ステート・オブ・AI ガイドでは、人工知能・機械学習分野の最新動向についての記事を毎週配信しています。購読などの詳細につきましては、こちらをご覧ください。また、Twitter アカウントの方でも情報を発信しています。
自然言語処理において避けては通れない前処理である「分かち書き」を全くすることなしに、高品質な事前学習言語モデルを訓練する CANINE (ケイナイン; Character Architecture with No tokenization In Neural Encoders) という手法に関する論文が発表されました。通常、このように最新の論文ばかりを追うことはあまりしないのですが、
「これからの日本語処理のやり方を根本的に変えてしまうかもしれない」
とあまりに衝撃を受けたので、論文速報として解説したいと思います。
分かち書きがなぜ問題なのか
近年の自然言語処理においては、巨大なニューラルモデルでタスクを一貫して (end-to-end で) 解いてしまうということが一般的になりました。
一方で、ほとんど全てのモデルにおいて、入力テキストをトークン単位に分割する「分かち書き」の処理が必要となります。近年では、教師なしでテキストを統計的に分割する BPE (Byte-Pair Encoding) や SentencePiece のような手法も発達し、頑健かつニューラルネットワークに適した分かち書き処理ができるようになりました(このあたりは、WordPieceからBPE-dropoutまで 〜 ニューラル時代のサブワード分割・トークン化手法 完全ガイド という記事でも詳しく解説しました。)
しかし、単に文字列を分割するだけではうまく処理できない言語の現象は多数存在します。例えば、アラビア語・ヘブライ語など、単語に接辞をくっつけるのではなく、単語の「中身」が変化するような形態論を持つ言語ではうまく分割することができません。
また、これは私の補足ですが、日本語も形態素解析をして形態素単位にトークン化をすることがもはや当たり前になっていますが、たとえば「市町村長」をどう分割するか(市町村の長ではなく、市長・町長・村長をまとめた語)など、単なる分割ではうまく扱えない現象も存在します。
さらに、タイポや表記ゆれ、翻字など、イレギュラーな言語現象が入力されると、性能がとたんに低下するという問題も指摘されています。
また、事前学習の際に使った分かち書きの単位と、下流タスクの分かち書きの単位が一致するとは限らないという問題があります。これは、日本語処理でもよく出くわす問題で、固有表現抽出など、トークン単位でスパンを予測するタスクなどで顕著なのですが、タグ付けされた範囲が、分かち書きの境界と一致しているという保証はありません。
この場合、一番近いトークンの境界に無理やり合わせるか、例えば MeCab などを使って言語学的に正確な分かち書きをすれば良いと思われるかもしれません。しかし、前者は、例えば BPE や SentencePiece が言語学的に正しい分かち書きを出力できる保証はなく(特に BPE は、それとは程遠いということが知られています)、後者については、事前学習の時の分かち書きと違う場合そもそも適用できない、という問題もあります。
一方、文字ごとにトークン化し、入力を文字の系列とする方法もあります。しかし、現在、自然言語処理のアーキテクチャとしてデフォルトで使われているトランスフォーマー(自己注意機構)では、処理時間が入力系列長の2乗に比例してしまうという問題点があります。また、実際のタスク精度もあまり高くないことが知られています。
CANINE の仕組み
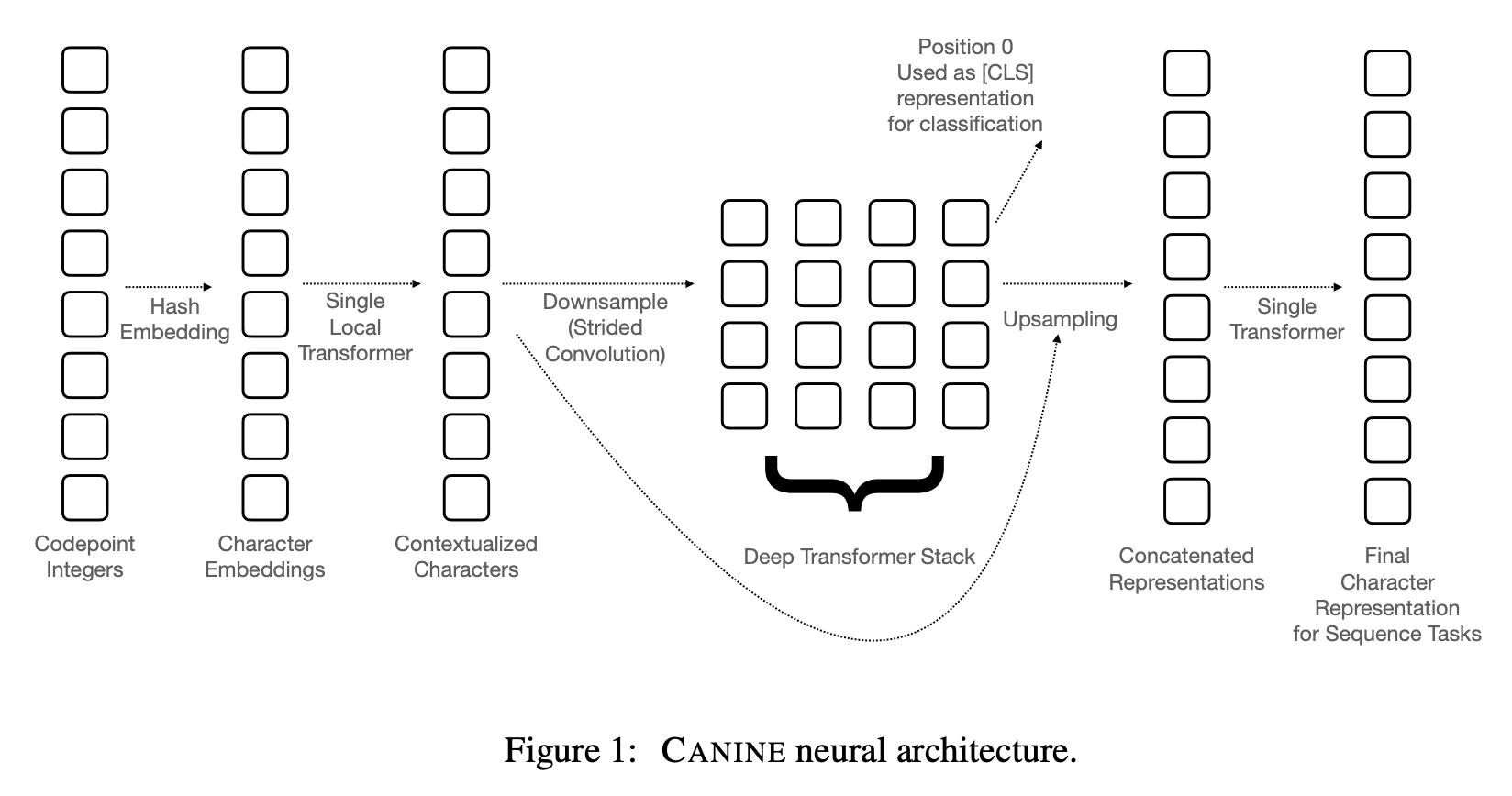
CANINE の本体は、BERT などと同様、トランスフォーマーのアーキテクチャを利用した事前学習言語モデルです。計算量や精度を犠牲にすることなく、分かち書きのしていない入力文字系列を効率良く処理するための仕組みが詰まっています。
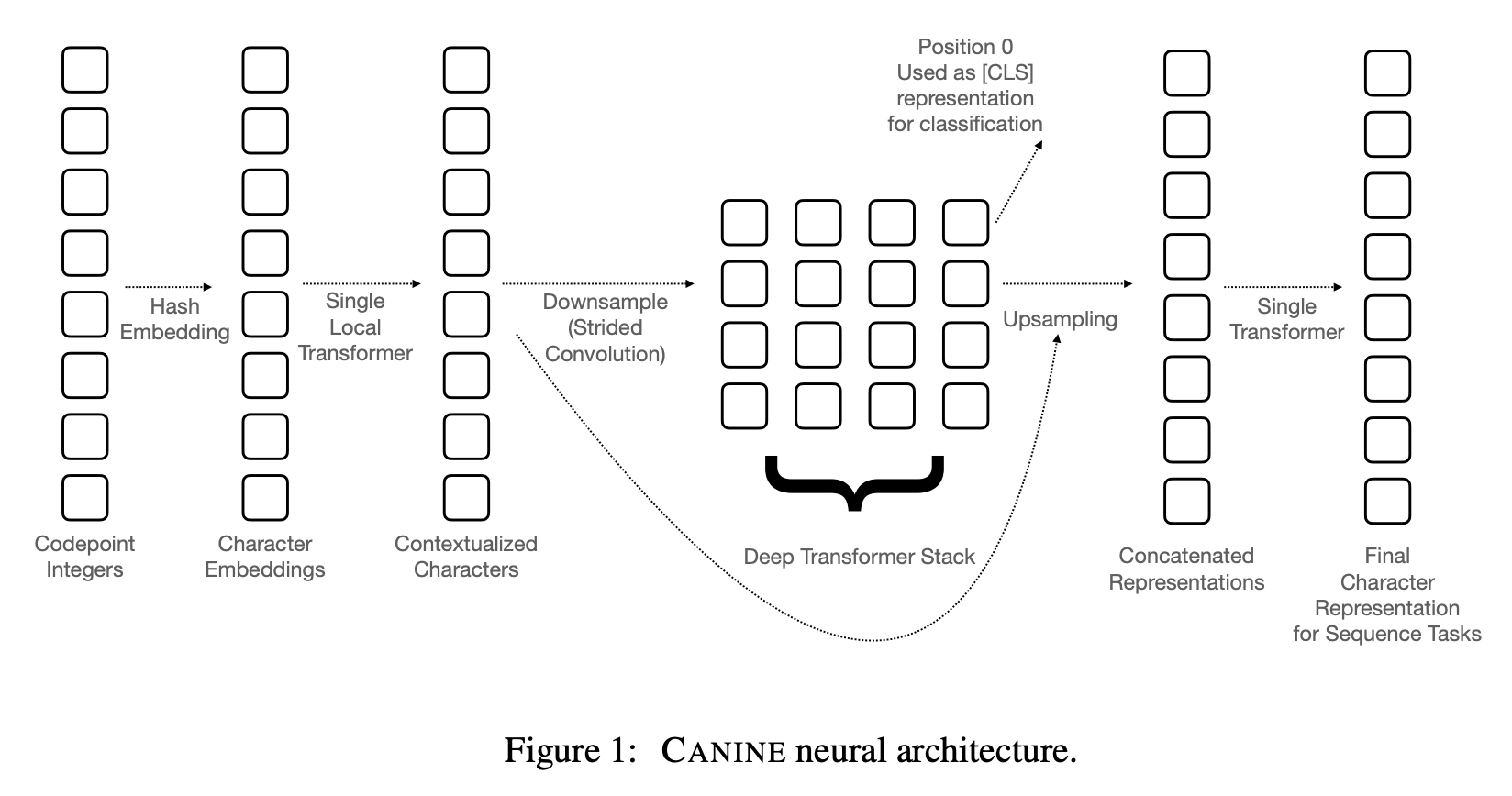
入力は、単なるユニコード文字の系列です。各文字はコードポイントの整数値に変換され、次の処理に渡されます。コードポイントはユニコードの規格で決まっているので、トークナイザーなどと違い、将来的な互換性を心配する必要がありません。
ユニコードの文字の集合は数十万と膨大なものになるので、ここでは特徴量ハッシングに似たテクニックを使っています。具体的には、最初の処理で、まず入力に対してハッシュ関数+剰余演算をかけ、$B = 16,000$ 個の値に圧縮してから、それぞれの埋め込みを行列によって求めます。これを $K$ 回、異なるハッシュ関数と行列に対して繰り返し、結果のベクトルを連結したものを「文字埋め込み」とします。
その次の層は、1層だけからなるトランスフォーマーです。系列全てに対して注意の重みを計算するのは計算量が大きいので、$w = 128$ 文字の局所的な範囲のみ注意機構を計算します。
次に、ストライド $r = 4$ の畳み込みレイヤーを適用し、ダウンサンプルします。CANINE の入力は最大 2,048 文字なのですが、この畳込み処理によって系列が短く、最大 $m = 512$ となり、通常の BERT などと同じサイズになります。
エンコーダーのメインの部分は、通常の言語モデルと同様、$L$ 層からなる深層トランスフォーマーです。ここで、制限なしの注意機構によって、文脈化された表現が計算されます。このトランスフォーマーの最初のトークンの表現を取り出すと、これがいわゆる CLS トークンの潜在表現に相当し、それを使って文分類問題などを解くことができます。
しかし、上記の系列ラベリング問題などに対しては、入力の単位(文字)に 1:1 対応した潜在表現が必要になります。そこで、入力とは逆に、畳み込みレイヤーを使ってアップサンプリングし、入力と同じ系列長に戻します。その後、再度1層だけからなるトランスフォーマーを適用し、トークン(文字)ごとの表現が求まります。
CANINE の訓練
CANINE の訓練(事前学習)は、他のメジャーな言語モデルと同様、マスク言語モデル (MLM; Masked Language Model) と後続文予測 (NSP; Next Sentence Prediction) の組み合わせが使われます。
一点、トークンが「文字」の単位なので、トークン単位でマスキングをしても、(おそらくタスクが簡単すぎるので)事前学習がうまくいきません。そこで、入力テキストをトークン化し、サブワードの単位で入力をマスキングし、その中からランダムに選ばれた文字をソフトマックスによって当てる、というタスクに変更しています。ここで「トークナイザーを使っているのでは?」と思われるかもしれませんが、これは事前学習の損失関数として一時的に使われるもので、事前学習が終わった後は全く使われないばかりか、下流のタスクはそのトークン化のことを知る必要も全くありません。
実験
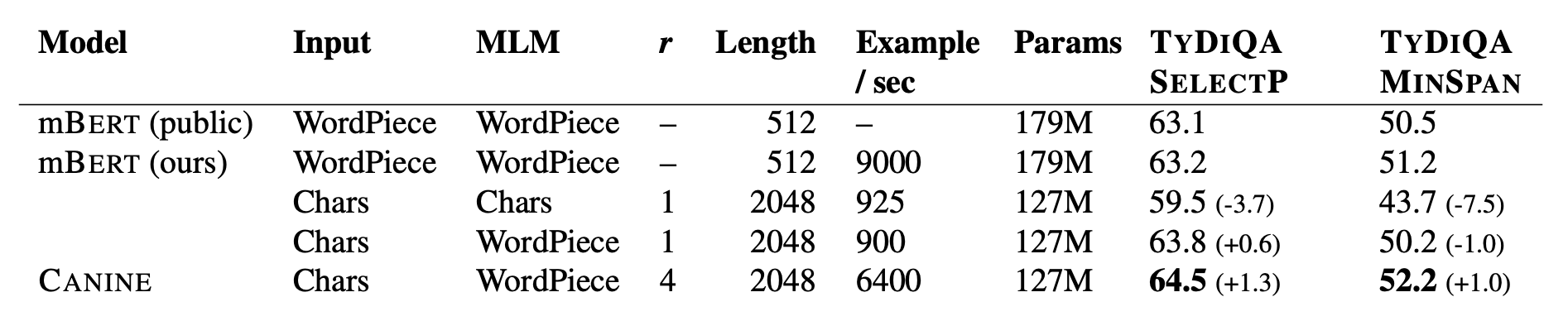
実験では、言語類型論的に多様な言語から成る質問応答データセットである TyDi QA (Clark et al. 2020) をタスクとして使っています。訓練データとサイズを同等にしたマルチリンガル版 BERT (mBERT) と比較して、CANINE がより少ないパラメータでより高い性能を達成していることが分かります。また、文字をトークンとしてそのまま使い、事前学習したバージョン (表の3行目) と、文字をトークンとして使い、WordPiece を使い事前学習したバージョン (表の4行目) とも比較していますが、CANINE で提案されている「ダウンサンプル+WordPiece でマスクして事前学習」ほど効果的ではないことが分かります。
また、補足実験では、CANINE のモデルの設計、例えば、ハッシュ関数の適用、局所的なトランスフォーマーの適用、ダウンサンプルの量など、それぞれがどの程度性能に寄与しているかを分析しています。
mBERT に比べ、CANINE がうまく解けた例の分析も示されています。それによると、スワヒリ語の例で、異なる語形変化により、質問中の語と文書中の語の分かち書きが変わってしまっている例があったということです。このように言語学的に一貫性の無い分かち書きによって、モデルがそれを補完しなければならず、モデルに対して必要以上に強い負担になっている、という問題を指摘しています。
おわりに
この論文で使われているデータセットには日本語も含まれているのですが、この論文のみからは残念ながら日本語に対してどのような結果が得られたかは分かりませんでした。しかし、日本語処理の大きなボトルネックである分かち書きをせずに高品質な表現が事前学習できることから、日本語処理に一定の影響を与えることは必至だと思います。もしかして1〜2年のうちに「日本語は文字ベースで処理」が当たり前になってしまうかもしれません(かれこれもう十数年ほど自然言語処理に関わっている身としては少し残念な気もしますが)。
一点、この論文では TyDi QA での評価結果しか書かれておらず、他のタスクやより幅広い言語での評価が待たれるところではあります。例えば、仕組み的に機械翻訳 (MT) のエンコーダーとして直接使うというのはできると思いますが、そうした場合、従来のトークン化+マスク言語モデルの場合と比較して計算量や性能がどうなのか、は今後の検証が必要です。
関連記事
 萩原 正人
萩原 正人 萩原 正人
萩原 正人