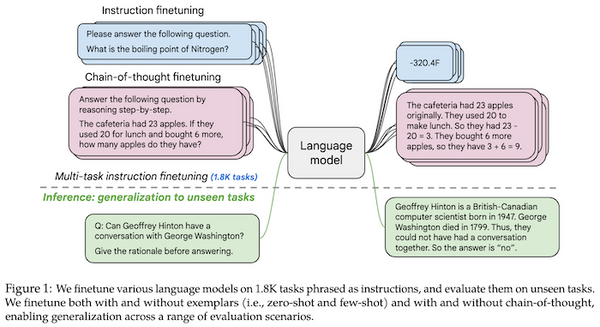
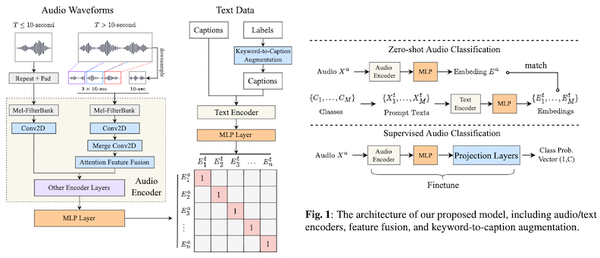
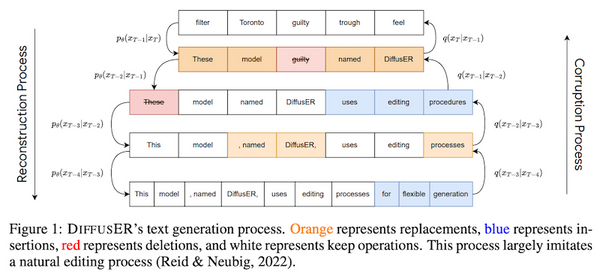
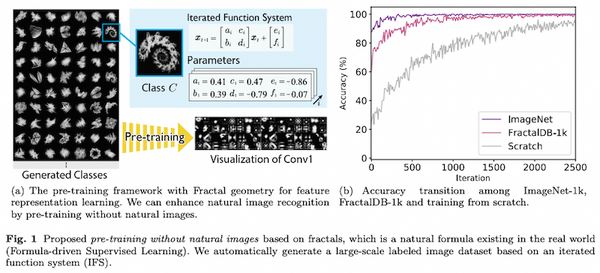
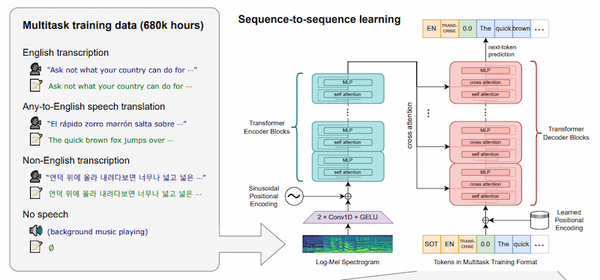
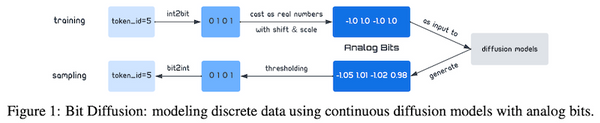
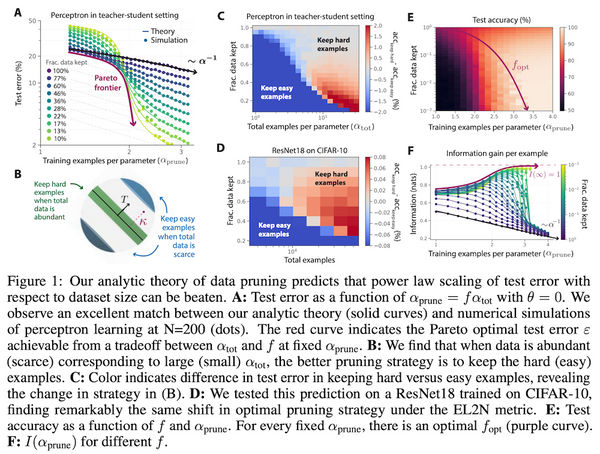
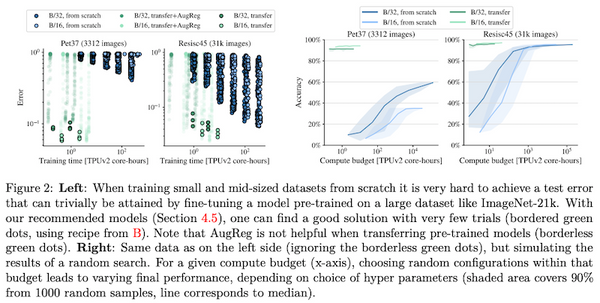
先週、OpenAI から、オープンソースの音声認識モデル「Whisper」が発表されました。この Whisper、なんと 68 万時間もの訓練データで訓練された大規模な音声認識モデルで、英語で人間に匹敵する高い性能を上げたうえ、日本語を含む多言語の音声認識、音声翻訳、言語認識、音声区間検出なども可能です。これまでの AI コミュニティの反応を総合すると、総じて「これはすごい」というもので、今後の音声認識の研究・実用に大きな影響を与えるものと思われます。本記事では、この OpenAI の Whisper の論文を読み解き、そのデータ・モデルの詳細、今後予測されるインパクトなどを解説しました。