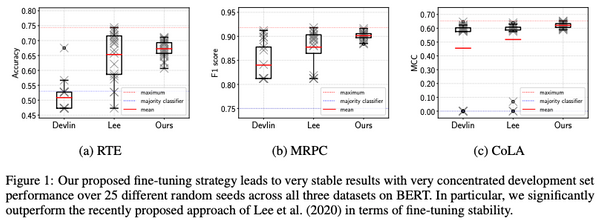
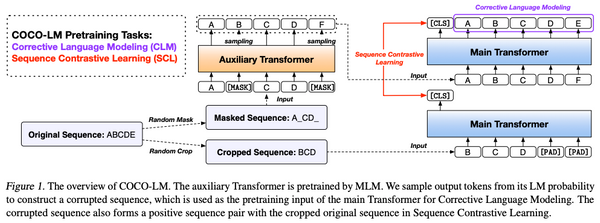
Free Post 自然言語処理 BERTとトランスフォーマーはこう使え 「効果的な訓練・微調整のコツ」総まとめ BERTやトランスフォーマーを使った自然言語処理が普及していますが、これらのモデルを効果的に訓練・微調整をするためには未だに「職人芸」的なテクニックが必要となります。「これを知っているだけで BERT とトランスフォーマーの訓練・微調整が劇的に安定・改善する」という手法を比較・検討した論文が最近になっていくつか出てきましたので、まとめて解説したいと思います。
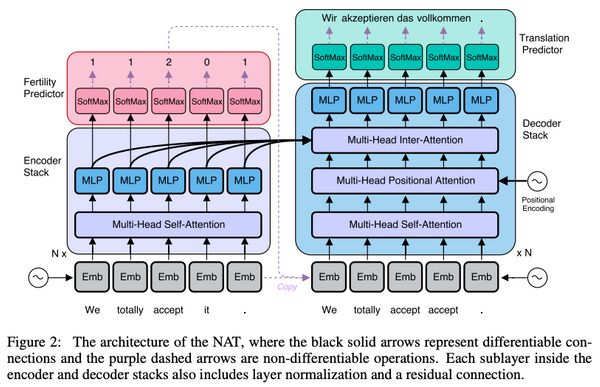
Free Post 自然言語処理 機械翻訳のパラダイムが変わる!?非自己回帰的なテキスト生成・機械翻訳の最前線 単語を並列かつ高速に生成することのできる「非自己回帰的」なテキスト生成・機械翻訳手法が、2018年ごろから盛んに研究されています。最近になって、従来の自己回帰的なモデルに比べて大幅に高速でありながら、翻訳精度で匹敵するような手法も出現し始めました。本記事では、ごく最近の研究成果も含めた、「非自己回帰的 (non-autoregressive)」なテキスト生成・機械翻訳の研究トレンドを紹介します。
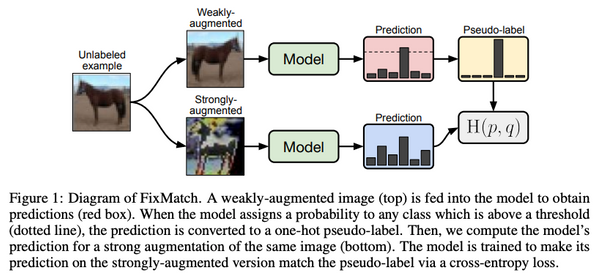
Free Post 機械学習 シンプルかつ効果的!深層学習で復活した「自己学習」の最新研究トレンド モデル自身を使ってラベル無しデータに「疑似正解」を付与、そこから新たなモデルを学習する「自己学習」 (self-training)。近年の深層学習技術の発展に伴って、その有効性を示す研究が画像・言語・音声の全分野で数多く発表されています。本記事では、その「自己学習」の最新の研究トレンドをいくつか紹介したいと思います。
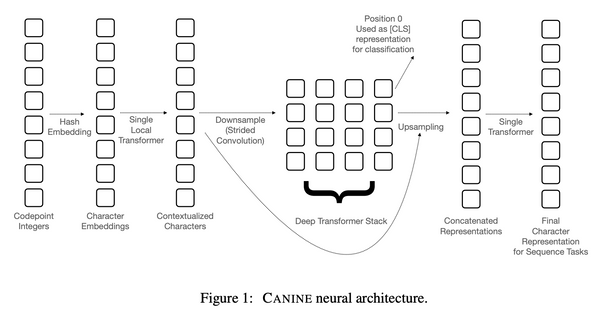
Free Post 自然言語処理 日本語処理にも革命!?分かち書きをせず高品質な事前学習を実現する CANINE がすごい 【論文速報】 自然言語処理において避けては通れない前処理である「分かち書き」を全くすることなしに、高品質な事前学習言語モデルを訓練する CANINE (ケイナイン) という手法に関する論文が発表されました。「これからの日本語処理のやり方を根本的に変えてしまうかもしれない」とあまりに衝撃を受けたので、論文速報として解説したいと思います。
Free Post 自然言語処理 人気急上昇中!自然言語処理における対照学習の最前線 データの類似・非類似関係を使って自己学習する手法である対照学習。画像認識などの分野において近年急速に応用が進んでいますが、自然言語処理における応用も、ここ1〜2年で活発に研究されています。本記事では、ごく最近提案された主な対照学習+自然言語処理の手法を取り上げて解説します。
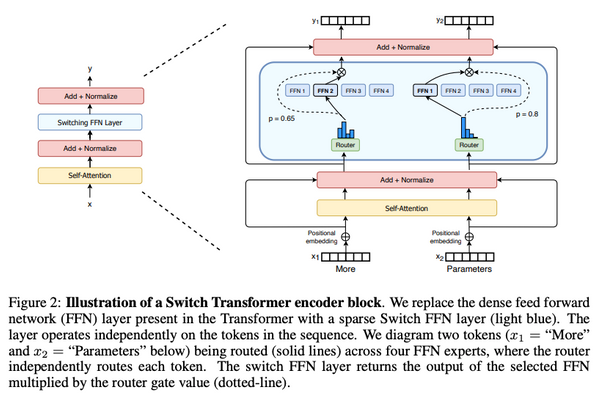
Free Post 自然言語処理 ついにパラメータ1兆個超え!スイッチ・トランスフォーマーと混合エキスパートモデルを完全解説 2021年1月に発表された「スイッチ・トランスフォーマー」の論文、「ついにパラメータが1兆個超え」ということで話題になったのが記憶に新しいかもしれません。本記事では、そのスイッチ・トランスフォーマーの論文を、前身となった混合エキスパート (MoE) モデルにさかのぼって解説したいと思います。
Free Post 自然言語処理 マルチリンガル自然言語処理が幅広く学べる カーネギーメロン大講義がオススメ 昨年の5月に、低リソース自然言語処理ブートキャンプが開催されました。カーネギーメロン大の一線の研究者による、低リソース自然言語処理のチュートリアルと、実際のデータセットやライブラリを使った演習が盛りだくさん。本記事では、講演をまとめ訳と共に紹介します。
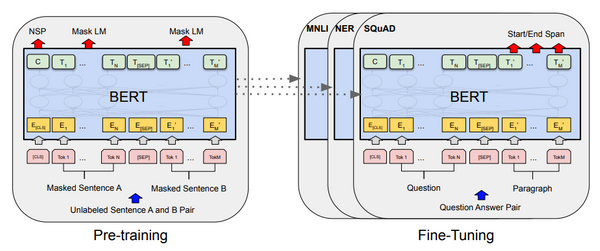
Free Post 自然言語処理 【2021年最新版】日本語BERTを徹底比較 事前学習言語モデルのオススメはこれ 日本語で、BERT などの事前学習モデルを使った自然言語処理タスクを解く機会が増えてきました。しかし、BERT だけでも、様々な研究機関・企業が、訓練データ、サイズ、分かち書きの方法等の異なる様々なバージョンを公開しており、「どれをどう使ったら良いかよく分からない」という方も多いのではないでしょうか。この記事では、2021年1月の現段階で公開されている様々な BERT のモデルのタスク性能を比較し、現時点でのオススメについて紹介してみたいと思います。
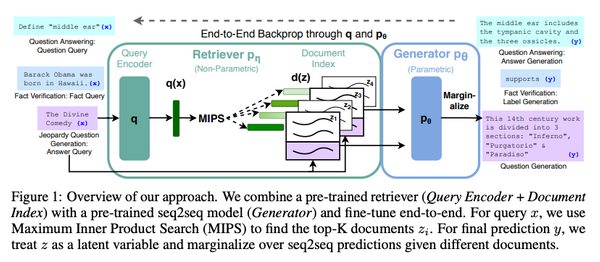
Free Post 自然言語処理 検索・書き換えに基づくノンパラメトリックな言語モデルの最前線 近年、知識をモデルのパラメーターとして全て表現するのではなく、何らかの外部知識として表現して利用する「ノンパラメトリック」手法がさかんに研究されています。これらの手法は「検索ベース」手法とも呼ばれており、外部知識から関連する文を検索したり、書き換えたりすることによって、パラメトリックなモデルの欠点を補うことができます。本記事では、これらノンパラメトリックな言語モデルに関する最近の手法のうち、メジャーなものをいくつかピックアップして紹介します。
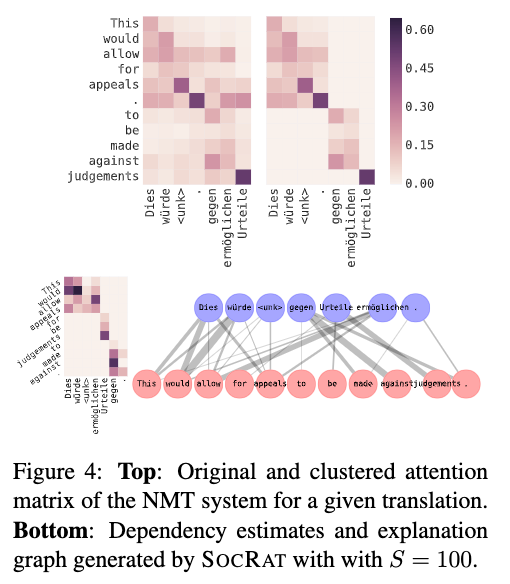
Free Post 機械学習 説明可能な人工知能(XAI)とは?機械学習のモデルを説明・解釈する最新手法まとめ 近年、ニューラルネットワークに基づく大規模な深層学習モデルの普及によって、機械学習の様々なタスクにおいて非常に高い性能が達成されています。一方、これらのモデルは、伝統的な線形回帰や決定木などのモデルと比べて、どのような仕組みで予測が出力されているかが分かりにくい「ブラックボックス化」しているという問題があります。最近、NeurIPS、ACL などのトップ会議において、この「説明可能な人工知能」に関するチュートリアル講義が相次いで開催されました。本記事では、これらのチュートリアルから厳選した、「押さえておくべき説明・解釈手法」をいくつかご紹介します。
Free Post 自然言語処理 2020年最新版 モダンなフレームワークで実装する深層自然言語処理モデル 近年では、深層学習モデルを使って自然言語処理タスクを解く機会が増えていますが、モデルを開発・実装する方法にはさまざまなものがあります。機械学習モデルの開発には試行錯誤が必要となるので、どのフレームワークを使って実験を進めていくのかは大切な要素の一つです。本記事では、2020年の現在において、BERT のような事前学習モデルを使った深層自然言語処理の研究開発において、ベストプラクティスであると思われるフレームワーク、手法をコード例と共に紹介していきます。
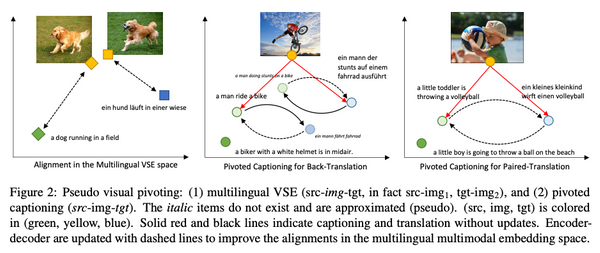
Free Post コンピュータービジョン 人工知能の次のフロンティアとは?視覚×言語研究の最新動向 大量のテキストから事前学習した BERT や GPT-3 などの事前学習モデルに関する研究が話題ですが、人間の言語理解には、視覚・聴覚などとの相互作用、身体性・社会性が非常に重要です。この記事では、近年注目が高まっているマルチモーダル自然言語処理、特にその中でも、視覚×言語の最新の研究をいくつか取り上げ、紹介してみたいと思います。
Free Post 自然言語処理 自然言語処理トップ会議 EMNLP 2020 から厳選 重要論文・講演のまとめ 先週、自然言語処理分野のトップ会議のひとつである EMNLP 2020 がオンラインで開催されました。近年の AI/ML 系の学会の例に漏れず、本会議だけで 700本以上の論文が採択され、とても全部をチェックできる量ではありません。本記事では、EMNLP 2020 の中から、ベストペーパーとその佳作賞、重要な講演や論文などを厳選して紹介します。
Free Post 自然言語処理 WordPieceからBPE-dropoutまで 〜 ニューラル時代のサブワード分割・トークン化手法 完全ガイド 深層学習を用いた自然言語処理では、テキストを「サブワード」と呼ばれる単語よりも短い単位に分割する手法が頻繁に用いられます。本記事では、WordPiece, Byte-pair encoding (BPE), SentencePiece など、数多くあるサブワード分割の手法・ソフトウェアを取り上げ、それぞれの特徴や違いなどを解説します。
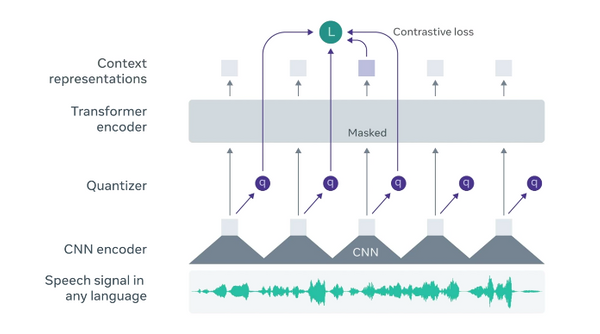
Free Post 音声認識 音声認識に「BERT 革命」がついに—音声に対する事前学習の最前線 高精度な音声認識モデルを訓練するには、大量のラベル付き学習データ(音声と、それを文字起こししたもの)が必要であることが知られています。画像認識 (ImageNet) や自然言語処理 (BERT) の分野において成功を収めた転移学習の手法は、音声認識の分野では有効ではないのでしょうか?本記事では、現在 (2020年10月) の段階における「音声認識の転移学習革命」の最前線を追ってみたいと思います。以下で紹介する手法を追ってみると、音声認識の分野でも「ImageNet 的瞬間」が着実に進んでいることが分かります。