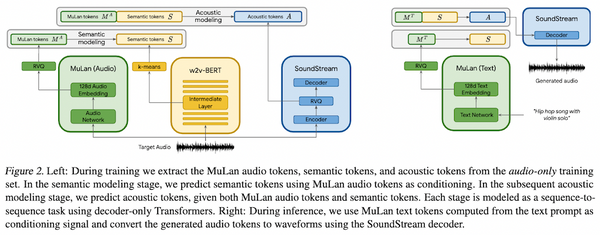
Free Post 音楽情報処理 2023年に爆発的な進歩!テキストからの音楽・オーディオ生成の最前線 2023年になってまだ1ヶ月ですが、世界中の研究機関から「テキストからの音楽・オーディオ生成」を実現する手法・論文が矢継ぎ早に 10 本以上も発表され、「画像・ChatGPT の次に AI が革命を起こすのは音楽か」と世間を賑わせています。本記事では、2023年に入って最近発表された「音楽・オーディオ生成 AI」の主要な論文・手法をまとめて解説しました。2022年の比べ、高品質・長時間かつテキスト入力に忠実な音楽を生成できるようになっており、進歩の早さは目をみはるものがあります。
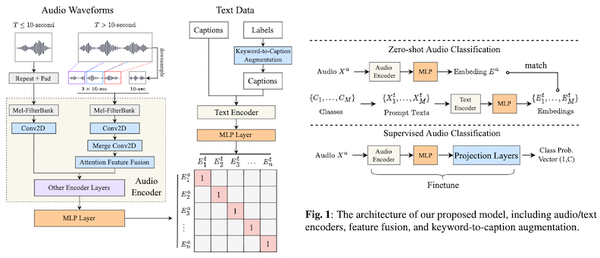
Free Post 音楽情報処理 拡散モデルがここにも オーディオ・音楽生成の最新手法を解説 拡散モデルを使った近年の画像生成 AI の成功を受け、その他の分野にも「拡散モデルの波」が押し寄せています。オーディオ・音楽の生成も例外ではなく、CLIP 的にオーディオとテキストの関連をとらえる「CLAP」や、拡散モデルによって高品質なオーディオ・音楽を生成するモデルなどが次々と発表されています。本記事では、最近発表されたオーディオ・音楽生成モデルの最新動向をまとめました。
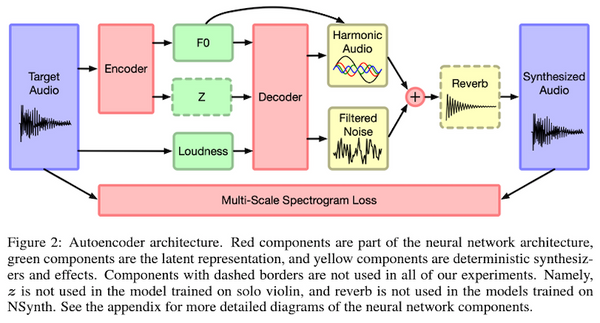
Free Post 音楽情報処理 微分可能なデジタル信号処理 (DDSP) とオーディオ生成の最新動向 シンセサイザーなどのドメイン知識に基づきながらも、パラメータ等を微分可能にすることにより、生成品質と手軽さ、解釈性のバランスの取れた「微分可能なデジタル信号処理 (DDSP)」による音声・オーディオ生成およびその関連手法の利用が広まっています。本記事では、DDSP の基本からスタートし、最新の論文まで含め、関連する文献をまとめました。
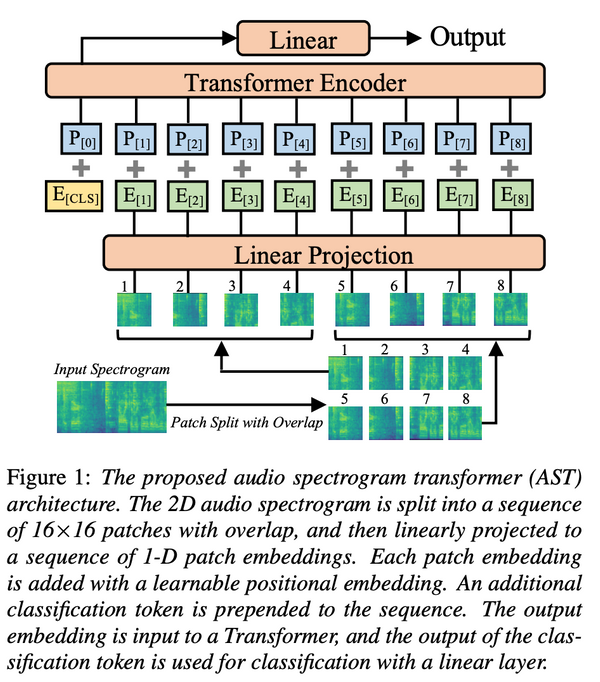
Free Post 音声認識 音声にもパッチ化・MLP・CLIPの波が 音声に対する深層学習の最先端 本記事では、オーディオ・音声に対する深層学習モデルのうち、比較的最近発表された論文を中心にトレンドを追ってみます。特に、オーディオを対象にビジョン・トランスフォーマーの仕組みを適用した AST は、仕組みも簡単で性能も良く、音声ドメインにおいて今後も注目です。
Free Post 音楽情報処理 深層学習を使った音楽生成・音楽表現学習の最先端【2021年最新版】 生成モデル・表現学習の急速な発展に伴い、音楽生成・音楽表現学習の分野にも大きな変化が起きています。ここ2〜3年の間に、長い楽曲を安定して生成できたり、楽器や楽曲のオーディオを直接生成できたりと、芸術的・実用的にも大きく進歩しています。本記事では、特に 2018年〜2021年のごく最近の研究を中心に最新動向を解説してみたいと思います。