位レベルの(文の基本的な構造を予測する)タスクから、「対話」や「生成」などの上位レベルの(テキストそのものを予測したり、自然言語を使って何かを達成する)タスクへのシフトが見られます。
このトレンドの流れには2つの理由があります。一つは、BERT などの強力な事前学習言語モデルの登場によって最終タスクを直接、高性能で解くことが可能になり、下位レベルの言語的な構造を予測する必要があまり無くなってしまったことです。「BERT の登場で、伝統的な NLP は死んだ」とまで言われます。もう一つの理由は、Transformer などのニューラル・ネットワークに基づいた強力なモデルの登場により、自然な文の統計的規則性を大規模コーパスから学習する道具が揃ってきた、ということです。以上の理由から、ここ数年で機械翻訳の質は劇的に向上し、テキスト生成や対話などの研究や実用応用が進んでいるのです。
以下では、上記の3つのトレンドに注目して、関連する研究を紹介します。
トレンド1. 事前学習言語モデル (PLM) の台頭と、少ないデータでの訓練
BERT や RoBERTa に代表される事前学習言語モデル (Pretrained Language Model; PLM) の台頭は今に始まったことではありません。2018年にこれらのモデルが開発されて以来、その強力な汎化予測能力が認められ、ありとあらゆるタスクに PLM が適用されてきています。上記の Shwartz 氏も、こう述べています。
There is a reoccurring pattern in NLP research of (1) introducing a new architecture / model; (2) publishing low hanging fruit by improving the architecture / model or applying it to various tasks; (3) publishing analysis papers that show its weaknesses; (4) publishing new datasets. I’d say we are currently between 2 and 3, though some things are happening in parallel.
「NLP の研究では、このような決まったパターンが繰り返される。(1) 新しいアーキテクチャやモデルが開発される (2) そのアーキテクチャやモデルを改善したり、色々なタスクに適用するといった簡単に手の届く研究が発表される (3) その弱点を分析する論文が発表される (4) 新しいデータセットが発表される。今、分野は 2 と 3 の間にあるが、他の様々なことも同時に起こっている」
私は自然言語処理の分野に身を置いて10年以上になりますが、このように新たな強力なモデルが開発されると、それが様々なタスクに適用される、というサイクルを少なくとも3回は見てきました。1回目は、SVM や CRF など、統計的機械学習に基づいた分類・解析手法が発明された時。2回目は、word2vec などの手法に代表されるニューラル・ネットワークが高い性能を上げ始めた時。そして3回目は、今回の事前学習言語モデルの台頭です。
今回の ACL で目を引いたのは、「多段階事前学習」と呼ばれる手法です。BERT や RoBERTa などの事前学習言語モデル (PLM) は、
- 事前学習:大規模なラベル無しテキストデータを用い、自己教師あり学習 (self-supervised learning) に基づきモデルを事前学習
- fine-tuning:対象となるタスクのラベル有り訓練データを用い、モデルを fine-tuning (パラメータを微調整)
という2つの段階を経るのが一般的です。ところが最近、この 1 と 2 の間に、「事前学習」のステップをもう一度挟むことが普及してきますた。この中間的な事前学習に使われるタスクは「中間タスク」と呼ばれます。
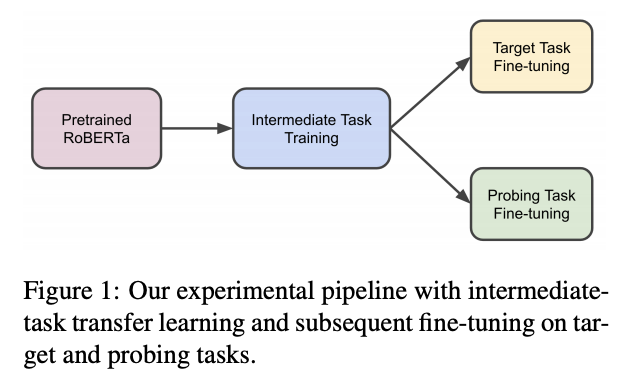
Pruksachatkun 氏らの論文 では、PLM を対象タスクで fine-tune する前に、どのような中間タスクを使うのが良いのか、どのような言語的な能力が対象タスクに転移するのか、を詳細に分析しています。
また、ベスト・ペーパー Honorable Mention (佳作賞) に選ばれた Gururangan 氏らの論文 では、対象タスクのデータを使って fine-tune する前に、対象タスクと同じ分野、もしくは、対象タスクの訓練データを使って、さらに事前学習を進める手法を提案し、タスクの性能を向上させることに成功しています。本論文をはじめ、ACL 2020 のベスト・ペーパーはこの記事で個別に解説しましたので、詳細はそちらをご覧ください。
Sellam 氏らの論文 では、翻訳や要約などの自動評価指標である BLEURT を提案しています。名前の通り BERT に基づいた BLEU 的な存在なのですが、最終的なタスクで fine-tune する前に、既存の性能評価指標を使った疑似データを使って事前学習するというように、中間的なタスクを使っています。
これからも、様々なタスクで中間タスクが普及していくと思います。なお、研究ベースで使う事前学習言語モデルとしては、BERT よりもその改良版 RoBERTa がデフォルトになってきた感があります。
他にも、事前学習言語モデルの普及により、対象タスクの訓練データを全く使わない "zero-shot" や、少ししか使わない "few-shot" の手法が、数年前からさかんに研究されています。
Tamborrino 氏らの論文 では、PLM を使って文の「もっともらしさ」をランキングすることにより、 zero-shot で常識推論の新ベースラインを達成しています。
Aharoni 氏と Goldbert 氏の論文 は、PLM によって得られる埋め込みは既に分野知識を含んでいるので、教師なしで分野のテキスト分類ができることを示しています。
Conneau 氏らの論文 は、XLM-R と呼ばれる事前学習言語モデルを提案しています。一言でいうと、RoBERTa の超マルチリンガル版の XLM-R を用いて、様々なクロスリンガルタスクで SOTA (state-of-the-art; 最高性能) を達成しました。
トレンド2. 指標至上主義からの脱却
近年の自然言語処理分野(そして他の人工知能の分野)では、あるタスクに対して、そのタスクの入力に対して正解を与えたデータセットを作り、機械学習を用いて入力から出力へのマッピングを学習し、テストセットに対して何らかの指標を使いその性能を測定する、ということが行われます。自然言語処理の問題は、ほとんどが単なる分類もしくはその組み合わせで解くことができるので、「分類の精度」といった指標が広く使われています。
今回の ACL では、この前提に疑問を呈するような研究が数多くありました。
米コロンビア大学 の Kathleen R. McKeown 教授による「Rewriting the Past: Assessing the Field through the Lens of Language Generation」(過去を書き換える:言語生成のレンズを通して分野を評価する)と題された基調講演では、「ニューラルネットの最大の成果は何か(現在)」「昔の論文を参照するか(過去)」「ディープラーニングが向いていないタスクは(未来)」といった質問に関して、要約・対話・翻訳の分野の著名な研究者にインタビューしながら、テキスト生成系のトレンドを基に掘り下げていくという形式での発表がありました。ここでは、これまでの「データセットにおける精度」が全てという分野の「当たり前」に疑問を投げかけ、「データセットではなく、タスクを解く」というメッセージを述べていました。
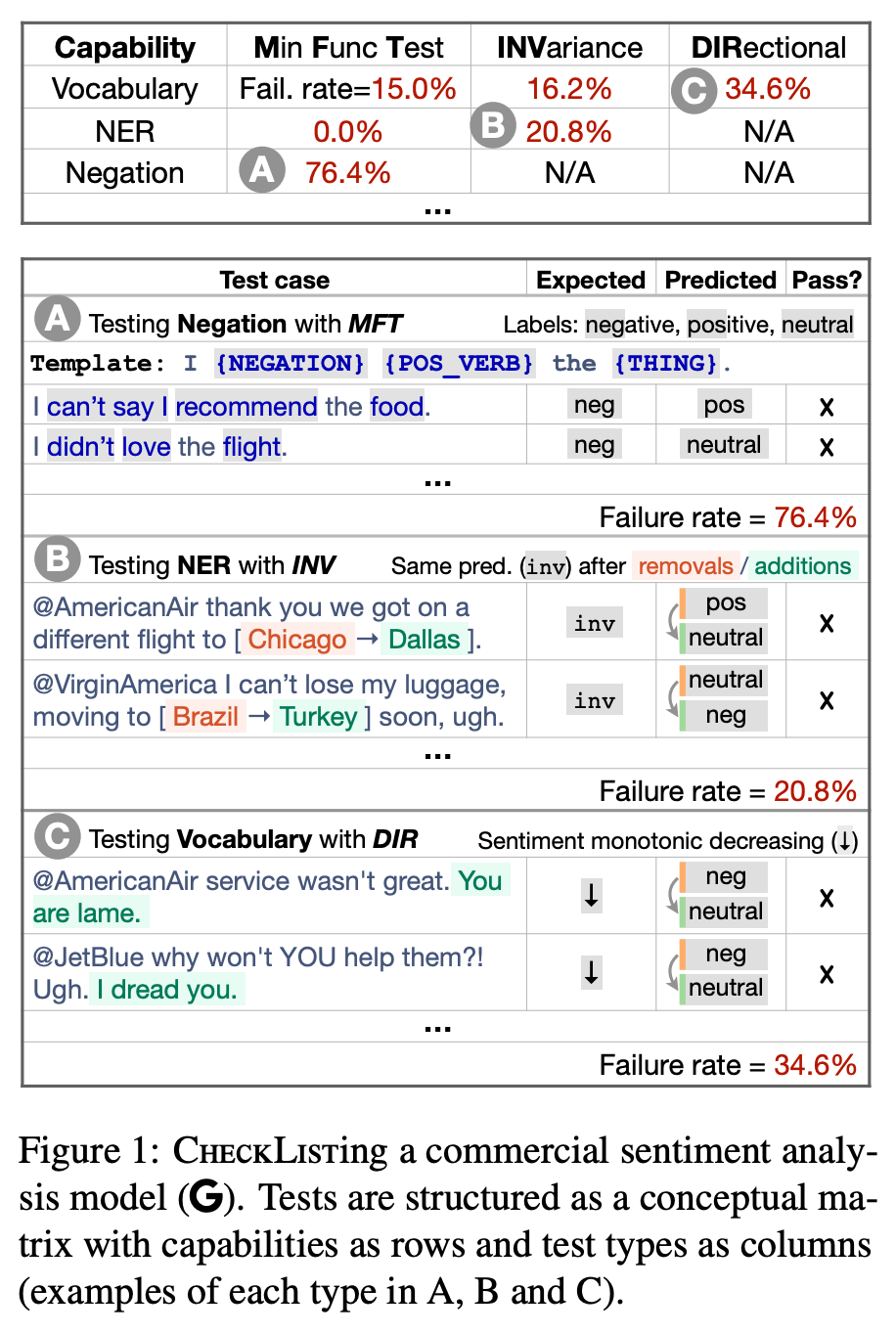
ベストペーパーに選ばれたRibiero 氏 らの Beyond Accuracy: Behavioral Testing of NLP Models with CheckList という論文 では、これまでの「テストセット上での精度至上主義」とでも呼べる傾向に対して、「CheckList (チェックリスト)」と呼ばれる、NLP モデルの言語学的能力をテストする方法論、アプローチを提案しています。
また、ベスト・ペーパーの Honorable Mention (佳作) に選ばれた Mathur 氏らの論文 では、一言で言うと、BLEU など機械翻訳のための自動評価尺度の評価にまつわる様々な問題を指摘し、これらの自動評価尺度、特に BLEU/TER を、機械翻訳システムに関する重要な決定に使用しないように呼びかけています。
これら ACL 2020 のベスト・ペーパーはこの記事で個別に解説しましたので、詳細はそちらをご覧ください。
自然言語処理では分類問題がよく使われるというのは上で述べた通りなのですが、その多くが、感情分析のように「ネガティブ・中性・ポジティブ」や、レビューの星の数のように、順序関係のある順序変数です。このような順序変数に対する回帰・分類に使われる手法に順序回帰(ordinal regression)があります。このような場合に、単に精度や F値 により測定すると、クラス間の関係やラベルの分布などを全く考慮できません。この問題に対して Amigo 氏らの論文 では、クラスの近さを考慮した Closeness Evaluation Measure (CEM) と呼ばれる評価指標を提案し、性能をより正確に測れるようにしています。
Chen 氏らの論文 では、「不確定自然言語推論 (Uncertain Natural Language Inference; UNLI)」というタスクの枠組みを提案しています。自然言語推論 (Natural Language Inference; NLI) やテキスト含意認識 (Recognizing Textual Entailment; RTE) といったタスクは、前提の文と帰結の文が与えられ、後者が前者の論理的な帰結になっているかどうかを判定するという分類問題として解かれることが多いのですが、これは実際には確率的な不確定性を持った判断であり、そのためのデータセットの作成およびモデルを開発しています。
事前学習言語モデルを単にタスクに適用し性能を向上させるだけでなく、BERT などのモデルによる予測がなぜうまくいくか、どのような言語学的な能力を持っているか、ニューラル・ネットワークが何を捉えているか、などの分析に関する研究が数多く出てきています。これらの研究は BERTology (バート学)と呼ばれ、代表的な論文に ACL 2019 で発表された Tenney 氏らの BERT Rediscovers the Classical NLP Pipeline という論文がありますが、今年の ACL でも事前学習言語モデルの言語学的な性質等を測定する研究がありました。
Hu 氏らの論文 では、GPT-2, Transformer-XL などの言語モデルの構文知識を、Sorodoc 氏らの論文 では、名詞と先行詞の照応関係を、Kulmizev 氏らの論文 では、Universal Dependency のような「深い」言語構造を、栗林氏らの論文 では、日本語の語順に対する知識を分析しています。
トレンド3. 知識ベースとグラフ
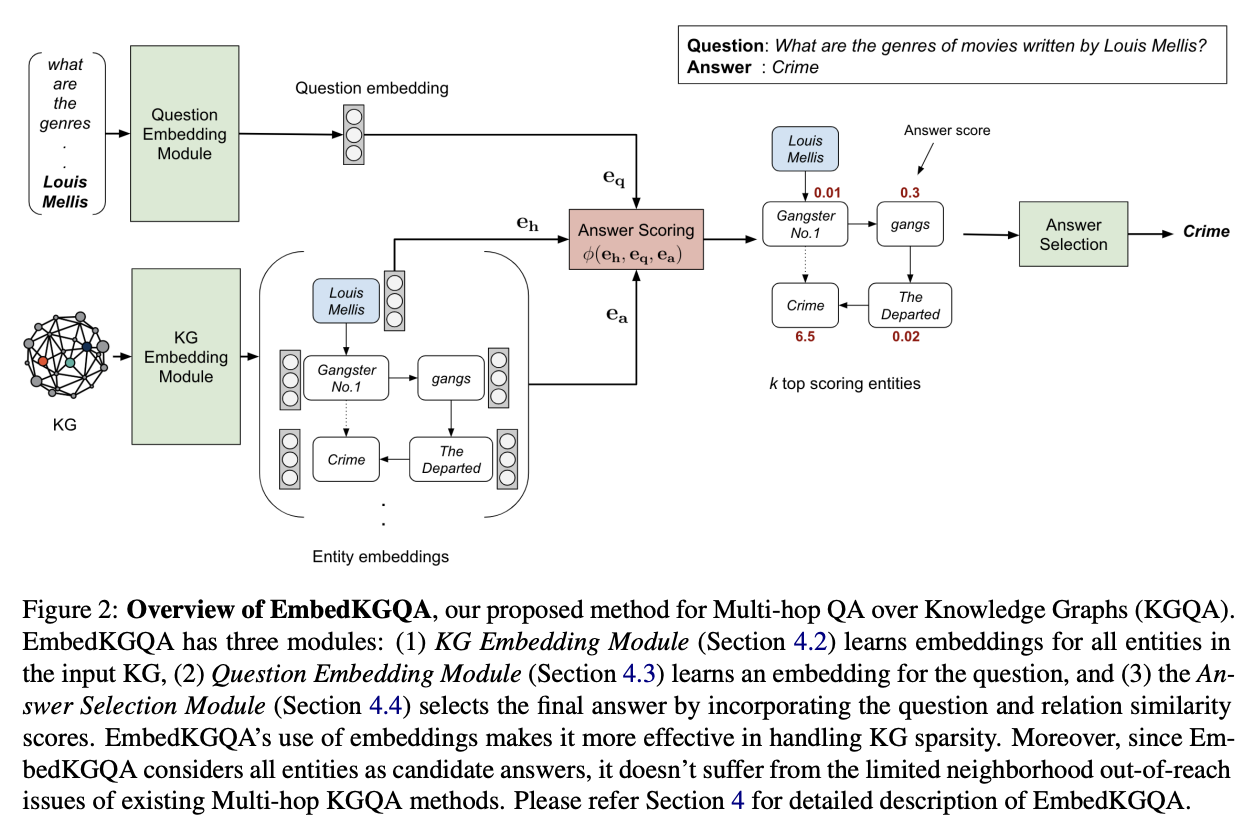
知識ベース (Knowledge Base; KB) とは、人間の持つ知識を何らかの構造を用いて構造化したデータベースのことを指します。自然言語処理の分野では、現実世界のエンティティ(実体)と、その間の関係をグラフ構造によって表した知識グラフ (Knowledge Graph; KG) に関する研究が活発に行われ、推論、質問応答、対話など、様々なタスクに応用されています。数年前から研究開発が活発な分野ですが、今回も多数の研究が発表されました。
グラフの双曲空間への埋め込みは、近年機械学習界隈でホットなトピックですが、この Chami 氏らの論文では、知識グラフの階層関係と論理関係の両方を埋め込むことのできる双極空間への埋め込みを提案しています。また、知識グラフの埋め込み に関連して、Sachan 氏の論文 では、推論性能を落とすことなく、知識ベース埋め込みを短い整数の列に圧縮する手法を提案しています。
Lan 氏らの論文 では、強化学習の手法を用いてクエリグラフを繰り返し的に生成する手法を提案しています。また、Saxena 氏らの論文 では、知識ベースの埋め込みを使い、知識ベースに対して多段階の推論が必要な質問応答をするというタスクを解いています。
通常の知識グラフでは、エンティティ間の2項の関係しか扱えないのですが、Guan 氏らの論文 は、n項関係を持つ知識を、「属性:値」の構造として扱い、知識ベース上での推論ができるモデル NeuInfer を提案しています。また、文書の(抽象型)要約の際に、知識グラフを同時に構築し、エンコーダーを2つ使いエンティティ間の関係を理解しながら要約する手法も、Huang 氏らの論文 にて提案されています。
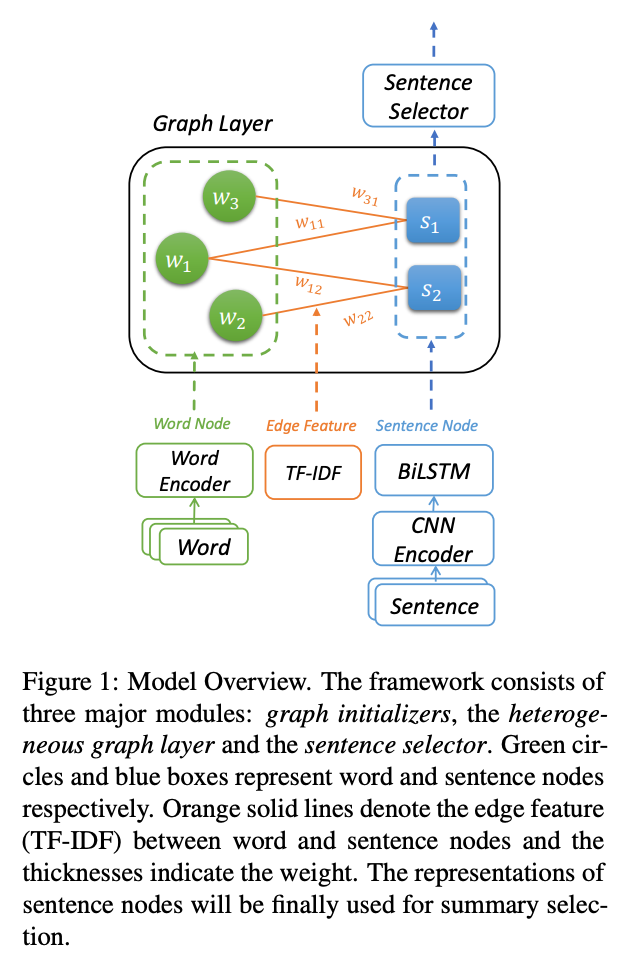
また、知識ベースに限らず、グラフ構造は、自然言語処理の研究やアプリケーションに広く利用されてきました。単語や文、構文やエンティティといった言語学的な単位は、グラフでの表現と非常に相性が良いからです。
Wang 氏らの論文 では、文書の(抽出型)要約の際に、単語や文からなるグラフを構築、分間の関係をモデル化しています。
Wang 氏らの TACL の論文 では、グラフからテキストを生成する「グラフ・トランスフォーマー」というモデルを提案し、AMR (抽象意味表現)をテキストに変換します。類似手法として、Yao 氏らの論文で提案されている、異種のノードをエンコードできる Heterogeneous Graph Transformer (HetGT) もあります。
Luo 氏と Zhao 氏の論文 では、ネストされた固有表現を認識するために、LSTM ベースののエンコーダーと GCN (グラフ埋め込みネットワーク) を使いエンティティ間の関係を学習しています。
自然言語処理の今後のトレンドは?
以上を踏まえると、短期的な自然言語処理のトレンドとしては、以下のようなものになると予想しています。
- 事前学習言語モデルの利用は、これからもっと普遍的なものになる。BERT → RoBERTa 、GPT-2 → GPT-3 に置き換わったように、モデルの能力を高めてより巨大なデータセットで学習したモデルがこれからも出現し続けるでしょう。
- ACL 2020 で提案された中間タスクによる事前学習は、方法として非常に単純で効果もあるので、これからもさらにその利用が広まるでしょう。
- 「BERT をこのタスクへ適用してみました」系の研究は既に一巡した感があります。これからは、各タスクについて、「そもそもどのように評価するべきか」「なぜ BERT が有効なのか」といった問いや、言語学的な分析がさらに進むでしょう。
この記事ではなるべく浅く広くトレンドを紹介したつもりですが、他に面白い研究や重要なトレンドなどを見落としている可能性もあります。ご意見やご感想などは著者までいただければと思います。また、今回は取り上げられませんでしたが、併設ワークショップやチュートリアルも多数開催されました。また機会があれば本ブログにて紹介したいと思います。