本ブログ「ステート・オブ・AI ガイド」のサービスは 2023 年 3 月 31 日 (金) をもちまして正式に終了させていただくこととなりました。なお、購読中の読者の方は、各自購読プランの解約を、必ずご自身で行うようお願い申し上げます。 購読プランを解約しない限り、4月以降も継続して課金されてしまいます。解約の方法、問い合わせ先などの詳細につきましては、こちらのアナウンス記事をご参照ください。
文責:高木志郎
近年の言語モデルの躍進には皆さんも驚かれていることと思います。そんな言語モデルにもまだ苦手なことがあります。例えば、存在しないはずの事実をでっち上げたり、最新の出来事には対応できなかったりします。また、数学的な能力でもまだ完璧に正確に答えることができない時もあります。
しかし、人間も必ずしもこれらを頭の中だけで正確にできる訳ではありません。人間も知らない事実について聞かれた時には検索して情報を探しますし、複雑な計算には計算機の力を借ります。これと同じように、言語モデルにもツールを使用できるようにすることで、言語モデルの能力を拡張しようというのがツール拡張言語モデルの研究です。
検索エンジンやインタープリタ、ブラウザなどを真に活用することができれば、人間の行動のかなりの部分を代替する非常に強力なものとなることは間違いありません。その潜在的な影響力の大きさから、多くの研究者やエンジニアがこの分野に参入し始めています。最近では、3/24 に OpenAI が ChatGPT にツール使用の機能を実装したことでも話題になりました。

このように、ツール拡張された言語モデルは 2023 年の大きな注目技術の一つとなることが予想されます。そこで、本記事ではツール拡張言語モデルに関連する研究のうちのいくつかをご紹介します。
ツール使用の研究には、検索をするもの (Komeili et al., 2022、Thoppilan et al., 2022、Shuster et al., 2022、Lazaridou et al., 2022、Yao et al., 2022)、Python のインタープリタを用いるもの (Gao et al., 2022、Chen et al., 2022)、計算機を用いるもの (Thoppilan et al., 2022)、ウェブブラウザを用いるもの (Nakano et al., 2021) などがあります。
以下の画像は Komeili et al., 2022 から抜粋したものです。人間が投げかけた質問に言語モデルが回答する状況を表しています。この例では、質問を受けたモデルが検索をして、その結果をもとに回答をしています。例えば一番上の応答の例では、人間が「お腹が空いたのでイタリア料理が食べたい」と投げかけています。モデルは "italian food" という単語を検索してまずイタリア料理には何があるのかを調べています。その結果のおかげで、「ピザやパスタやラザニア」といった具体的なイタリア料理の名前を挙げて返答することができています。

ツール拡張言語モデルは多くの場合このように適切にツールを呼び出すことで、自身の能力を拡張しています。
この記事では、ツール使用に関連する研究のうち、4 つの研究を紹介します。最初の 2 つは、言語モデルに与えるプロンプト内にツール使用のトリガーとなるトークンを埋め込む研究です。モデルはこのトークンを生成することで、ツールを呼び出すことを学習します。具体的には、Schick らによる Toolformer (Schick et al., 2023) と、Paranjape らによる ART (Paranjape et al., 2023) を紹介します。
次の 2 つは、言語モデルにブラウザ操作をさせる研究です。テキストで記述された指示やウェブページを観測として、ブラウザ上の操作に対応する行動を生成する強化学習環境として、定式化されています。具体的には、Nakano らによる WebGPT (Nakano et al., 2021) と、Yao らの WebShop (Yao et al., 2022) を紹介します。
Toolformer
はじめに紹介するのは、Toolformer です。Toolformer は Schick らによって提案された手法です (Schick et al., 2023) 。
Toolformer 登場以前もツールを用いた言語モデルの研究はありました。しかしそれらの手法は、大量の人手によるラベル付けが必要だったり、タスク特化した手法であったりといった問題がありました。Toolformer は、1. 自己教師ありの力を借りて少数のラベルを使用し、2. いつどのツールを使うかも含めて学習することで高い汎用性を可能としています。
以下の図は Toolformer の出力のイメージ図です。

[] の部分がツールが呼ばれたことを表していて、矢印の前が使用したツールと渡した引数、矢印の後がその結果になっています。異なる色はそれぞれ異なるツールを表しており、QA は質問応答モデル、Calculator は計算機、MT は言語翻訳モデル、WikiSearch は Wikipedia での検索を表しています。
例えば、2 段目の計算問題では、〜 or という部分まで入力されたところで計算機を呼び出しています。そして 400 / 1400 を計算し、その答えである 0.29 をパーセント表示した 29 % を返答として返しています。
これらのツールはいずれも API という形で提供されています。したがってツールを使用するとは、API を呼び出すことに他なりません。そこで Toolformer では API トークン <API> を用意します。そして、モデルがこのトークンを生成したら API が呼び出されるようにしています。
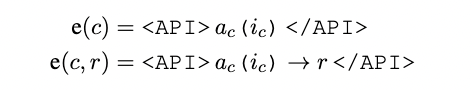
このような定式化となっているので、ツール呼び出しの内部はブラックボックスとなっています。すなわち、言語を受けて言語を返すツールであれば、どんなツールでもこの枠組みの中で扱うことが可能です。この汎用性の高さが Toolformer の一つの強みとなっています。
Toolformer の学習
以下では Toolformer がどのようにしてこのような能力を学習しているのかを説明していきます。
Toolformer は下の図にあるように次のステップで学習されます。
- まずはラベル付けをしたデータセットに対して言語モデルに複数の API を呼ばせます。
- これらの API 呼び出しを実行して結果を取得します。
- これらの API 呼び出しの中から、次単語予測の性能向上に寄与したものを残します。この残された API 呼び出しを含めたテキストデータを新しくテキストデータとして使用し、言語モデルを微調整します。これらを繰り返していくことで性能向上を目指します。
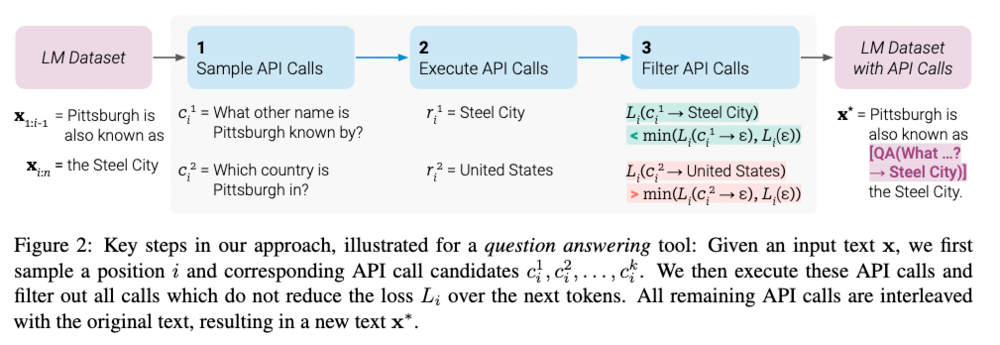
以下では、各ステップでどのようなことをしているのかもう少しだけ詳しく見ていきます。
ステップ 1. で、プロンプトを人間が用意します。プロンプトの上部に、API 呼び出しがどのように表現されているのか、モデルは何をしなければならないのかの指示を記述します。そして、直下に実際の呼び出し方の例を複数記述します。実際には、以下に示すような形でプロンプトを記述します。

各 API に対してこのようなプロンプトを用意して、モデルの文脈内学習 (in-context learning) の能力を活用して、入力文 $x$ に対する答えを出力させます。すなわち、入力文に対して 1. どこで 2. どのような API 呼び出しをするかを答えさせます。
この際、答えを一つだけ出力させるのではなく、1. 複数の API の呼び出し場所候補に対して 2. 複数の API の呼び出しを出力させます。そして、これらの出力された API 呼び出し候補を複数保存しておきます。
ステップ 2. で、これらの複数の API 呼び出しをそれぞれ実行します。実行した結果を取得して、ステップ 3. で使用します。
ステップ 3. では、呼び出しの結果を受けて、ステップ 1. で生成した API 呼び出し候補から良いものを選択します。この時の基準としては、モデルの次単語予測の性能が上がったものを残すようにします。詳細はもう少し細かいことをしていますが、そちらについては論文を参照してください。そして、これらの選択された API 呼び出しを元々のデータセットに追加します。このデータ拡張によって、少ない人間のラベル付けから多くのラベル付きデータを作ることができます。
そして、この結合されたデータセットを用いて、モデルを微調整します。これによって、適切な位置で適切な API 呼び出しができるようになります。これが Toolformer の概要です。
結果
著者たちは、API 使用の影響を評価するため、それぞれのツールが使用されることが想定されるタスクで性能を評価しました。以下に示しているのは LAMA (Petroni et al., 2019) に対する結果をベンチマークと比較したものです。GPT-J (Wang and Komatsuzaki 2021) は Toolformer のベースとなっているモデルで、GPT-J + CC はそれをやや性能向上させたものです。Toolformer (disabled) はツール使用をできなくした Toolformer の結果です。OPT (Zhang et al., 2022) や GPT-3 (Brown et al., 2020) は GPT-J よりもパラメータ数が 10 倍から 25 倍多いモデルです。
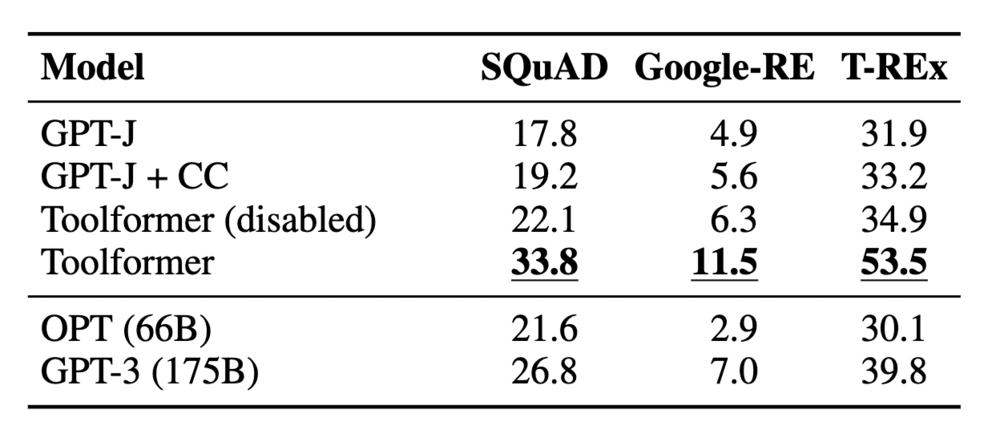
この結果からも分かるように、Toolformer が他のベースラインを上回る結果を出していることがわかります。ただし、多言語質問応答タスクでは GPT-J を常に上回る訳ではなく、質問応答タスクの複数ベンチマークでは GPT-J を上回るものの OPT や GPT-3 には及ばない結果となっています。前者については、微調整によってある言語に対しては不利な分布シフトを加速させてしまったことが考えられると述べられています。後者については、今回用いた検索エンジンが弱かったことや、検索結果と双方向的なやりとりができなかったのが問題ではないかと考察されています。
以上が Toolformer の論文の説明です。シンプルなアイデアですが、それゆえに汎用性も高く、今後のツール使用の研究を加速させるような研究となるのではないかと思います。
ART (Automatic Reasoning and Tool-use)
Toolformer は、少ないラベル付きデータで性能改善できることが強みである手法でした。しかし性能改善をするためには新しく生成したプロンプトに対してモデルを微調整する必要がありました。これに対して Paranjape らは、モデルを追加学習する必要のない手法である ART (Automatic Reasoning and Tool-use) を提案しました (Paranjape et al., 2023)。
下図には ART の概要を示しています。
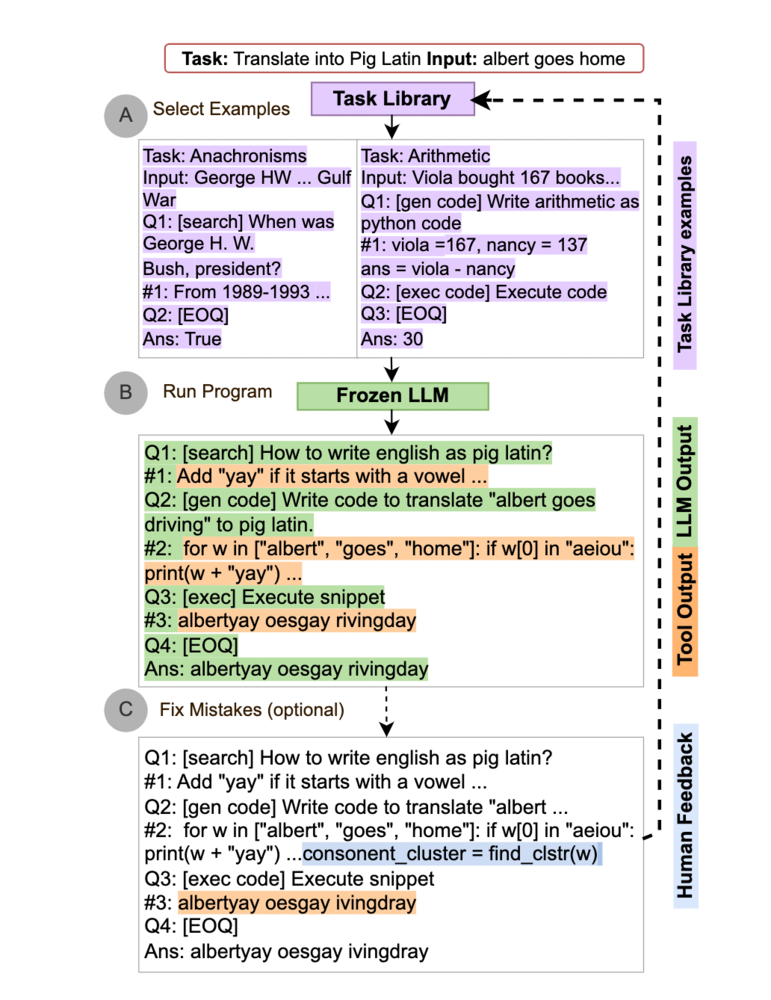
ART ではタスクライブラリというプロンプトの集合とツールライブラリというツールの集合を用意します。
タスクが与えられると、まず、A. タスクライブラリからタスクに類似したプロンプト取得してきます。そしてそれを元のタスクに例示として追加します。
B. これを入力に受けた言語モデルが答えの生成を開始します。その際、言語モデルがツールに該当するトークンを生成します。図中 [] で囲まれている部分がこれに対応します。すると、モデルは一度モデルの生成を止めて、ツールライブラリからツールを呼び出します。そして、そのツールの出力を受けて、モデルの生成を再開します。
C. このモデルの出力結果に対して、人間がフィードバックをすることもできます。この際、モデルのパラメータを変更するのではなく、タスクライブラリ内のプロンプトを修正したり、新しくツールを追加したりして、フィードバックをします。これによって、モデルの追加学習をすることなく、モデルの性能を改善することができます。
これらのイメージを示したのが下図です。
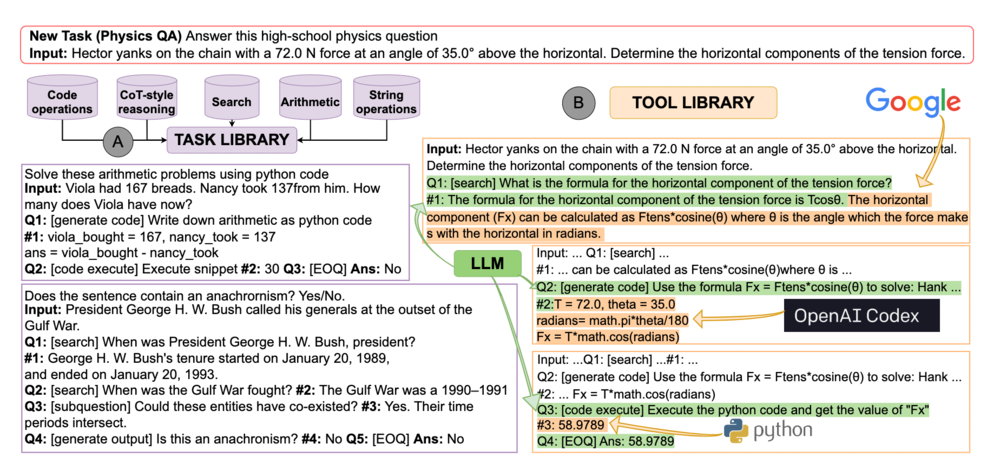
タスクライブラリは Big-Bench (Srivastava et al., 2022) のタスクを元にしています。著者たちは Big-Bench のタスクを、解くために必要なスキルに基づいて 5 つに分類しました。そして、それぞれ 2 から 4 個のタスクを選んでタスクライブラリを作成しました。
各タスクのプロンプトは、次の要素から構成されます。まずはタスクの説明です。次に "Input:" で始まる入力です。そして "Q:" で始まる中間的な指示と、それに対する "#:" から始まる回答から構成されます。これを繰り返して最終的に "Ans:" のところに答えを生成します。
このプロンプトには入力から出力までに複数の "Q:" が記入されています。これによってモデルはタスクを部分タスクに分解する方法を自動的に獲得することができます。思考連鎖 (chain-of-thought, Wei et al., 2022) に代表されるように、タスクの分解は複雑なタスクを解くためには重要です。この能力を追加学習なしで獲得できるのが本手法の強みの一つです。
今回用いたツールは、検索、コード生成、コード実行、の 3 つです。
検索は SerapAPI を用いて Google 検索を実行します。[search] の後に続くテキストをクエリとして、強調スニペットが取得できた場合にはそれを抽出し、そうでない場合は上位 2 つの検索結果のスニペットを組み合わせたものを出力とします。以下が例です。
Q1: [search] How many hairs were on Neil Armstrong’s head when he landed on the moon?
#1:
Apollo 11 (July 16–24, 1969) was the American spaceflight that first landed humans on the Moon. Commander Neil
Armstrong and lunar module pilot Buzz Aldrin.
Neil Alden Armstrong (August 5, 1930 – August 25, 2012) was an American astronaut and aeronautical engineer who became
the first person to walk on the Moon.
コード生成には CodeX を使用しています。[generate python code] の後に続くテキストを Python コードのコメントとして CodeX に入力し、生成されたコードを出力とします。たとえば、以下のようになります。
Q1: [generate python code] write down the arithmetic or algebra equations as python code, storing the answer as ’ans’
#1:
total_eggs = 16
eaten_eggs = 3
baked_eggs = 4
sold_eggs = total_eggs - eaten_eggs - baked_eggs
dollars_per_egg = 2
ans = sold_eggs * dollars_per_egg
print(ans)
コード実行は事前に用意した Python 環境でコードを実行します。例えば上の Python コードを実行する場合には次のように指示を出します。
Q2: [code execute] Execute the python code in #1 and get the value of "ans"
#2: 18
以上が著者たちが初めに用いたツールです。人間のフィードバックを踏まえてこれらに加えて新しいツールを随時追加 / 編集します。これによってモデルの能力を拡張していくことができるのが、ART の強みです。
結果
まず著者たちは、同一タスクライブラリ内のタスクに対する性能を評価しました。その結果が以下の表にまとめられています。
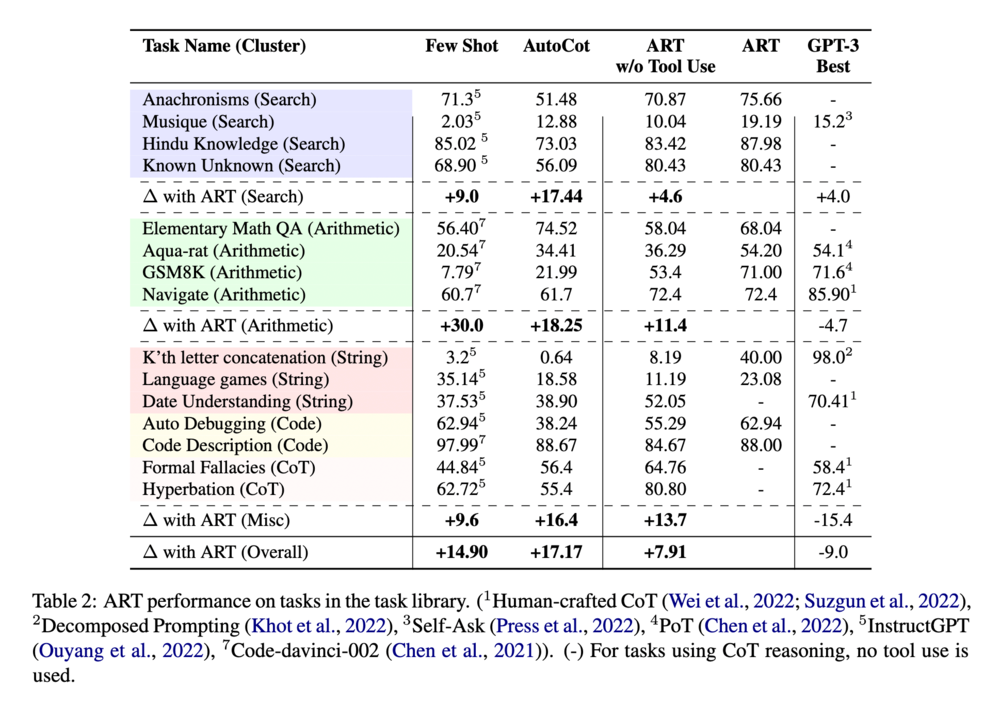
Few Shot はベースラインに対して中間出力を除いた入出力ペアのみを例示した結果です。GPT-3 と Codex をベースラインとして用いて、よかった方の結果を報告しています。AutoCot は Zhang らによって提案された Automatic Chain-of-Thought という手法を用いた結果です (Zhang et al., 2022)。GPT-3 Best は名前の通り公開されている GPT-3 の結果の最も良いスコアです。
この表から、GPT-3 の最も良い結果には劣る場合があるものの、他のベースラインに対しては全てのタスクで優れていた性能を示していることがわかります。
また、著者たちは異なるタスクへの汎化性能も評価しています。その結果が以下の表に示されています。
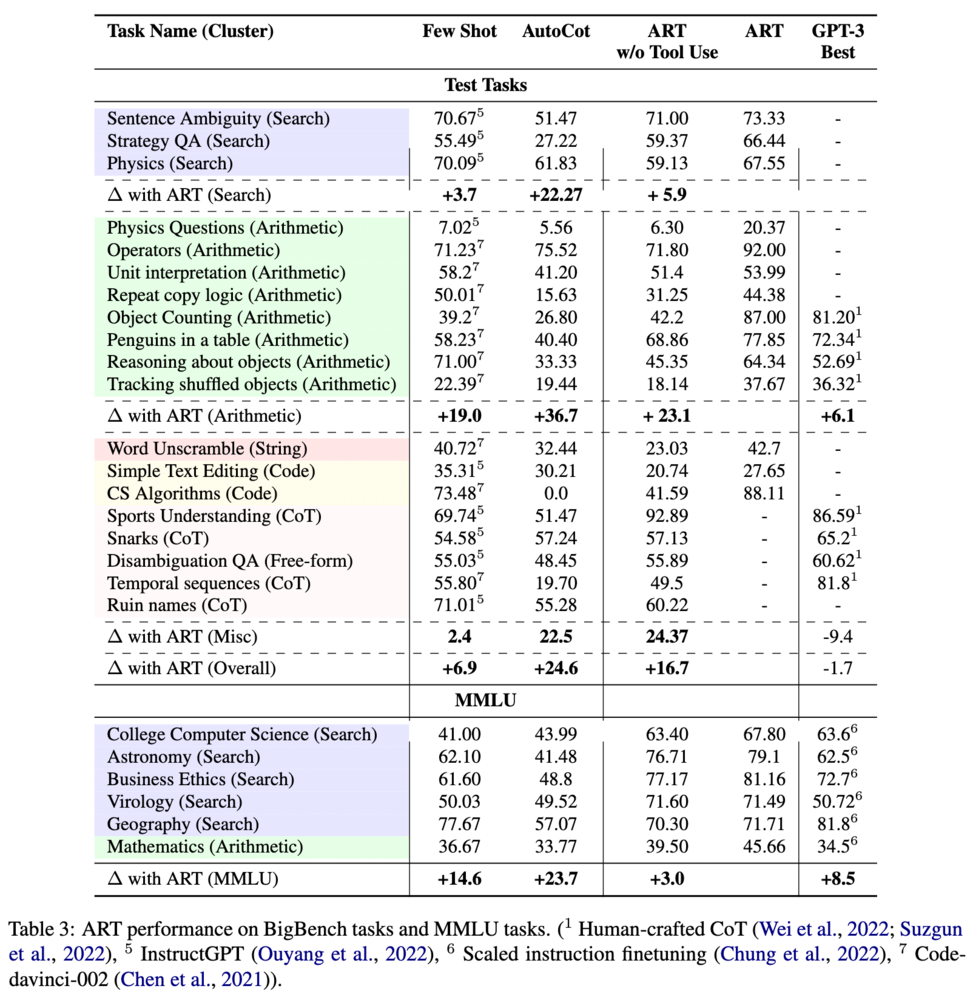
この場合でも、他のベースラインに対しては全てのタスクで優れていた性能を示していることがわかります。すなわち、他タスクへの汎化能力もあることがわかります。
最後に、著者たちは既存のツール拡張言語モデルとの比較をしました。その結果が以下の表に示されています。
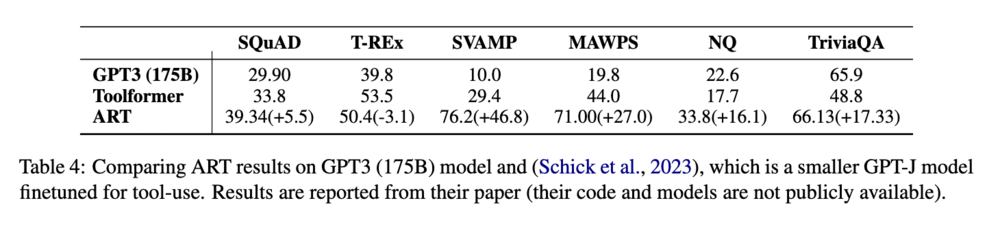
評価に用いたタスクは、Toolformer の論文で使われたものを使用しています。この結果を見ると、T-REx を除くすべてのタスクで大幅に性能を向上させていることがわかります。Toolformer が登場してからまだ 1 カ月ほどでの大幅な記録更新は、近年の研究の流れの速さを物語っています。
この他にも、すでに知られている手法と組み合わせることでさらに性能を改善できたことが報告されています。モデルを再学習することなくツール使用とタスク分解をよしなにできるこの手法は実用的にも今後注目されることが予想されます。
言語モデルによるブラウザ操作
2022 年の 9 月に、Adept という会社から、Act-1 というモデルのデモ映像が公開されました。このデモでは、言語でモデルに指示を与えてブラウザ操作ができることが示されていました。
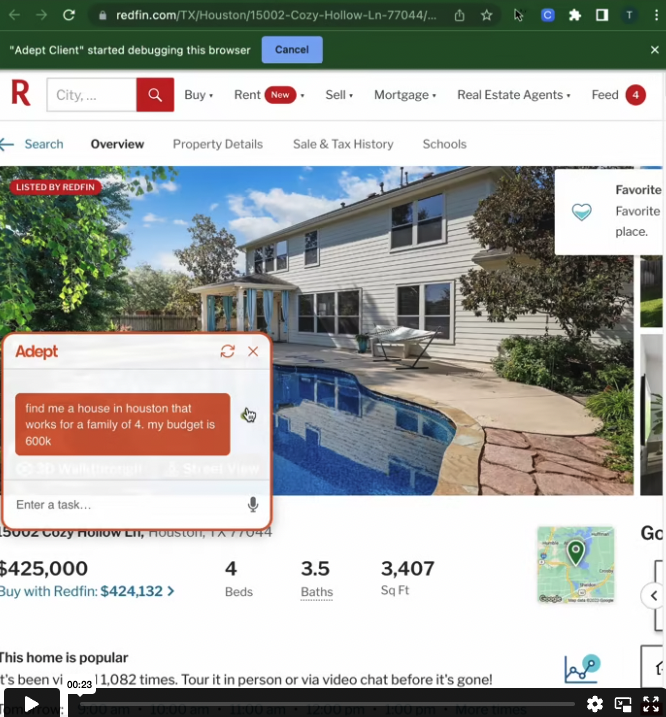
このデモ映像は衝撃で、どのように学習しているのか、そもそもデータはどのようにしているのかなど様々な憶測が飛び交いました。映像はこちらのリンクから見ることができますので、興味がある方はぜひご覧ください。
Act-1 はまだリリースされていない上、その詳細も公開されていません。しかし昨年から今年にかけて、このようなブラウザ操作を試みる手法のデモが twitter に少しずつ投稿されるようになりました。下のスクリーンショットは、このようなデモの一例です。
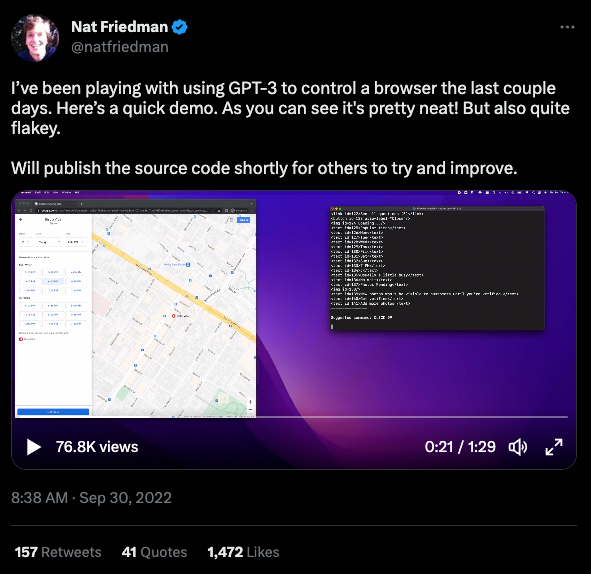
このような界隈の動向からも、言語モデルによるブラウザ操作の研究は今年大きく進むことが予想されます。そこで、以下ではこれらに関連する研究を 2 つ紹介します。
WebGPT
オープンエンドな質問に対してパラグラフぐらいの長さの返答をするという問題設定があります。これは LFQA (Long Form Question Answering) と呼ばれている問題です。既存手法ではこの問題に対して、情報検索と文書生成の両方に対して独自の手法を提案し改善を試みていました。
これに対して、Nakano らはこの情報検索の部分を Bing API に置き換えることを提案しました (Nakano et al., 2021)。そして、この Bing API を用いて言語モデルをブラウザ操作ができるように学習する手法を考えました。これが、WebGPT です。
以下の図は WebGPT が実際に操作対象とするブラウザの例です。左側がブラウザの画面で、右側がブラウザの操作に対応する文字列です。モデルはこの文字列を入力として受け取り、ブラウザの操作をします。
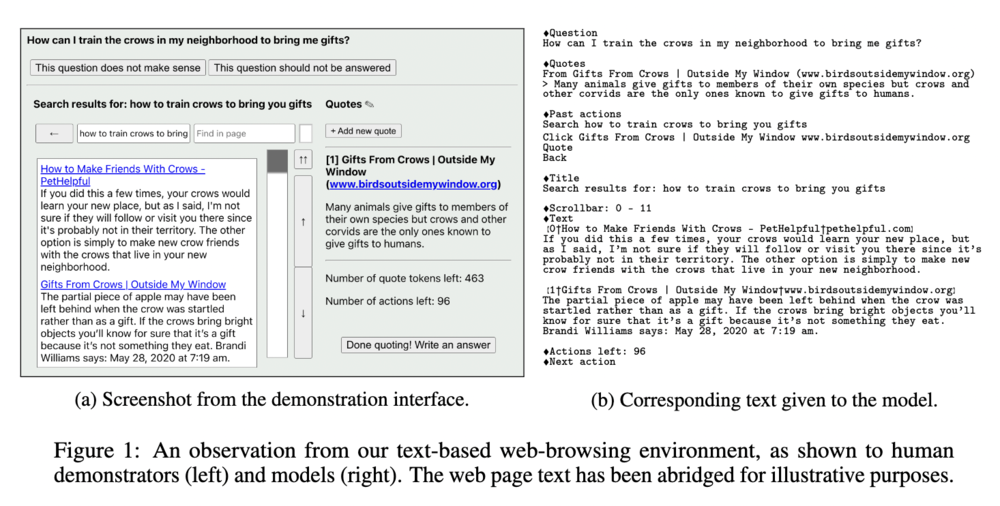
WebGPT の設定
WebGPT では、前述したテキストベースのブラウザ操作環境を用意します。そして、この環境に対する強化学習として言語モデルがブラウザ操作を学習します。
強化学習は、エージェントがある「状態」で「行動」をし、それによって得られた「報酬」をもとにより良い行動戦略 (方策) を学習する枠組みです。強化学習における「環境」とは行動を受けて次の状態/観測と報酬を返すもののことを指します。
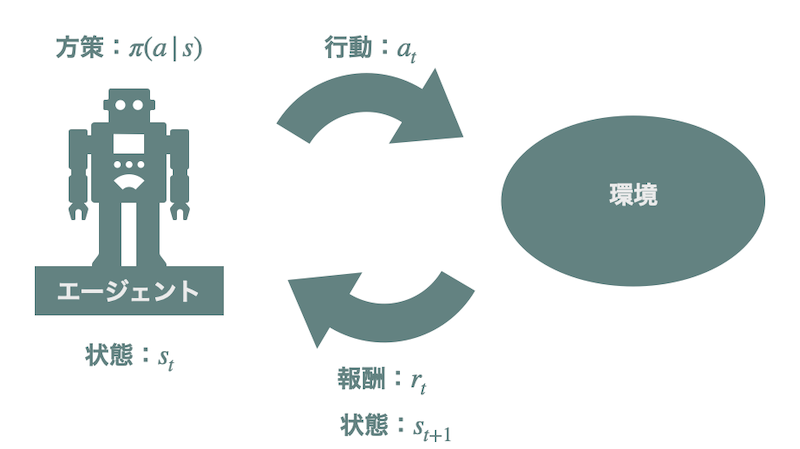
WebGPT において、観測は言語による指示やブラウザの状態などをテキストで記述したものです。行動は「リンクのクリック」などのブラウザの操作です。以下の表にモデルが取りうる行動の一覧が示されています。

今回想定しているのは質問応答タスクなので、まずは質問がモデルに与えられます。それに対してモデルがブラウザ操作の行動を取ります。モデルが行動をとると更新された観測が再び入力されます。この時、モデルが "Quote" という行動を選択すると、そこで指定されたウェブページ内の文書が保存されます。モデルはこれらの行動を繰り返して、ブラウザ操作を進めます。一連の行動を終えると、元々の質問文が保存されている文書と共にモデルに入力されます。これによってモデルはブラウザ操作の結果を加味してより適切に質問に対する回答を生成することができます。これが WebGPT の概要です。
WebGPT の学習
次に WebGPT にどのようにブラウザ操作を学習させたのかを説明します。具体的には、著者たちは次の 3 段階の学習法を試しました。
1 つめが行動クローン (Behavior Cloning) です。これは、人間のブラウザ操作の行動データを作成し、モデルがそれを模倣できたら報酬を与える教師あり学習です。
2 つめが強化学習です。これは、行動クローンしたモデル (BC モデル) を、実際のブラウザ操作環境で追加で強化学習したものです。
そのために著者たちはまず報酬モデリングをしました。報酬モデルとは人間の嗜好性を反映した報酬を出力できるようなモデルを学習する方法です。ここでは、BC モデルの最終層を取り替えてスカラーを出力するようにし、人間にとって好ましい回答に対して高い報酬を与えるように報酬モデルを学習しました。
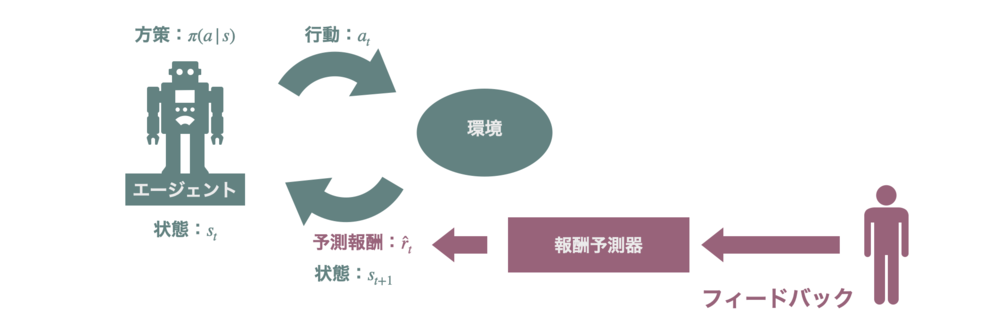
そして、この報酬モデルの出力を基に、強化学習の有名な手法である PPO で BC モデルを強化学習しています (RL モデル) 。
3 つめが、棄却サンプリングです。これは、BC モデルあるいは RL モデルに対して複数の行動の候補を出力させ、良いものを選ぶというものです。具体的には、報酬モデルの出力である予測報酬が最大となる行動を選択します。これは報酬モデルの出力を用いてモデルを追加学習している訳ではない点に注意してください。
これらの学習法のいずれかを用いて、ELI5 というデータセットを用いて学習をしました (Fan et al., 2019)。ELI5 とは、Reddit 内の「 5 歳児相手だと思って説明して」というスレッドから質問と回答のペアを抽出した質問応答データセットです。
結果
著者たちは 2 つの方法で手法の性能評価をしました。1 つ目は、ブラウザ行動データを生成した人による回答とモデルの回答を比較する方法です。2 つ目は、ELI5 内で最も多く投票を得た回答とモデルの回答を比較する方法です。これらそれぞれの方法で、人間がモデルの回答の方が好ましいと答えた割合を調べました。
その結果が以下の図です。縦軸がモデルの回答が好まれた割合で、横軸がそれぞれの評価項目です。具体的には、全体としての有用性、一貫性、事実に対する正確性の観点で評価をしています。左側がブラウザ行動データを生成した人による回答との比較で、右側が投票数の多い回答との比較です。色が濃いほどパラメータ数が多く棄却サンプルの出力候補数が多い場合となっています。
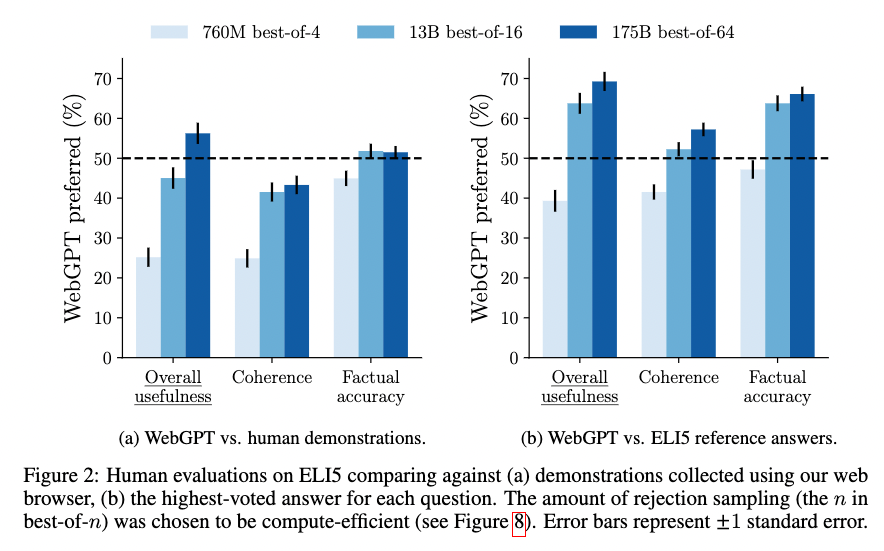
これを見ると、モデルのサイズを大きくして棄却サンプリングの候補数を増やすと、(a) の "Overall usefulness" が 56 % くらいになっています。すなわち、人間の回答よりも全体としての有用性は高く評価されていることがわかります。
投票数の多い回答との比較では、いずれの評価項目においても、提案法の出力が好ましいと評価されていることがわかります。これは既存手法からは大幅な改善であったと著者たちは報告しています。
次に著者たちは、敵対的に構成された質問応答データセットである TruthfulQA でも性能を評価しました (Lin et al., 2022)。これはモデルの出力の信頼性を評価するベンチマークデータセットです。
この結果が以下の図に示されています。縦軸が、評価指標に基づいて「信頼できる」ないし「信頼できて情報価値がある」と判断された割合です。点線が人間の結果を表しています。
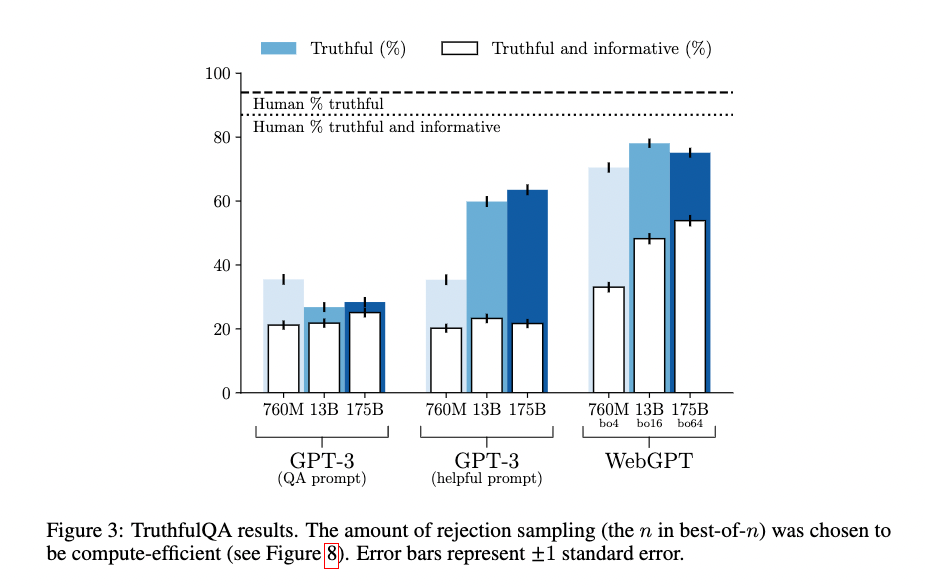
この図を見ると、WebGPT は人間の性能を下回るものの、GPT-3 の性能を大きく上回っていることがわかります。
最後に、著者たちはそれぞれの学習法同士の性能を比較しました。その結果が以下に示されています。左の図が RL モデルが BC モデルより好まれた割合です。棄却サンプリングをした場合としなかった場合を比較しています。また、右側が BC モデルに対して棄却サンプリングしたものがしなかったものに比べてどれだけ好まれているかを示しています。
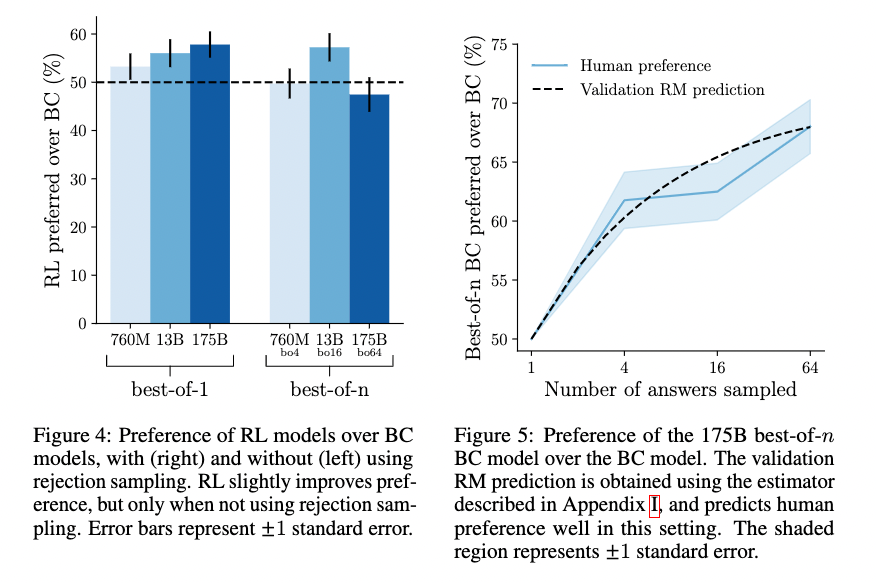
右の図から、棄却サンプリングによって BC モデルの出力が改善されていることがわかります。特に、候補数を増やすことで性能が増加していることがわかります。
左の図からは、棄却サンプルがない場合には RL モデルが BC モデルをやや改善することがわかります。しかし、右の図と比較すると、棄却サンプリングがもたらすほどの改善ではないこともわかります。さらに、棄却サンプルを用いた場合では、BC モデルの方が RL モデルよりも好まれる場合もあります。
著者たちは、単なる棄却サンプリングが強化学習を上回った理由について、環境の予測困難性やハイパーパラメータの調整などが原因ではないかと考察しています。
Webshop
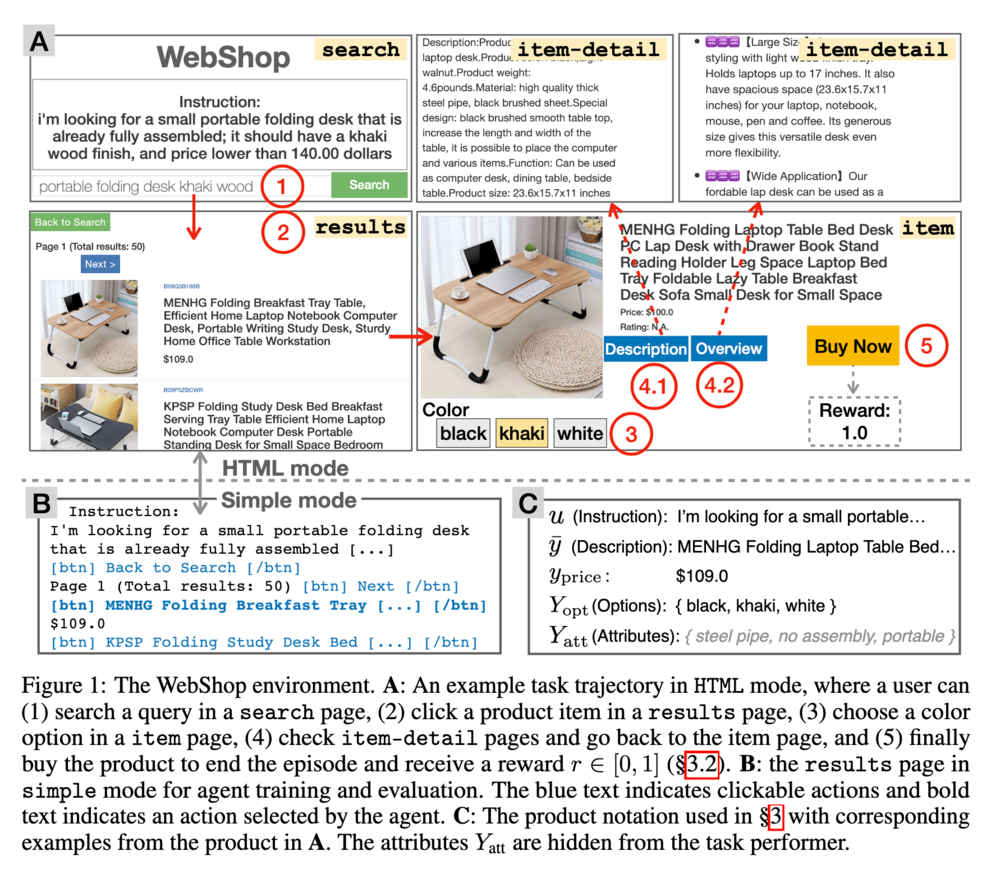
最後に、WebShop を紹介します。これは、オンラインショップのウェブサイトを模した、テキストで記述された強化学習環境です。Yao らが提案したもので、NeurIPS 2022 にも採択された研究です (Yao et al., 2022) 。
この環境には amazon.com からスクレイピングしてきた実際の 100 万もの商品の情報を用いています。エージェントはこの環境上で言語情報に従ってブラウザを操作をし、所望の商品の購入を目指します。具体的には、WebShop の環境は以下の要素から構成されています。
- 状態:現在のページの状態です。検索ページ、検索結果のページ、商品のページ、商品の詳細ページ、からなります。
- 行動:検索、クリック、からなります。
- 観測: 1. HTML または 2. HTML からメタデータを除き単純化したもの、の 2 つが用意されています。いずれもテキストデータです。HTML をブラウザで表示した画面を画像として使用することもできます。
- 言語による指示:テキストで書かれたエージェントに対する指示です。いずれの指示も、商品の属性情報、色などの選択肢、価格の情報を含みます。
- 報酬:言語の指示が含む情報を適切に拾っており、見つけた商品が求めるものと一致しているほど、高い報酬が与えられます。
以下に WebShop の例を示します。
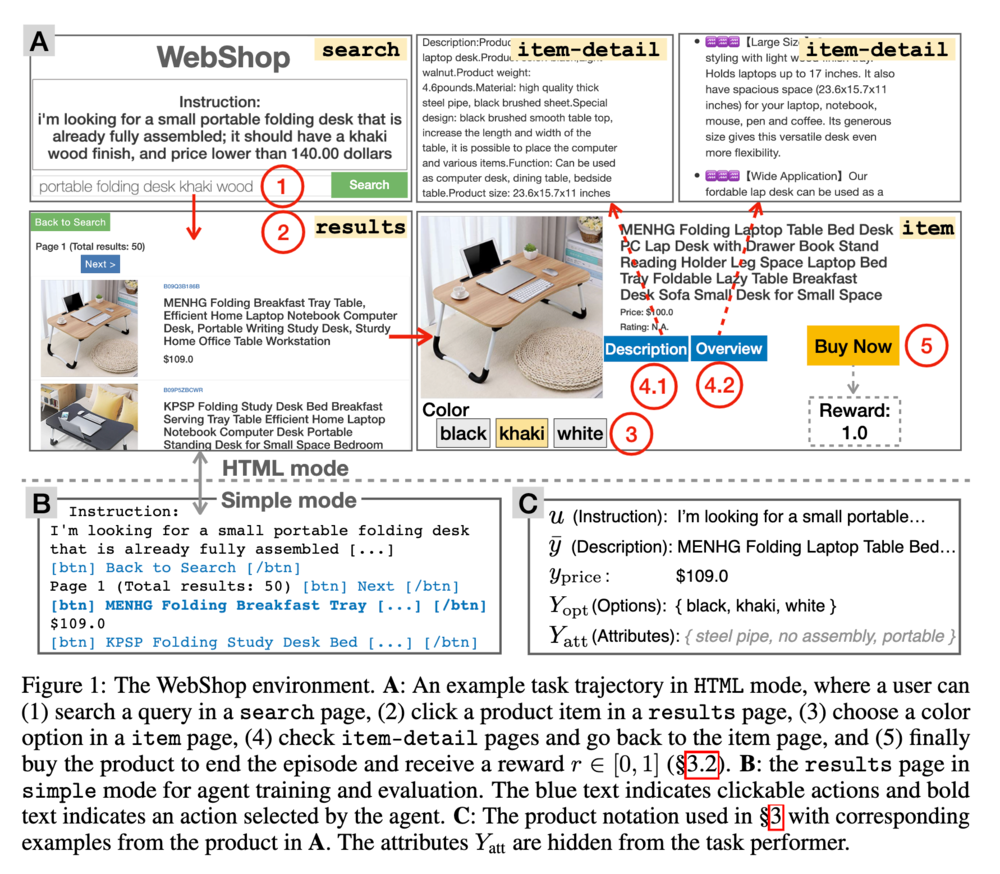
まず "Search" と書かれた検索ページ内で、テキストによる指示が与えられます。その指示を受けて検索行動をとり、"results" と書かれた検索結果のページを取得します。この検索結果のページでテキストの指示を実行するために行動を取ります。こちらの例ではまず一つ目の机の写真をクリックして "item" と書かれた商品ページに遷移します。商品の詳細ページや概要ページに飛ぶボタンをクリックすると、右上のように "item-detail" と書かれた詳細ページに移動します。商品の色などの選択肢は左下のボタンを押すことで選択できて、最終的に商品購入行動を取るとその結果に応じて報酬が与えられます。
これは人間のようなブラウザ行動を要請するため難しいタスクとなっています。具体的には以下のような点が困難であると著者たちは述べています。
- 検索クエリを練り直してより良いクエリを生成する必要がある
- 戦略的な探索行動を取らなければならない
- 的確な言語理解が必要
- 商品比較などのために長期記憶が必要とされる
実験設定
この環境を試すため、著者らは複数のベースライン手法を作成し、それらの性能を評価しました。
1 つ目がルールベースラインです。これは指示をそのまま検索にかけて最初に出てきた商品を購入するというごく単純なものです。
2 つ目が模倣学習によるベースラインです。この手法では、事前学習済みの言語モデルを 2 つ用意し、それぞれ人間の検索行動と選択行動を模倣するように学習します。検索クエリの生成には BART を微調整しています。選択行動の模倣学習には、以下に示しているアーキテクチャを使用しています。
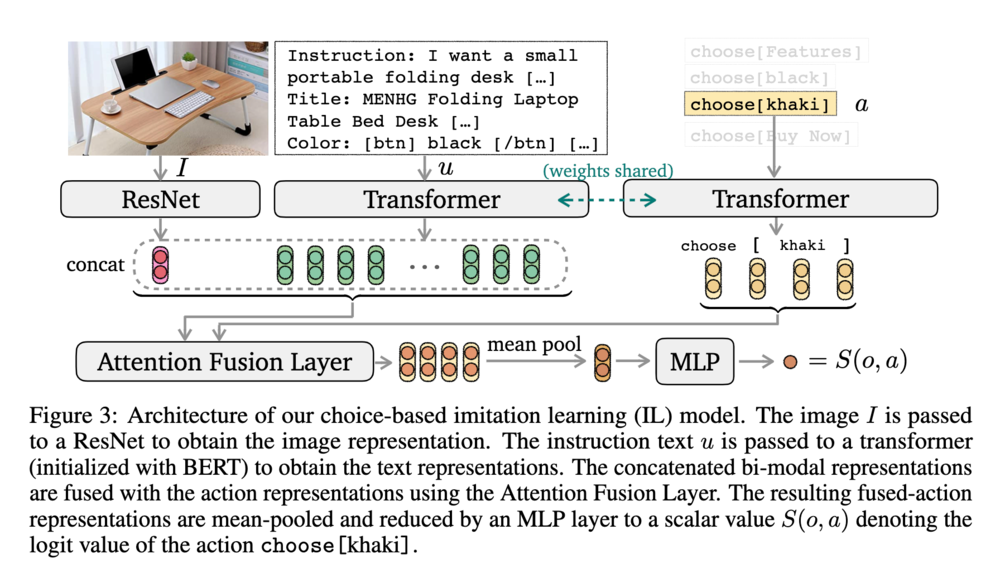
選択行動の模倣ではこのモデルが出力したスコアに対するソフトマックス分布を方策として行動を生成します。検索ページでは、BART モデルが生成した複数のクエリ候補から、ランダムに 1 つ選択します。その他のページでは、選択行動モデルが出力した行動を実行します。
3 つ目が強化学習によるベースラインです。この方法では、模倣学習したモデルをさらに強化学習によって追加学習します。ただし BART モデルは固定して、選択行動モデルのみを強化学習で学習します。
結果
以下に各手法の評価結果を示しています。IL が模倣学習、w/o はそれぞれの手法を除いた場合です。RL は模倣学習をせずに強化学習のみをしたもので、RL (RNN) はトランスフォーマーの代わりに RNN を用いたものです。棒グラフはそれぞれ最終的なスコアと指示の達成率を示しています。また、点線は人間の結果を表しています。
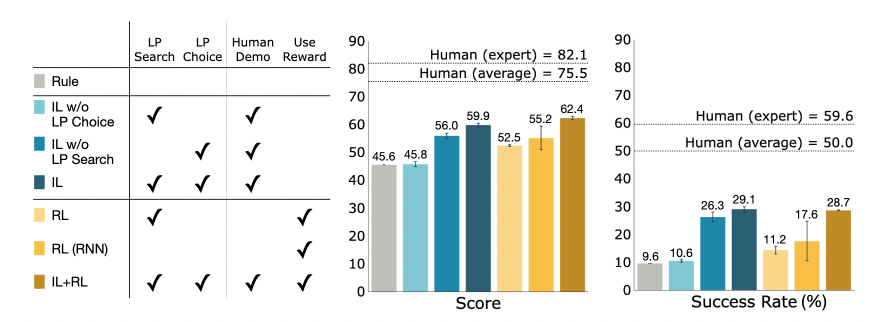
この結果を見ると、いずれの手法もまだ人間の性能に及んでいないことがわかります。つまり、ブラウザ操作というタスクはまだ難しいタスクであることが示唆されています。また、選択手法の模倣学習が重要そうであること、強化学習はそこまで性能を大きく改善していないことなどがわかります。
著者たちはエージェントが人間と比べてどこでつまづいているのかを追加で分析しています。次の表は、「属性情報」、「選択肢」、「タイプ」、「値段」のそれぞれの項目についてのスコアを調べているものです。
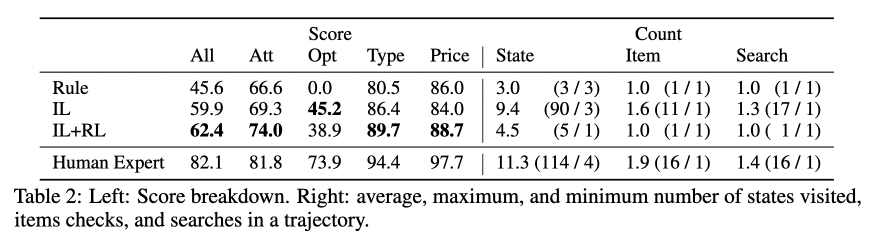
この結果を見ると、人間はエージェントよりもはるかに良く「選択肢」を選べていることがわかります。つまり、この項目がスコアの差につながっていることがわかります。
さらに著者たちは、結果に対する定性評価もしています。次の例は、人間とエージェントの行動の軌跡の 1 例を比較したものです。

例えば左側の例では、人間は一度目の "search" をした後に、その結果を受けて別の "search" をしています。一方で、エージェントは一度しか "search" をしていないことがわかります。このことから、検索結果を受けて検索クエリを再検討する能力がまだエージェントには欠けていそうであることが伺えます。
また、右側の例でも左側の例でも、人間は複数の商品を比較しています。しかし、エージェントは 1 つの商品を見つけたら購入に進んでいることがわかります。これはエージェントはまだ人間のように商品の比較検討ができていない可能性を示唆しています。
このように、人間のようなブラウザ行動をするにはまだまだ課題はあります。その意味でも、このような強化学習環境を提供するような研究は非常に重要であると思います。
おわりに
この記事では、ツール拡張された言語モデルの研究を紹介しました。論文として公開されているものはまだ少なく、ここで挙げた研究はそれらのうちの代表的なもののいくつかです。しかし、冒頭で申し上げたようにツール使用の研究は現在大きな注目が集まっている研究の一つです。今回はご紹介できませんでしたが、すでにツール使用に関連するサーベイ論文も出てきています (Mialon et al., 2023)。今年中にほぼ確実に大きな結果が出てくる分野だと思いますので、ぜひみなさんも注目していただければと思います。
関連記事
 萩原 正人
萩原 正人 藤井 亮宏
藤井 亮宏