高性能なコードをコメント等から生成・補完してくれる GitHub Copilot。2週間ほど前にリリースされてから、ネット上にて何かと話題になりました。今週、GitHub Copilot を支える大規模言語モデルである 「Codex」の技術詳細に関する論文が OpenAI から発表されましたので、速報的に解説してみたいと思います。なお、この論文で記述されている Codex のプロダクション版が、GitHub Copilot の裏側で動いているとのことです。
元論文: Chen et al., 2021. Evaluating Large Language Models Trained on Code
ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
言語モデルでコードを生成する
昨年発表されて話題になった超巨大言語モデル GPT-3。コードの生成に特化していないのにも関わらず、Python の docstring (コメント) など、自然言語から簡単なプログラムを生成できることが知られています。そこで、コメントからコードを生成することに特化した言語モデルを訓練することにより、より高度・正確なコードを生成することができると思われます。
本論文では、Python の docstring (アルゴリズム仕様を自然言語によって記述したコメント) から、独立した関数の中身のコードを生成するタスクを言語モデルを使って解いています。
コード生成をどう評価するか
自然言語生成においては、何らかのヒューリスティックに基づく指標や、人間の主観によって評価されます。一方、コードの評価では、例えば翻訳の評価などで用いられている BLEU などの指標ではうまく評価できないことが知られています。

そこで、本論文では、生成されたコードの「機能的正しさ」を使って生成されたコードの質を評価します。具体的には、164個のプログラミング問題を独自に作成し、その問題のユニットテストに通るかどうかで評価をします。GitHub には既にプログラミング問題の答えが多くアップロードされているため、「独自に」作成したという点が重要になります。ここで作成されたデータセットを HumanEval と呼んでおり、そのうち3個の問題サンプルを上の Figure 2 に示してあります。また、このデータセットは公開されています。
評価は、このデータセットを使い、$k$ 個の解を生成した時に、そのうち一つでも問題を正しく解くことができた場合を「正解」としています。$k$ 個のサンプル数を生成したときの正解できた問題の割合 pass@k を計算するのですが、これは出たサンプルの質に大きく影響され、分散が大きくなるので、それよりも多くのサンプルを生成し、pass@k の平均を計算する統計量を実際の評価に使っています。
実験結果
Codex の訓練には、5400万 ものGitHub のパブリックなリポジトリから収集した計 159 GB の Python ファイル群を使っています。収集されたファイルには、自動生成、文字種、行長などで簡単なフィルタリングを施しています。
実験では、GPT-3 (自然言語で訓練された言語モデル) から微調整 (fine-tune) する場合と、Codex をゼロから訓練する場合を比較しています。興味深いのは、既存の言語モデルを微調整しても、ゼロから学習した場合に比べて性能が良くならなかったということで、これは今回の 159 GB のデータセットが非常に大きいから、としています。一方、微調整することによって訓練がより高速に収束するので、今回はこの方法を使っています。
GPT-3 のテキスト表現を最大限活用するために、GPT-3 と同じトークナイザーを使ってコードをトークン化します。一点、これだと空白文字が全て分割されてしまい非効率的なので、空白文字の連続を独自のトークンとして新たに追加しています。
実験の結果、12B (120億) のパラメーターを持つ Codex モデルでは、単一のサンプルで 28.8% の問題を正しく解くことができました。また、300M (3億) のパラメーターの Codex モデルでは、11.4% の正解率でした。
一方、コード生成に特化していない GPT モデルでは、正解率はほぼゼロだったということで、ここからも、言語モデルをコード生成に特化させることの効果がうかがえます。
なお、最近紹介した「GPT-3 のオープンソース版」である GPT-J のトップ1正解率は 11.6%、GPT-Neo は 6.4% だったといういうことです。これらの「オープンソース版」の訓練には、GitHub のクロールデータが入った The Pile が使われているため、GPT-3 より高くなるのは納得がいきますが、コード生成に特化した Codex に比べると、同じ正解率を達成するためのモデルのサイズはどうしても大きくなってしまいます。
また、サンプルを生成する際の温度パラメーター $T$ の調整が重要です。温度パラメーターは、生成するトークンの多様性 (ばらつき度合い) を上げるもので、望むサンプル数に応じて適切に調整する必要があります。実験の結果、サンプルを数多く生成する場合ほど、温度パラメーターを高くした方が正解率が向上した、ということで、これは、温度パラメーターを上げることによってより多様な解が生成でき、それが正解率を上げることに寄与している、としています。
なお、実際にコード生成・補完に使う場合には、このように大量の解を生成して評価することは現実的ではありません。その場合、大量の解を生成し、「トークンあたりの平均対数確率」を使って解をリランキングすることによって、正解率をさらに高めることができるということです。
教師あり微調整
ここまでは、言語モデルを、次のトークンを予測する因果言語モデル損失によって、コードのデータで微調整したというだけです。ここで、よりタスクの設定に近い、「問題の docstring+関数の中身」の正解データを使って微調整をしたら、より強力なモデルができるのでは、と予測ができます。
そこで本論文では、このタスクに使える、問題の仕様(コメント)、関数、期待される出力、を追加で収集しています。一つのソースは、競技的プログラミングの問題。競技的プログラミングやコーディング面接準備のウェブアドレスから、10,000個の問題を集めたということです。もう一つのソースは、CI (継続的インテグレーション) のユニットテスト。travis や tox を使って CI が設定してある GitHub のリポジトリや PyPI の公開コードから、40,000 個ほどの関数の出力・入力を集めたということです。
こうして集めた「問題」の中には、難しすぎたり、訓練に適さないものが含まれている可能性があります。そこで、上で訓練した Codex-12B を使い、それぞれの問題に対して 100個の解を生成し、そのうちひとつも正解できなければ、データとして使わない、という処理をしています。
このデータセットにより Codex を微調整した 「Codex-S」では、Codex に比べて平均で正解率が 6.5 ポイントも向上し、最も大きい Codex-S では、一回の試行で 37.7% の問題を解くことができたということです。
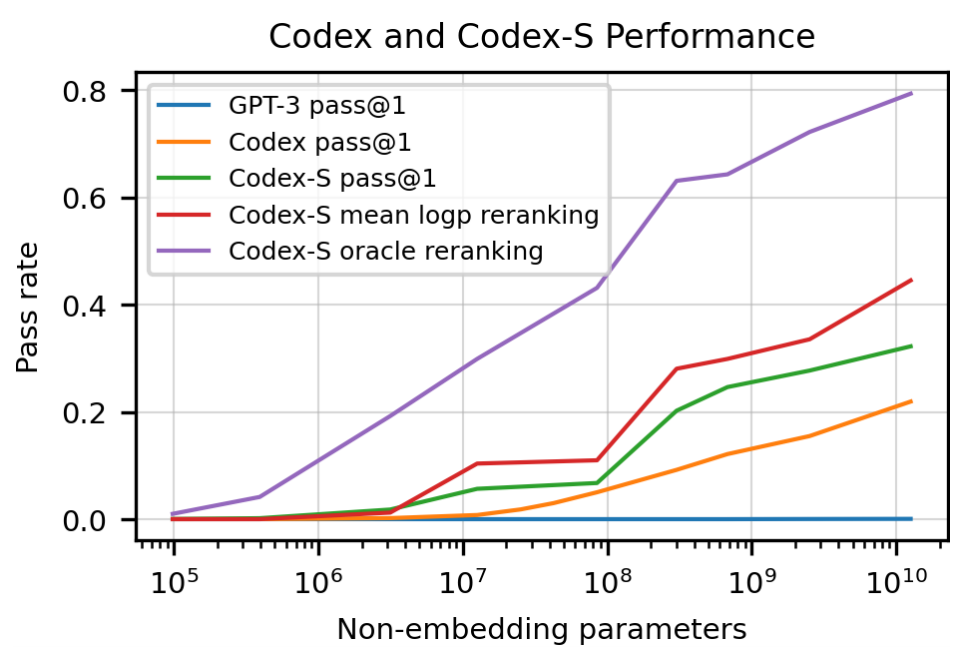
これまでの結果をまとめ、モデルの規模 (埋め込みレイヤーを除くパラメータ数) を横軸、正解率を縦軸としたのが上の図 (論文中の Figure 1 から引用) です。紫色の線は、オラクルを表しており、正解がトップ 100 に含まれる確率が 77.5% であることを示しています。ここから、「正解を一つでも生成できる確率」は比較的高いため、出された解の候補をいかにリランキングするかが重要になってきます。上で述べたように、トークンあたりの平均対数確率によってリランキングした場合、Codex-S の正解率は 44.5% にまで高めることができるということです。
docstring の生成
同じような仕組みを使い、ここまでに述べたのとは逆に、「コードからコメント (docstring) を生成」することも可能であると考えられます。そこで、「関数のシグネチャ → 参照解 → docstring」の順でデータを連結し、関数本体から docstring を生成するモデル Codex-D を作成しました。
コメントが正しいか、を自動で判定するのは非常に難しいので、ここでは、少数を人手で評価しています。その結果、コメントの「正解率」は、同サイズの Codex-S のコードの正解率とほぼ同じだったということです。
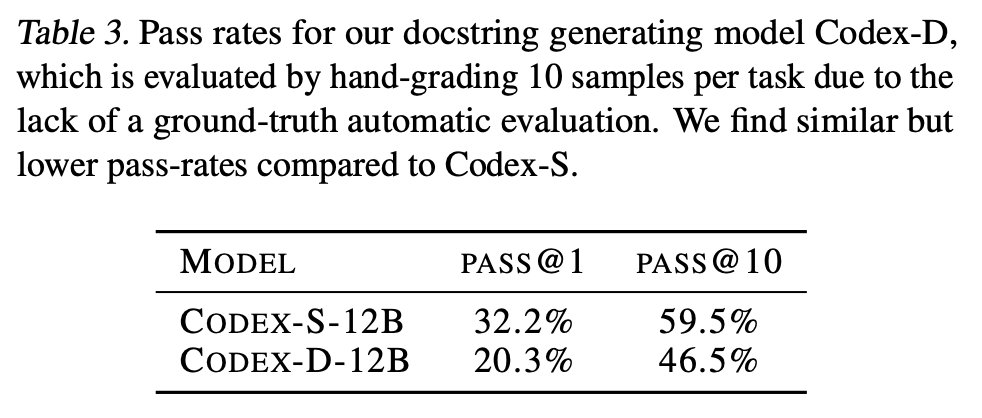
コメントの生成において「不正解」になるのは、例えば「答えの有効数字は小数点以下2桁とする」などの重要な詳細が抜け落ちている場合が最も多かったということです。また、この「コード→コメント」生成は上で見た「コメント→コード」の逆モデルなので、これを「逆翻訳」として使い、Codex-S の生成したコードをスコアによってリランキングすることもできます。ただ、この方法よりも、上で見た対数確率によるリランキングの方が良かったということです。
限界と影響・リスク
最後に、論文では、この Codex モデルの限界や影響、リスクについて、非常に詳細な議論がなされています。
まず、一点、明らかな問題として挙げられるのは、このモデルの非効率性です。人間のプログラマは、ベテランであっても今回訓練に使われたデータよりもはるかに少ないコードしか見たことがないはずですが、評価に使った HumanEval データセットは、優秀な学生であればほとんど解けてしまうでしょう。
また、長かったり、ハイレベル・システムレベルの記述を含むようなコメントに対する生成の質は難しいということです。例えば、「文字列を小文字に変換し」「3文字おきに文字を削除する」ような、いくつかの仕様の系列になっているような問題は、その系列の長さが長くなればなるほど正解率が低下する (5個以上になると、ほぼ解けない) ということが分かりました。一方、人間であれば、2個以上に一般化することは難しくなく、これも言語モデルの一つの限界と言っても良いでしょう。
また、Codex のようなコード生成モデルの影響とリスクについて、以下の点を挙げています。
- 過度な依存。生成された出力を過信してしまうこと。初心者が一見正しそうに見えるコードをそのまま信じて使ってしまう危険性。
- アラインメント失敗。モデルが本来できることに失敗すること。例として、プロンプトに(一見わかりにくい)バグが含まれているとき、質の低いコードが生成されてしまう。
- バイアス。人種・誹謗中傷など問題のあるコメントを生成してしまう。
- 経済・労働市場への影響。プログラマの負担をどの程度軽減できるのか。また、生成する import 文に偏りがあるため、特定のパッケージのみが使われる傾向を助長してしまうリスク。
- セキュリティ。脆弱・低品質なコードを生成してしまう可能性。訓練データを「丸暗記」してしまう可能性はあるが、訓練データは全て既にパブリックであるので、もし機密性の問題があったらそのデータは既に「漏出」している。
- 環境。GPT-3 や Codex の訓練には大量のエネルギーを必要とする。
- 法的問題。インターネット上のデータを使って AI システムを訓練するのは「フェアユース」という理解。訓練データをそのまま丸暗記して出力することはほとんど無い。既にエディタなどに実装されているサジェスト機能や補完機能と同じ位置づけ。
この中でも特に著作権やセキュリティの問題に関しては、Copilot のローンチ後も、インターネットにて活発な議論がありました。主に指摘された問題点としては、
などがあり、現段階でも、著作権やライセンスの侵害に当たらないのかという議論が活発にされています。
ここに書いた問題の多くは、コードに限らず、言語モデルを使った自然言語生成にも当てはまる問題です。これを気に、言語モデルの安全・効率的な学習と推論や、AI モデルに対する法的・知的財産的な議論がさらに進むことになるでしょう。
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人