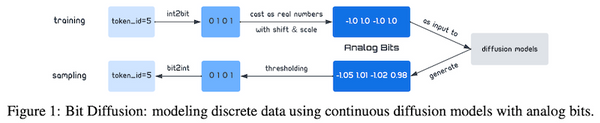
Free Post 自然言語処理 言語にも拡散モデル革命か 離散データを生成する「ビット拡散」を解説 最近、テキストから高品質な画像を生成するモデルが世間を賑わせていますが、その多くは「拡散モデル」に基づいています。画像のピクセルなど、連続値データを生成するのは得意な拡散モデルですが、テキストなどの離散データの生成についてはあまり上手く行っていませんでした。最近になって、離散データをビット列として拡散モデルで生成する「ビット拡散」が発表されました。非常にシンプルながら強力な手法であり、今後の発展が望めます。本記事では、このビット拡散を関連研究と共に紹介します。
Free Post 自然言語処理 JAX/Flax と TPU を使って大規模言語モデルを爆速で訓練するチュートリアル 「第3の深層学習ライブラリ」として、2年ほど前から徐々に普及が進んでいる JAX/Flax。昨年、本ブログで記事として取り上げてからも、様々な学習資料が公開されたり、実際の機械学習モデルの訓練に採用されたりと、普及が進んでいます。本記事では、基礎を簡単におさらいした後、JAX/Flax と TPU を使い、「日本語の大規模言語モデル」を高速に訓練する方法をチュートリアル形式で解説します。
Free Post 自然言語処理 新たなタイプの自然言語処理!言語モデルを賢く使うテクニック10選 GPT-3 などの大規模・汎用言語モデルの出現によって、自然言語処理においてタスクを解くやり方にも変化が生じています。タスクやドメインごとにモデル・手法を工夫するかわりに、プロンプトとしてどのように指示を与えるか、言語モデルとどのようにやりとりするか、という点に焦点が移っています。本記事では、言語モデルを使って、数値計算・論理推論などの複雑な問題を、より精度高く解かせるための手法に関する研究およびトレンドを、ごく最近発表された論文も含め10個ほど紹介します。
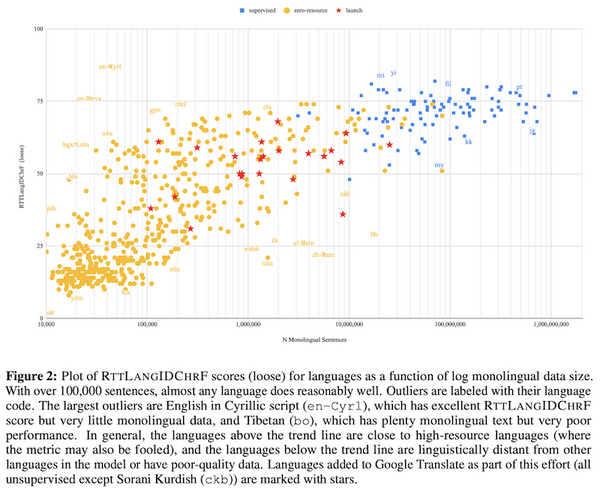
Free Post 自然言語処理 最新の機械翻訳技術の総集編!Googleが1,000言語を訳せる秘密とは 機械翻訳がまだ対応できない「次の 1,000 言語」を翻訳できるニューラル機械翻訳システムを構築するには?最近 Google から発表された論文では、超多言語モデリングと近年のニューラル機械翻訳の技術を駆使し、グーグル翻訳に低資源言語を追加するプロセスが詳細に解説されています。近年の深層機械翻訳に関する有用なテクニックの総集編としても読め、機械翻訳に関わる人以外にもオススメです。
Free Post 機械学習 単純かつ効果的!訓練順序を工夫する「カリキュラム学習」とNLP応用 人間が学習するように、難易度に応じてデータを提示する順序を工夫する「カリキュラム学習」、シンプルかつ効果的な方法として研究が進んでいます。本記事では、カリキュラム学習の基礎をおさらいした後、自然言語処理における代表的な応用例 (機械翻訳、音声翻訳、自然言語理解、チャットボット) を幅広く紹介・解説します。
Free Post 自然言語処理 自然言語処理トップ会議 ACL 2022 から厳選!要チェック論文まとめ 先週 (5月22日〜27日)、自然言語処理のトップ会議である ACL 2022 がオンラインおよび対面のハイブリッド形式で開催されました。本記事では、ACL 2022 の論文の中から、現時点での引用数や、幅広い研究や開発に役立つかどうかなど、私の主観なども混ぜながら、要チェック論文を選んで解説しました。
Free Post 機械学習 深層学習トップ会議 ICLR 2022 の要注目論文まとめ【NLP/ML一般編】 先月末、「深層学習のトップ会議」とも言える ICLR 2022 がオンライン上で開催されました。本ブログでは、全 1,095 本の採択論文の中から要チェック論文を厳選し、2週間に分けて紹介します。今週は 自然言語処理 (NLP) と機械学習全般に関する論文です。いずれの論文も、新しい概念を提案する挑戦的なものや、実務に使える実用的なものを中心に厳選しました。
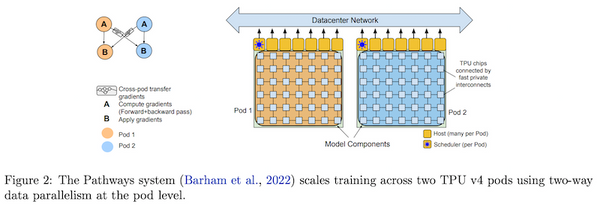
Free Post 自然言語処理 ついに出た!Googleによる最強・最大の言語モデル PaLM を解説【論文速報】 Google から、超大規模言語モデル PaLM (「パーム」、Pathways Language Model) が発表されました。パラメータ数 540B (5400億) の本モデル、現段階で「最強・最大の言語モデル」と言っても過言ではなく、言語理解、コーディングタスク、多言語タスクなど、様々な分野で最高性能 (SOTA) を軒並み達成しています。本論文、付録 (appendix) を除いた論文の本体だけで 62 ページもある大作なので読むのも大変なのですが、本記事では、その中でも重要な要点をかいつまんで紹介します。
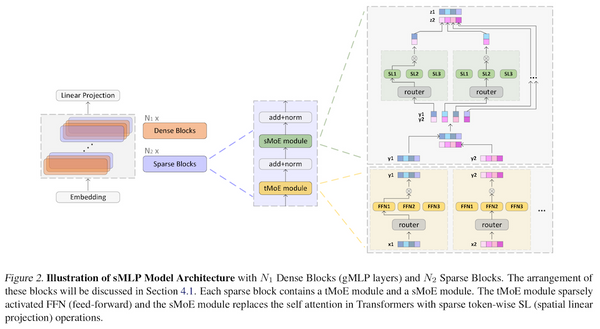
Free Post 自然言語処理 NLPでトランスフォーマーを超えた!? 多層パーセプトロン研究の最前線 昨年から活発に研究されている多層パーセプトロン (MLP) モデル。自然言語処理 (NLP) の分野ではあまり性能が振るいませんでしたが、最近になって、NLP タスクでも「トランスフォーマー超え」を達成するモデルが立て続けに発表されています。本記事では、最近発表された期待の MLP モデル、HyperMixer と sMLP を解説します。
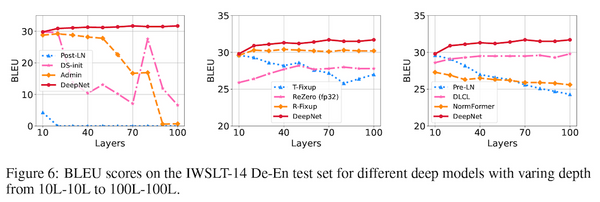
Free Post 機械学習 1,000層超えも!超深層トランスフォーマーを実現した DeepNet を解説【論文速報】 トランスフォーマーは非常に強力なモデルですが、レイヤーの数を増やしていくと訓練が不安定になることが知られています。最近、トランスフォーマーの訓練を安定させ、1,000層にも及ぶ「超深層トランスフォーマー」を訓練できる DeepNet が Microsoft Research から提案され、機械翻訳において目覚ましい成果を上げ話題になっています。本記事では、DeepNet とその正規化手法である DeepNorm を、論文速報として解説します。
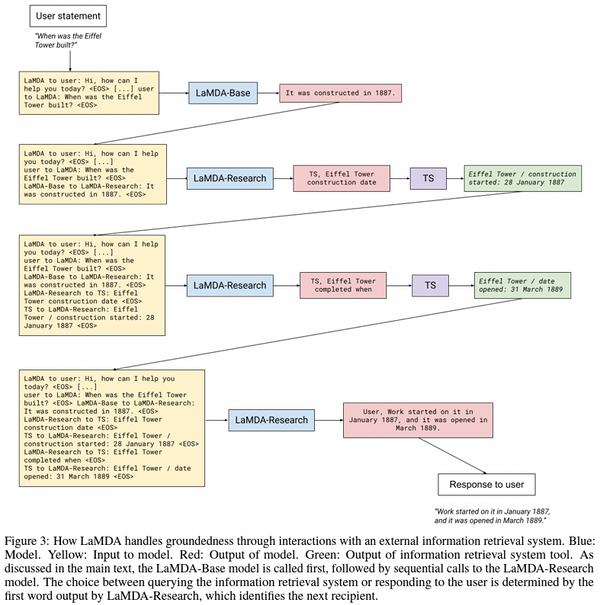
Free Post 自然言語処理 進化を続ける大規模言語モデルの最前線 (LaMDA, GPT-NeoX-20B, XGLM) 前回、本ブログにおいて超巨大言語モデルについて取り上げてから数ヶ月しか経っていませんが、大規模言語モデル分野では興味深い研究・モデルが次々と発表されています。特に、GPT-NeoX-20B など、訓練データ・コード・モデルなど、すべてオープンソースで利用できる言語モデルがいくつか発表されています。本記事では、最近のこれらの大規模言語モデルの傾向を紹介します。
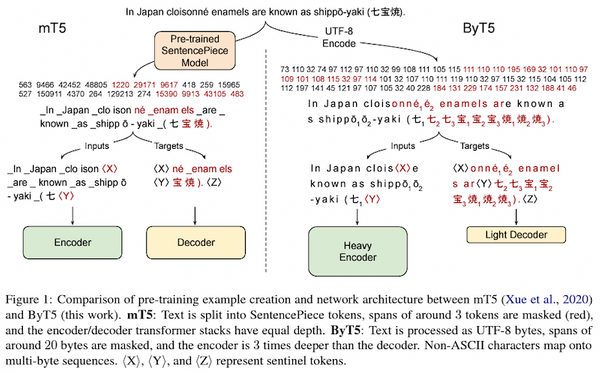
Free Post 自然言語処理 NLP における分かち書き最適化・分かち書きフリー手法の総まとめ 自然言語処理分野では、最近、入力を文字・バイト・ピクセル単位でそのまま処理する「分かち書きフリー」の手法が多数出現しています。また、トークン単位に分割する分かち書きを対象タスクと合わせて最適化する手法に関する研究も進んでいます。本記事では、これら「分かち書きフリー」「分かち書き最適化」の手法に注目し、最近の動向を解説しました。
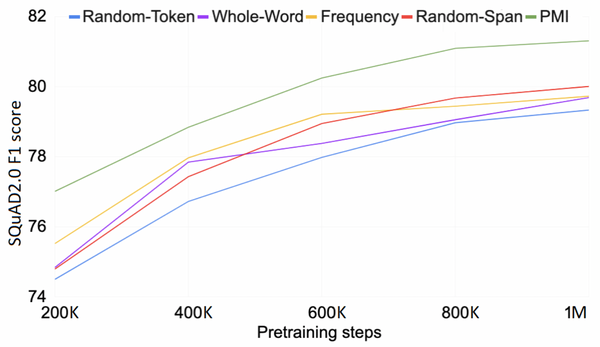
Free Post 自然言語処理 穴埋め言語モデルを「内閣■■大臣」のような簡単な練習問題で甘やかさないコツ【じっくり1本】 マスク言語モデルは、黒塗りしたテキストを復元するという練習問題を何億問も解くことで汎用のテキストエンコーダに成長します。ところが練習問題の中には文全体を見なくても解けてしまう簡単なものがたくさん含まれています。今回紹介する ICLR 2021 の論文では、これらの簡単すぎる問題を難しい問題に差し替えると言語モデルの品質が向上する… という面白い話が示されています。前提知識の説明からじっくり1本ご紹介します。
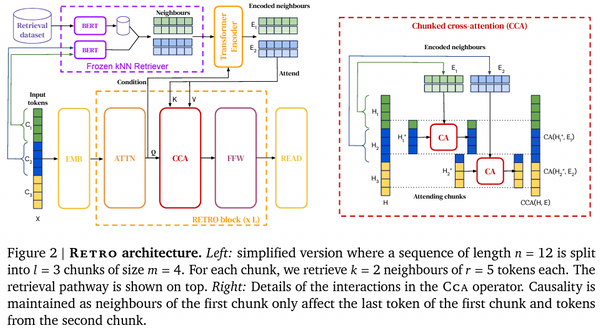
Free Post 自然言語処理 GPT-3超えが続々と登場 発展を続ける超巨大言語モデルの最先端 GPT-3 が発表されて既に1年以上、「GPT-3 超え」を達成する超巨大言語モデルがその後も次々と発表されています。本記事では、最近 DeepMind から発表された Gopher / RETRO をはじめ、最近発表され「GPT-3 超え」を達成した数々の大規模言語モデルを解説しました。
Free Post 自然言語処理 トップ会議 EMNLP 2021 から学ぶ 文埋め込み・言語モデル研究の最前線 3週間ほど前に、自然言語処理分野のトップ会議のひとつである EMNLP 2021 がオンライン・オフラインのハイブリッド形式で開催されました。新しく強力な文埋め込みモデルや、トランスフォーマー・モデルの新たな解釈・変更の検証など、興味深く実用的な研究が多数発表されています。本記事では、EMNLP 2021 において発表された論文から厳選した注目論文を分かりやすく解説します。