

ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
HuggingFace といえば、BERT などのトランスフォーマー基づいた事前学習モデルを簡単に使える Transformers というライブラリを開発していることで有名なスタートアップ。ライブラリには(私も含めて)お世話になっている方も多いのではないでしょうか。
HuggingFace の研究チームを率いる Thomas Wolf 氏 による「自然言語処理の未来」と題されたトーク、ごく最近の自然言語処理のトレンドがうまくまとまっていて非常に良い内容でしたので、本記事では、Wolf 氏本人の許可を得た上で、本トークの内容を日本語で詳細に紹介します。なお、スライドは、こちらのリンクから見ることができます。また、本トークの内容は、ニューラルネットワーク、トランスフォーマー、BERT など、近年の深層自然言語処理の知識を前提としています。
- 指数関数的に増えるモデルサイズ
- 事前学習モデルのサイズ削減
- 指数関数的に増えるデータ量
- ドメイン内 vs ドメイン外汎化
- 自然言語推論 (NLI) の限界と、自然言語生成 (NLG) の勃興
- 頑健性の欠如
- モデルは、本当に言語を理解しているか?
- 自然言語処理は「常識」を扱えるか?
- 事前学習モデルの進化は、2018年で止まってしまうか?
指数関数的に増えるモデルサイズ
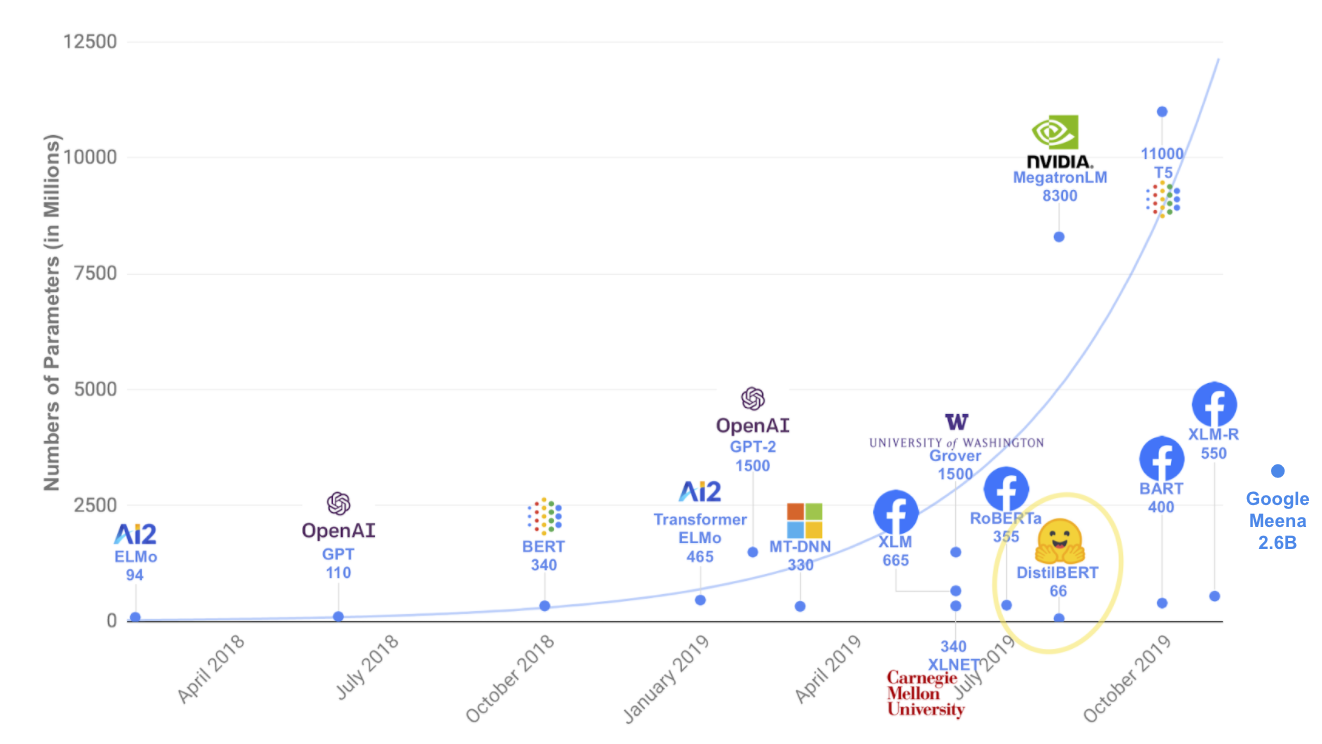
近年提案されているモデルの大きさが指数関数的に増大しているのは、皆さんもご存知ですね。例えば、Google から提案されたモデル T5 は、11B (110億) 個ものパラメータがあります。
大きなモデルになると、単一の GPU に収まらず、単にモデルをロードしてバッチサイズ=1の推論を走らせるために 4〜8個の GPU が必要なこともあります。
なぜこれが問題なのでしょう。大量の計算量が必要なので、GPU などの資源が潤沢にある超大企業しかそもそも参戦できません。GLUE のリーダーボードを見てみると、上位は Google, Facebook, Microsoft, Baidu などの「常連」で独占されています。そこに、アカデミアの影はなく、多様性が欠如していることがわかります。また、エネルギー消費、環境的な問題もあります。
もっと根本的な問題として、このままモデルとデータを大きくしていけば「強い AI」が達成できるのか?という問題も指摘されています。
この問題に対して、近年では、その逆の方向、「小さいモデル」に対する研究も進んでいます。つまるとろこ、ニューラルネットワークはパラメータが多すぎるのです。重みを刈り込むアイデアは、1989年に LeCun 氏によって提案されています。
2019年に宝くじ仮説 (lottery ticket hypothesis) が発表されて以来、このトピックに関連する研究も進んでいます。宝くじ仮説とは、「ランダムに初期化した密なネットワークに、対象のタスクで元のネットワークと同じ性能を上げる部分ネットワークが含まれている」というもので、これを「当たりくじ」に例えています。NLP と強化学習でも、対象タスクの性能を大きく損なうことなく、90% ものパラメータを削減できることを示した研究があります。
Wolf 氏らは、モデルサイズと計算効率の問題を議論する場として、「SustaiNLP 持続可能なNLP」と題されたワークショップを企画しています。SuperGLUE などの標準データセットを使い、最新モデルと同じ性能を達成しながらエネルギー効率性をいかに高められるかを競うシェアードタスクを企画しているということです。
事前学習モデルのサイズ削減
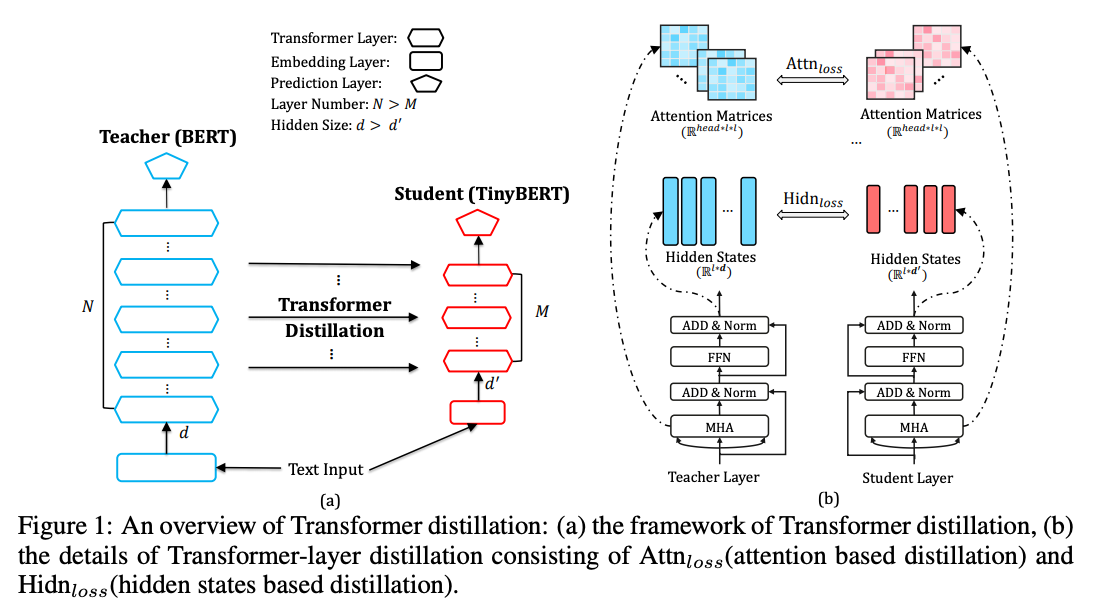
事前学習モデルのサイズを削減するためには、主に、
- 蒸留 (distillation)
- 刈り込み (pruning)
- 量子化 (quantization)
の3つの方法があります。
Sanh 氏 らは、BERT を蒸留したモデルである DistilBERT を開発しました。知識蒸留 (knowledge distillation) の手法を使い、教師 (BERT) の出力を真似るように小さなモデルである生徒 (DistilBERT) を訓練することにより、BERT の 95%の性能を保ちながら、40% 小さく 60% 速いモデルを達成しています。
2019年には、他にも多くの蒸留モデルが発表されました。TinyBERT では、中間状態の変換、データ拡張など、様々な手法の組み合わせを使っていますが、実際にどの手法が一番利いているかがわかりにくくなっています。
ヘッドの刈り込みでは、トランスフォーマーの注意機構のヘッドを直接削除します。機械翻訳や、自然言語理解のタスクで、ヘッドの多くを削除しても性能を同じレベルに保てることが示されています。また、ヘッドの「重要スコア」を計算し、優先的に刈り込む手法もあります。
ヘッドの代わりに、重みを刈り込む手法もあります。個別の重みを、正則化によって刈り込む手法ですが、重みがスパースな行列になるので GPU と相性が悪いという問題があります。
また、レイヤーごと刈り込んでしまう手法も提案されています。事前学習中にドロップアウトに似たアイデアに基づきレイヤーをランダムに削除し、頑健なモデルを学習するというアイデアです。
スパースなモデルをゼロから学習することもできますが、「密な行列演算」に特化されている GPU/TPU と相性が悪いという問題があります。この問題に対処するために、ブロック単位で重みを削除する手法も提案されています。発想を変えて、疎な演算に特化されているチップ (Graphcore の IPU など) を使うという手もあります。
重みを 32ビット浮動小数点から 8 ビットの整数に量子化する Q8BERT が Intel によって開発されています。また、動的に量子化を適用する実験については、こちらの PyTorch のチュートリアルから読むことができます。
指数関数的に増えるデータ量
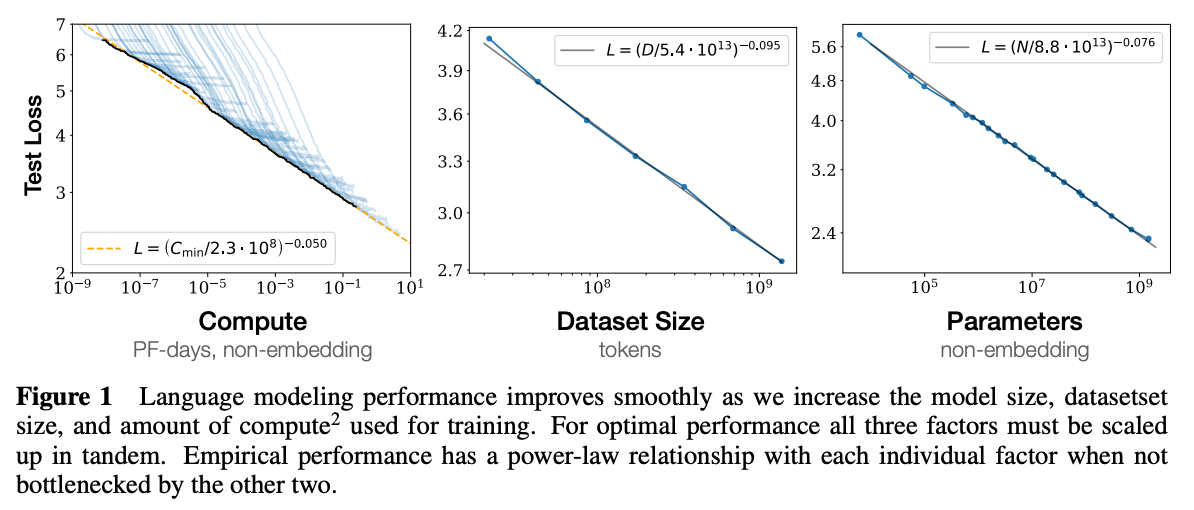
事前学習、fine-tuning のそれぞれに使われるデータ量も、指数関数的に増大しています。これは、モデル間の性能比較をする際に問題となることがあります。あるモデルの性能が高かったとき、それが訓練データが大きいからなのか、モデルのアーキテクチャが良いからなのか分からないからです。
去年起こった XLNet vs BERT の議論がその代表的な例でしょう。XLNet は、自己回帰的にトークンをランダムに予測する優れた手法を提案しましたが、BERT よりも大きなデータで訓練されていました。XLNet がベターなのは単に教師データが大きいからでしょうか?
この議論は、RoBERTa の登場で(ある意味)決着がついてしまいました。RoBERTa は、BERT とほぼ同じシンプルなアーキテクチャで、単により大きい訓練データで訓練されただけで、XLNet を上回る結果を出したからです。これは、Richard Sutton 氏が指摘する「モデルを工夫するより、データとスケールが重要である」という機械学習における「苦い教訓」 となりました。
データ、モデルサイズ、計算量を増やした時に、言語モデル(トランスフォーマーの自己回帰的モデル)の性能がどう変化するかが、OpenAI による論文に詳細にかかれています。データサイズとモデルのパラメータ数に対して、綺麗なべき乗則に従って性能が向上しています(上のグラフ参照)。一方で、トランスフォーマーの他のパラメータ、例えば、順伝播レイヤーのサイズの比、レイヤー数の比、注意ヘッドの次元など、「そこそこ」の範囲に入っていればあまり重要ではないということも分かりました。また、最近の興味深い論文に、データセットに比べて「大きすぎる」ぐらいのモデルを用意し、収束する前に訓練を止め、圧縮する方が良いというを提案しているものもあります。
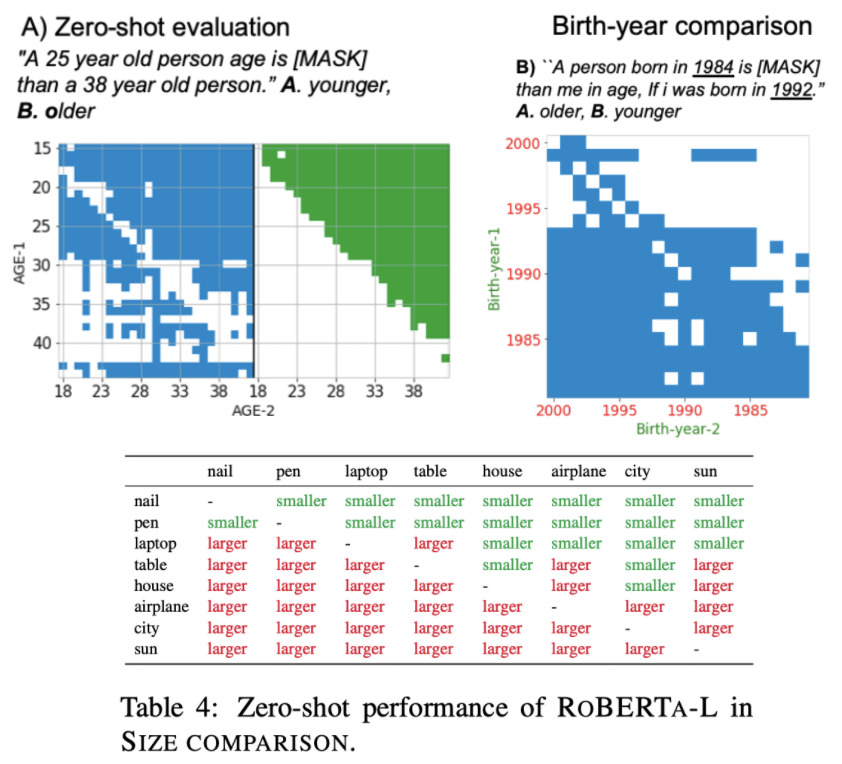
このまま、データやモデルサイズを増やしていくと、何が起こるのでしょうか?データを増やすだけで、自然言語理解に対する「質的な飛躍」が見られるのでしょうか?
この問題に対する回答として、AI2 から出された論文では、BERT (137B トークンで訓練) と RoBERTa (2.2T トークンで訓練) を比較し、質的な飛躍が起こっていることを部分的に確認しています。具体的には、「25歳の人は、38歳の人より ○○」という文を(fine-tune していない)BERT/RoBERTa に入力し、○○が 「若い (younger)」「年上 (older)」かを当てる、というタスクです。これを解くためには、数字の比較と常識が必要になりますが、BERT(上図の青)に比べ、RoBERTa(上図の緑)の比較がかなり良いことが分かります。
また、「1984年に生まれた人は、1992年に生まれた人より○○」という、生まれ年に基づいた逆の質問や、モノの大きさ(爪、ペン、ラップトップ、...、都市、太陽)を比べるタスクでも、RoBERTa は、fine-tuning なしで既にかなり良いということです。
モデルの汎化能力について論じたものに、Yogatama 氏らの論文があります。これは、Wolf 氏も「2019年で最も重要な論文の一つ」と評するもので、重要な問題提起をしています。
この論文では、最近のデータセットは、汎化なしで解くのが簡単すぎることを指摘しています。また、現在のデータセット、評価のパラダイムでは、モデルの「サンプル効率性」を正しく評価できないとしています。例えば、以下の2つのモデルがあったとします:
- モデルA 100サンプルで90% の精度に到達、その後上昇しない
- モデルB 100万サンプルで 90% の精度に到達、その後 92% に上昇
転移学習の究極的な目標は、モデルA のような汎化能力の高いモデルを作ることですが、現在の訓練・評価のパラダイムでは、B の方が高く評価されてしまいます。また、fine-tune したモデルは、通常、訓練されたタスクでしか動かないという問題があります。
モデルの汎化能力を測るための指標として、オンラインコード長が提案されています。これは、モデルを使って情報をいかに効率的に圧縮できるかに基づいた情報理論的指標です。Yogatama 氏らの論文では、ELMo や BERT などのモデルを使い、観測したサンプル数に対するタスクの性能やオンラインコード長を比較・分析しています。BERT や ELMo のようなモデルの汎化能力が低い理由のひとつに、タスク依存のコンポーネント(分類ヘッド)が必要という点が挙げられます。
ドメイン内 vs ドメイン外汎化
モデルを訓練する最終的な目的は、ドメイン外のデータに対しても予測がうまくいくようにする「ドメイン外汎化」ですが、実際はドメイン内にしか汎化しないことが徐々に分かってきました。
上で述べた Yogatama 氏らの論文では、質問応答 (QA) の代表的なデータセットである SQuAD で訓練されたモデルは、Wikipedia 外の他のドメインに適用すると性能が極端に落ちることが示されています。
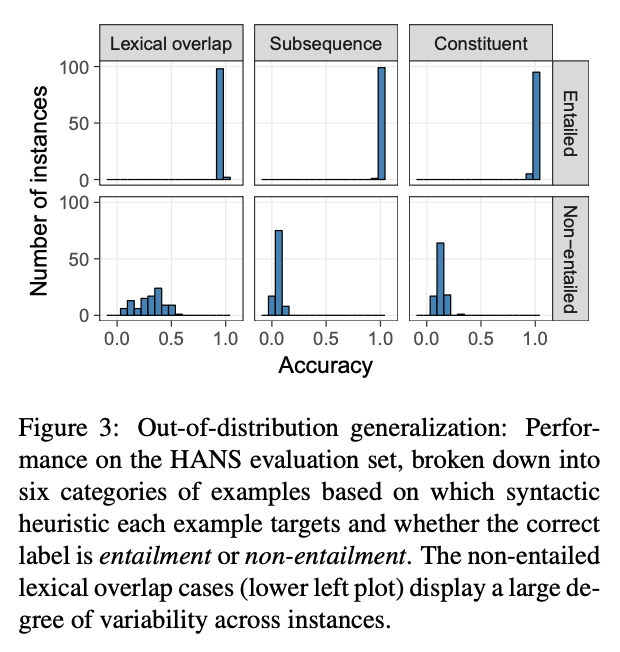
McCoy 氏らの論文では、BERT を、自然言語推論 (NLI) の代表的なデータセットである MNLI で fine-tune したモデルを 100個用意しました。一方で、同じタスク (NLI) において、受動態、語彙的なオーバーラップなどのルールを使用し、解くのが難しい敵対的データセット HANS を作成しました。MNLI で fine-tune した BERT のモデルは、全てそこそこ良い (80% ほど) 性能を示しますが、敵対的データセットに適用すると、その汎化能力には大きな幅があることが分かったのです。現実世界のデータセットでモデルがどのぐらいうまく動くか知りたければ、テストセットにおける性能はまったくアテにならないと言えるでしょう。
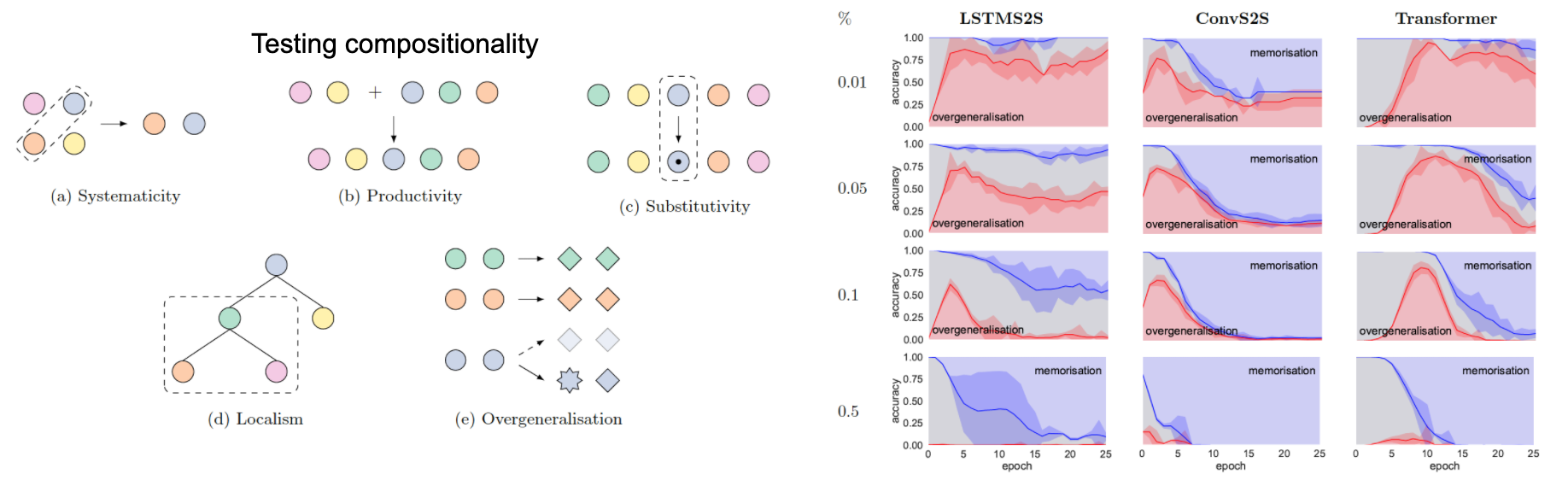
モデルの汎化能力を測る上で重要な概念に「合成性」があります。合成性とは、例えば文やフレーズ(例:「自然言語処理」)の意味が、その構成要素の意味(例:「自然+言語→自然言語」、「自然言語+処理→自然言語処理」)から合成して予測できる性質を表す言語学の概念です。この合成性に関して、SCAN と PCFG SET の2つのタスク・論文が発表されています。
後者の PCFG SET は、定数と演算子からなる人工的な言語を定義し、そこからモデルの合成性に関する振る舞いを調査するために作られたデータセットです。興味深いのは、このデータセットに「例外 (不規則動詞)」を人為的に混入させ、モデルの「丸暗記」と「過汎化」に関する振る舞いを詳細に分析している点です。例えば、人間が外国語を学習する際にも、「go」の過去形として「went (例外)」の代わりに「goed (過汎化)」と言ってしまう過ちを犯すことがあります。上のグラフの右側の図では、LSTM、畳み込みネットワーク、トランスフォーマーの各アーキテクチャについて、例外の存在下で、学習が進むにつれ、過汎化 (赤色) と丸暗記 (青色) がどの程度起きるのかをプロットしています。人間と同様に、学習の初期段階では過汎化(赤色)が起き、その後、個別の規則(青色)が学習されることが分かります。
ドメイン適用の分野には、これまで多数の研究が存在しています。ドメインの距離を測定するための類似度指標や、特徴量が数多く提案されています。
自然言語推論 (NLI) の限界と、自然言語生成 (NLG) の勃興
ここで紹介されている自然言語生成・変換モデルは、以下の記事にて詳細に解説しましたので、ここでは省略します。詳細については、以下の記事(有料会員限定)をご覧ください。
 萩原 正人
萩原 正人 萩原 正人
萩原 正人
頑健性の欠如
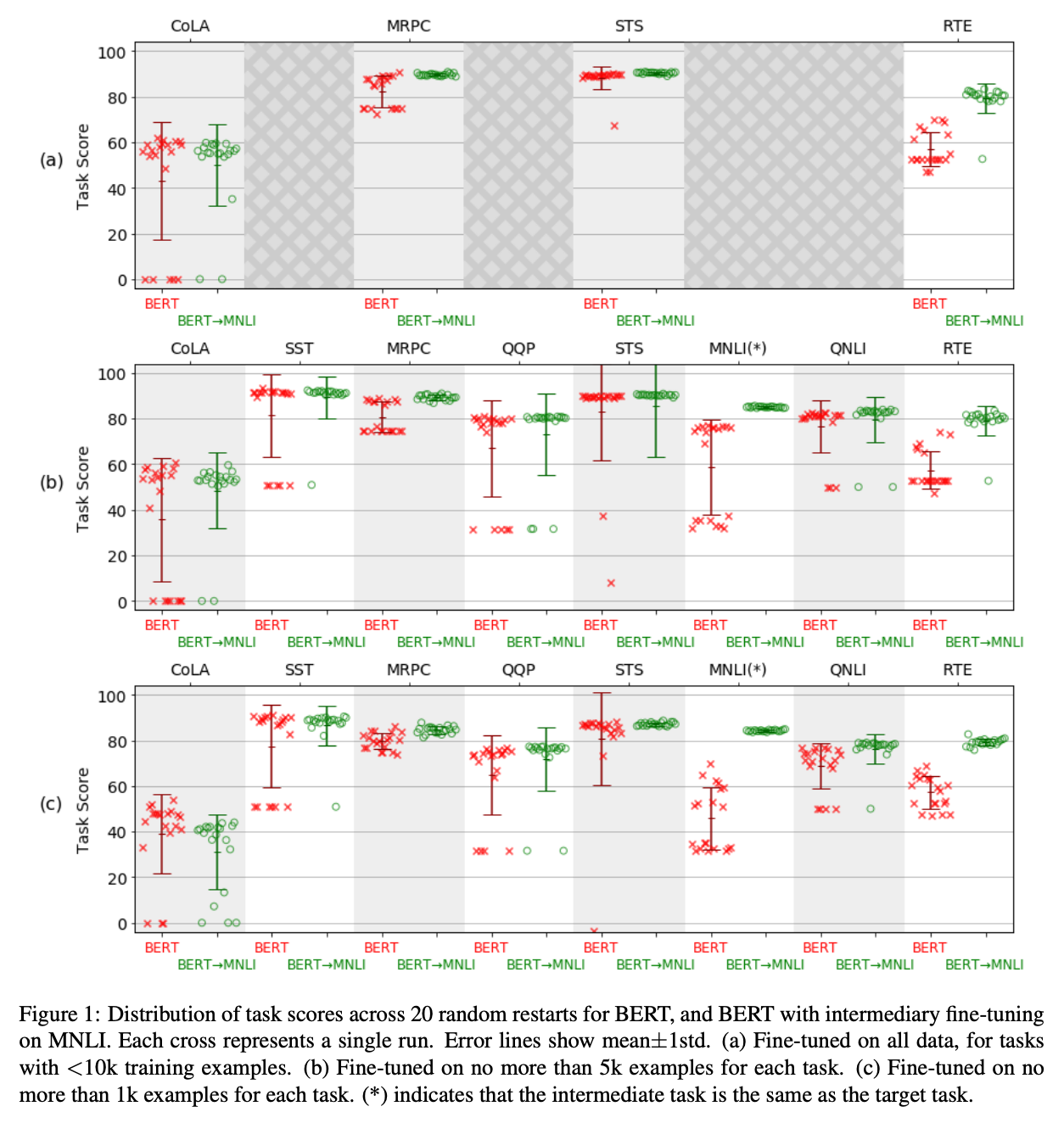
これまで、指数関数的に増えるデータ量とモデルサイズについて触れましたが、これらのモデルに共通の根本的な欠点があります。それが、頑健性の欠如です。
Phang 氏らの論文 では、BERT を、ランダムシードを変えて何回も fine-tune していますが、その結果はシードに非常に敏感であり、局所最小解に陥って性能が全く良くない場合も多くありました (上のグラフ参照)。この不安定性は、BERT を MNLI を中間タスクとして fine-tune するとある程度改善することも示されています。
この問題を解決するためには、「ハイパーパラメータ探索をとにかくたくさんする」という力技もありますが、他にも、正則化を工夫する、などの手法が提案されています。例えば、ICLR 2020 で発表された Mixout という手法 では、事前学習モデルを fine-tune する際に、ドロップアウト的に重みをゼロにするのではなく、事前学習の値にリセットする、という手法によって頑健性が向上することが示されています。Jiang 氏らの論文 では、fine-tune によってパラメータが大幅に変化しないような正則化と、それに対応した最適化手法を提案しています。Liu 氏らの論文では、マルチタスク学習とアンサンブルによって強力なモデルを訓練し、必要であれば蒸留によってモデルサイズを小さくすることにより、自然言語理解のタスクにおいて高い性能を達成しています。
このような手法は、確かにリーダーボードで上位を取るのには適しているのですが、かなり複雑になるという問題点があります。Stanford の Kevin Clark 氏が語る「GLUE のリーダーボードで上位を取る方法」によれば、大量のハイパーパラメータサーチ、アンサンブル、公式には認められていないトリック、データ拡張など、様々なトリックを組み合わせる必要があります。これは、確実に GLUE に過学習しており、理想的とは言えません。
これが問題になるもうひとつの理由は、チューニングに大量の計算量を必要とするからです。十分に強力なモデルは、大量にチューニングを走らせることによって、いずれ良い性能を達成してしまう可能性もあります。そこで、Dodge 氏らの 2019年の論文「Show Your Work: Improved Reporting of Experimental Results」 では、チューニング後の性能を単一の値として報告するのではなく、チューニングに要した計算量と、モデルの最大性能をグラフとして報告することを提案しています。これによって、「チューニングの計算量が少ないうちは単純なロジスティクス回帰の性能が高いが、その後はニューラルネットワークが優位になる」というような議論が可能になります。
また、モデルを評価する際には、データセットの「標準的な分割」を使って訓練・評価するのが一般的です。しかしながら、モデルの改善・評価を繰り返していく過程で、この「分割」に過学習してしまうということが起こります。Gorman 氏、Bedrick 氏の論文 では、これまでに発表された品詞付与モデルの性能を標準的ではない分割で評価したところ、これらのモデルのこれまでの順位を再現できなかったということです。
モデルは、本当に言語を理解しているか?—帰納バイアスに関する問題

帰納バイアス (inductive bias) は、機械学習モデルを議論する上でよく使われる言葉ですが、より良い解に導くためにモデルに導入する「仮定」「バイアス」のことを指します。
上の頑健性の議論とも関係しますが、モデルの不安定さも指摘されています。Jia 氏、Liang 氏の論文 では、機械読解の標準的なデータセットである SQuAD において訓練されたモデルについて、問題文に適当な(本文と関係ない)文を加えるだけで、出力が変化してしまう問題を論じています (上の図を参照)。
また、前述のMcCoy 氏らの論文 では、モデルの不正確さ、すなわち、真の関係ではなく、データセットにある表層的な関係やバイアスを学習してしまうという現象が指摘されています。
これらの問題に対しては、言語学的な知識を使い、帰納バイアスを組み込んだり、改善したりすることが提案されています。言語学が NLP へと「帰ってくる」ことにより、モデルに本当に学習してほしかった規則などをより良く評価できることが期待されます(詳細は、Ellie Pavlick 氏の「言語学は重要か? (Should we care about linguistics?」と題された講演が詳しいです)。例えば、上記の Hupkes 氏らの論文 で検証された合成性 (compositionality) は言語の重要な特徴ですが、合成性を正しく捉えられるモデルが、文の意味を正しく捉えられると考えられます。
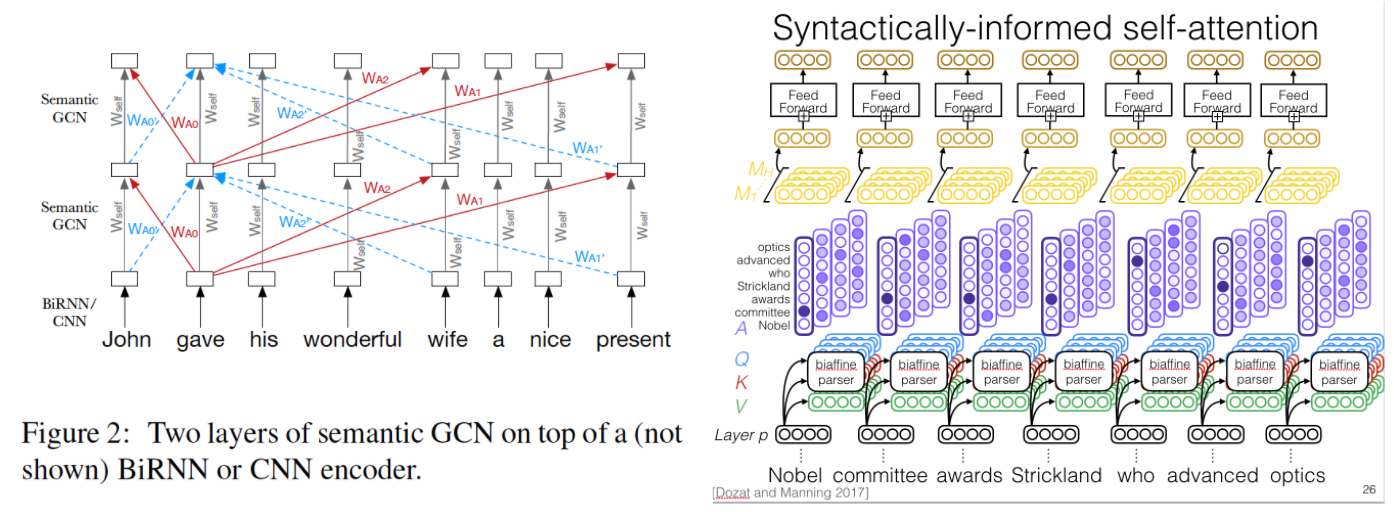
上記のような帰納バイアスをモデルに組み込む方法もいくつか提案されています。Marcheggiani 氏らの論文では、入力文の言語学的情報(述語項構造)をグラフ畳み込みネットワークにより取り入れたニューラル機械翻訳モデルを提案しています。また、Strubel 氏らの論文で提案された意味役割付与のタスクを解くモデルでは、マルチタスク学習の仕組みにより言語学的な情報を取り入れた自己注意機構を使っていす (ちなみに同論文は、EMNLP 2018 のベストペーパー賞に輝いています)。一方で、言語学的な知識(述語項構造)を考慮したデータ拡張手法を使うことも可能です。
自然言語処理は「常識」を扱えるか?
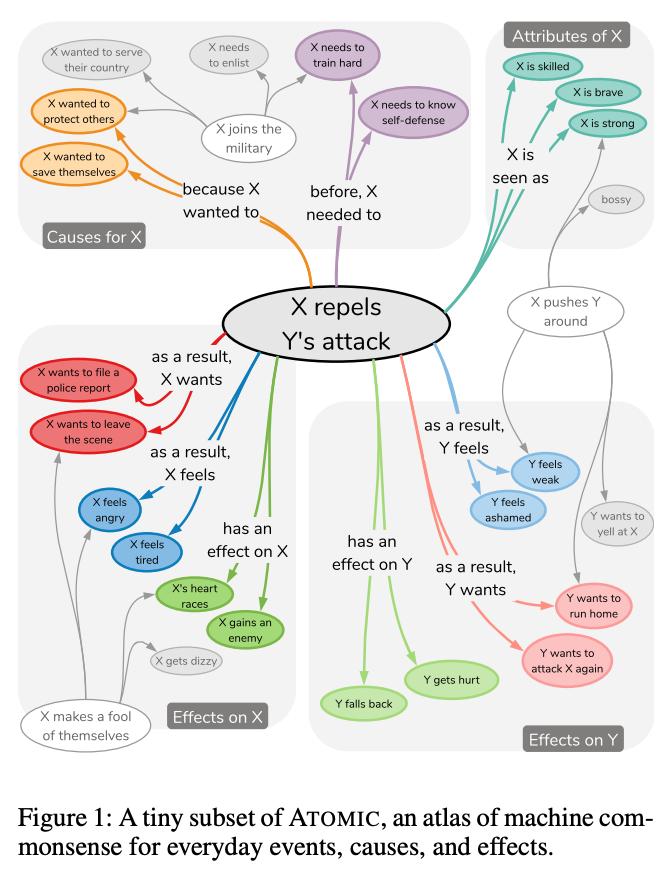
モデルを頑健にするもう一つの方法が、「常識を取り入れる」です。
常識の問題を難しくしているのが、「報告バイアス」と呼ばれる現象です。自然言語処理のモデルはテキストから訓練されますが、「羊は白い」などの常識はわざわざテキストに書かれることはほとんどありません。一方で、「黒い羊 (black sheep)」などの表現は良く出現します。このようなデータから学習されたモデルに「羊の色は?」と聞くと「おそらく黒」などと返ってきてしまう、ということになります。
この報告バイアスを解決する方法はいくつかあります。一つは、「羊→白」などの明示的な知識を含んだ知識ベースを用いる方法。他にも、画像など複数のメディアを使ったマルチモーダルな学習も可能です。最後に、人間参加型 (human-in-the-loop) の機械学習の仕組みを通じて、「人間に直接聞いてしまう」という方法があります。
常識の問題に対するアプローチとして重要なのは、評価・訓練用データセットの整備です。 この分野において伝統的に用いられているデータセットに「Winograd Schema Challenge (WSC)」というものがあります。このデータセットは、例えば、
「トロフィーは、茶色のスーツケースに入らなかったのは、それが大きすぎたからだ」 → 「それ」が指すのは、トロフィーか、スーツケースか
といった、代名詞が何を指すかを当てる問題から構成されています。これを解くには、スーツケースの方がトロフィーより大きい、などの常識が必要になり、長い間、深層学習モデルが良い性能を上げるのが難しいタスクでした。Kocijan 氏らの論文では、Wikipedia から自動的に類似した文を収集するデータ拡張手法を提案しています。(萩原注:WSC については、日本語データセットの翻訳・構築の研究も進んでいます)
この WSC ですが、近年の高性能なモデルが、徐々に高い精度 (90% 以上) を達成しつつあります。ただし、これらのモデルは真に汎用可能な常識推論能力を持っているのでしょうか、それとも、データセットに特有の表面的な特徴を学習しているだけなのでしょうか?

坂口氏らの論文 では、「WinoGrande」と呼ばれる、規模・難易度ともに WSC を上回る新しいデータセットを作成しています。クラウドソーシングを使って多様な問題を作るために、ランダムに選んだ記事から「アンカー」と呼ばれる単語を使って文を書いてもらいます。また、RoBERTa から得られた埋め込みに基づいて簡単に答えられる問題を敵対的に削除し、表層的に答えられない難しい問題のみを残しています (上表の下2行)。
こうして作られた問題は、人間は 94% の精度で正しく答えられますが、RoBERTa ベースの手法は最大で 79.1% 程度の精度しか出ないということです。一方で、こうして作られた WinoGrande を用いて中間的に fine-tune したモデルを従来の WSC 型データセットにおいて評価すると、複数のデータセットで従来手法を上回る最大性能を達成したとのことで、WinoGrande が転移学習に有効であることを示しています。ただ、これらの結果は、従来のデータセットに内在する無関係なバイアスによる可能性も高く、常識推論に関する真の能力を過大評価している可能性もある、と著者らは警告しています。
ちなみに、常識+NLP の分野では、ワシントン大学の Yejin Choi 氏のグループの業績が突出しています。Choi 氏のグループでは、クラウドソーシングによって作られた常識に関する関係データベース ATOMIC や、トランスフォーマー的なモデルを用いて知識グラフの補完を行う COMET など、数多くの成果を出しています。
事前学習モデルの進化は、2018年で止まってしまうか?
上の WinoGrande の例からもわかるように、より強力なモデルが出現すれば、データセットもそれに応じて進化していくことが望ましいでしょう。一方、モデルの方はどうでしょう?BERT は、2018年までのテキストで訓練されていますが、2018年時点での知識しか持っておらず、例えば何年経っても米国の大統領は同じだと考えてしまうかもしれません。
モデルを絶え間なく進化させていく「継続学習 (continual learning)」には、コンピュータービジョンなどの分野で多くの研究があります。継続学習で問題となるのは、新しいことを学習させていくと、前に学習したことをすっかりと忘れてしまう「破滅的忘却 (catastrophic forgetting)」の問題です。このため、記憶を使ったり、正則化、タスク依存のウエイトを工夫したりなど、様々な手法が提案されています。NLP も、新しいデータやドメインに適応し、汎化できるような方向性に進んでいくことでしょう。
関連記事
萩原 正人 萩原 正人
萩原 正人