人工知能・機械学習技術の発展が世間を賑わせて久しいですが、いざ機械学習関係の職に就こう・キャリアチェンジをしようとすると「何から始めてよいか分からない」といった方も多いのではないでしょうか。
Andrew Ng (アンドリュー・エン) 率いる Deeplearning.ai と、機械学習のスキルテストを開発する WORKERA の主催で「機械学習の仕事に就く — 技術採用担当者が語る秘訣」(Landing an ML Job- secrets from technical recruiters) と題されたバーチャルセミナー・パネルディスカッションが行われました。米国(主にシリコンバレー)を代表するスタートアップの採用担当者から、機械学習の仕事に興味のある方向けに、アドバイスや秘訣などを直接聞ける非常に良い機会ですので、下で抄訳と共に紹介します。
また、主にスタートアップ等で機械学習人材の採用にこれまで関わってきた身として、私自身の面接への考え、アドバイス等も書きました。参考になれば幸いです。
「AI+X」型の人材を目指せ — Workera CEO の基調講演
まずはじめに、Workera の CEO・創業者 である Kian Katanforoosh 氏の基調講演がありました。
AI の分野は、過去4年間にわたって求人が最も速く増えている分野です。
一方で、ソフトウェア・エンジニアリングの分野と比べて、キャリアパスがまだ成熟していないという特徴があります。機械学習エンジニア、機械学習サイエンティスト、リサーチ・サイエンティスト、リサーチ・エンジニアなど、多くの肩書・職名があり、混沌としているのが現状です。
求職者側は、どうやって適切な求人を発見し、うまく仕事に就くことができるか?
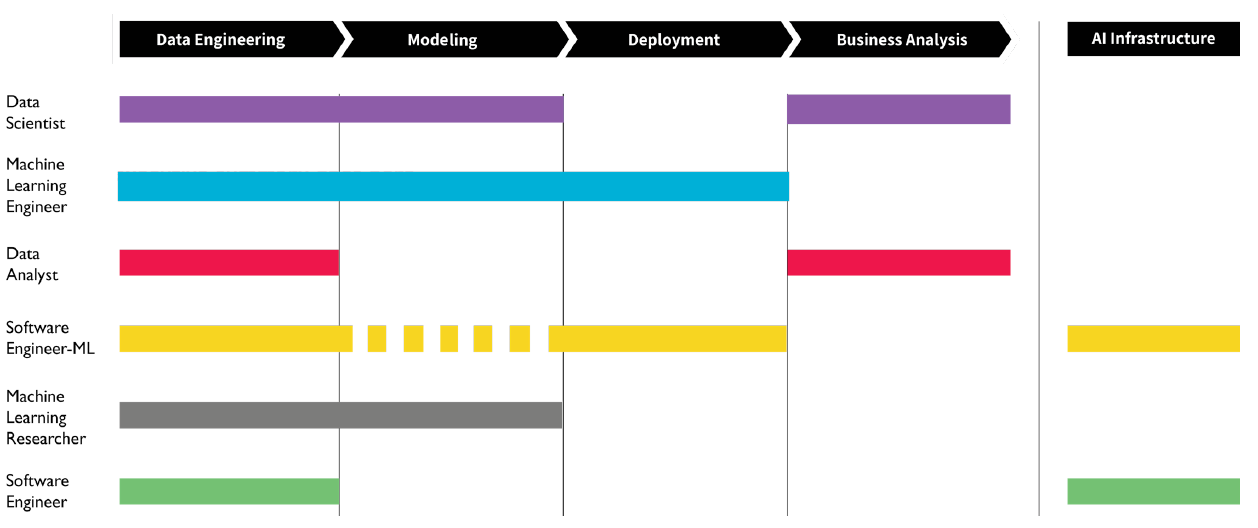
上の図は、機械学習に関する肩書と業務内容との関係を示したものです。この中で、自分がどこに当てはまるのかを考え続けると良いでしょう。詳細は、Workera の AI Career Pathways レポートから読めます。
AI に転向するのではなく、「AI+自分の詳しい分野」を目指すのがオススメです。スタンフォードの深層学習のコースでは、60% 以上の学生がコンピューター・サイエンス出身ではありませんでしたが、同等の成果を上げていました。AI のプロジェクトのライフサイクルに詳しくなるのと同時に、音声処理、遺伝子学、自動運転などの応用分野に詳しくなる「T型人材」を目指すと、「私は、○○を得意とするデータサイエンティストです」「○○を専門とする機械学習エンジニアです」と履歴書で主張できます。
続いて、以下のパネリストのみなさんを招いてお話を聞いてみましょう。
- Ebitie Amughan 氏, Pinterest 技術採用担当
- Lawrence Gomez 氏, Upstart 技術採用担当
- Dana Schafer 氏, Grammarly 技術採用担当
- Melisa Tokmak 氏, Scale AI ドキュメント・プロダクト代表
採用担当者は、履歴書を7秒間しか見ない
AI の求人は、過去四年間、年率 74% で増えているというトレンドが続いています。また、オンライン学習などの普及で、AI の人材も増えています。
質問: 面接する際に、候補者のスキルが、企業側が求めるものとマッチしていますか?
Amughan 氏 (Pinterest): 職によります。求人広告を見て、箇条書きで書かれている「必須スキル」の最初の2〜3個が通常最も重要なものです。履歴書は、全体の一部でしかありません。キャリア・チェンジをしようとする際には、その旨をカバーレター等に書くか、関連するリンクを含めるようにすると良いでしょう。
Tokmak 氏 (Scale AI): 求める職に対して、一番良く当てはまる候補者を探すように意識しています。研究が得意な方もいれば、モノづくり(開発)が得意な方もいます。このような情報を履歴書等から素早く読み取ることが重要です。研究であれば、どのようなプロジェクト・論文に関わったのか?趣味のプロジェクトであれば、どういう経験を積んだのか?という点に注目します。
Schafer 氏 (Grammarly): 採用担当者は、一週間に数百という応募を見ているので、なるべく明確に書くようにすると、面接につながる可能性が増えます。
Katanforoosh 氏 (Workera): ある研究によれば、採用担当者は履歴書を平均で7秒間しか見ないというデータがあります。7秒間で何を見ますか?
Shafer 氏 (Grammarly): 先ほど Amughan 氏の言ったような「最も重要な必須スキル」を見ます。
大企業か、スタートアップか
質問: 「AI人材」として、GAFA のような大企業に就職するか、スタートアップに就職するかという点についてはどう思われますか?
Gomez 氏 (Upstart): 一つの要素は、影響力です。小さなチーム・会社では、自分の仕事が会社・プロダクトに及ぼす影響が大きくなります。もう一つは、技術的なチャレンジです。スタートアップでは業界で他の誰もがやっていないことに取り組むことが多いです。Upstart のデータサイエンティスト、機械学習エンジニアは、機械学習モデルができたら他のチームに引き渡すのではなく、プロダクトの最初から最後まで関わります。最後に、成長です。成長しているスタートアップに参画すると、経営層との距離も近く、個人としての成長も早くなります。
Google や Apple などの大企業では、様々な事業を手がけているので、様々なチーム、選択肢があるというメリットがあります。一方、何万人も居る社員の一人なので、個人としての成長は遅くなります。
Schafer 氏 (Grammarly): 大企業では、独自のインフラ等が整備されているので、それが次の職に移る際に足かせとなる可能性があります。オープンソースのコミュニティなど、業界の進歩に常にアンテナを張っておく必要があります。
Tokmak 氏 (Scale AI): 機械学習が事業の「コア」となっているような会社に居ると、興味深いプロジェクトに関わったり多くの機会に恵まれたりします。自分が事業に直接関わる立場に居ると、創造性が必要になり、成長の機会も得られるでしょう。
Katanforoosh 氏 (Workera): 大企業の場合、配属されるチームによってかなり経験が変わってきますね。
面接ですべきこと、すべきでないこと
質問: 面接プロセスにあたって、応募者がすべきこと、するべきではないこと等はありますか?
Amughan 氏 (Pinterest): 準備は大事です。採用担当として、面接のプロセスを詳細に説明するようにしていますので、それに応じて応募者も事前に心構えができます。面接は筋肉のようなものなので、久しぶりの場合は、コーディング面接を時間内に答えられるように練習しておくと良いです。他には、自分の過去の査定、フィードバックを見直し、会社やプロダクトへの貢献を話せるようにしておくことです。あと、良い質問をするようにしましょう。技術的な決定はどのようになされるのか、エンジニアリング文化はどうかなど。
するべきではないのは、知ったかぶりをすること。問題が分からない時は、「詳しい分野ではありませんが、私ならこうします」と素直に言いましょう。
Gomez 氏 (Upstart): AI は広い分野なので「好奇心」は大切です。今はわからなくても、学習する意欲があるかどうか、プロダクトは好きかどうか、個人的な趣味で何かをやっているか、という点を見ます。
Schafer 氏 (Grammarly): その会社のエンジニアと研究者の違い、に注意すべきです。どのようなプロジェクトがあり、どう評価されるのか、というのをリクルーターや面接官に聞くと良いです。
Amughan 氏 (Pinterest): 面接官からのフィードバックを聞いて取り入れられるか、は見られる点です。
機械学習に学位は必要か
質問: 機械学習系の仕事に応募する際に、博士号 (Ph.D.) は必要でしょうか?
Schafer 氏 (Grammarly): 博士号は、職によっては必須条件です。博士の良い点は、何年もの時間をかけて、ある分野の「真の専門家」になれる点です。また、クリティカル・シンキング、勤勉さ、アカデミックとの協業など、貴重なスキルを身につけることもできます。もちろん、博士号がなくても、このようなスキルを他の方法でどのように身につけたのか説得できればこの限りではありません。
Amughan 氏 (Pinterest): 博士号はいつも必要とは限りません。博士号を持たない人が、仕事で素晴らしい成果を上げている例を知っています。社内で、機械学習の経験を持たない社員への教育の機会も提供しています。
質問: 学士号・修士号を持たない場合はどうでしょうか?
Tokmak 氏 (Scale AI): 大丈夫です。Scale AI の CEO も MIT を中途退学しています。学士号を持たない場合、その時間で代わりに何をしたか、何を生み出したかを見ます。会社の使命に共感できるか、学んで成長できるか、という点の方がもっと大事です。
Amughan 氏 (Pinterest): トランプ政権によって、H1b の条件が厳格化されました。11月の選挙では、どちら側を支持するかに関わらず、皆さんぜひ投票してください。
機械学習以外に大切なスキル
質問: 技術的なスキル以外に見るスキルはありますか?
Amughan 氏 (Pinterest): 技術コミュニケーションがきちんとできるかを見ます。一つのコツは、「声に出しながらコードを書く」です。解答を書き始める前に、考えを声に出し、質問しながら考えをまとめます。あとは、フィードバックをきちんと聞けるか、会社の方針と方向性が合っているか、などです。リーダーシップのスキル、良いメンターか、という点も大切です。
Schafer 氏 (Grammarly): Grammarly で重視する価値観は「グリット」です。難しい問題にあきらめずに取り組めるか。好奇心、チームワークなども大切です。
Gomez 氏 (Upstart): 声に出してコードを書く場合でも、回りくどいのは良くありません。「真の問題」をきちんと発見し、それに取り組めるかどうか。
Tokmak 氏 (Scale AI): 協業の仕方を見ます。フィードバックを聞き、答えを改善できるか。答えが分からない時でも、面接官も巻き込むつもりで、コミュニケーションすること。
Katanforoosh 氏 (Workera): 補足すると、用語を正しく使うのは大切です。例えば、相関 (correlation) と共分散 (covariance) は、言葉は似ていますが、大きな違いがあります。
エンジニア・サイエンティスト以外のキャリアパス
質問: データサイエンティスト、機械学習エンジニアとして応募する以外のキャリアパスはありますか?
Gomez 氏 (Upstart): 説明可能な AI は、分野として急速に成長しています。金融業界では、AI モデルを、政府の監視官などの利害関係者に説明できる必要があり、そのような人材は、必ずしもコンピューター・サイエンスの学位を持っているとは限りません。
Tokmak 氏 (Scale AI): Scale AI は機械学習の会社なので、セールス職や事業運営職であっても技術を理解できる必要があります。マーケティング、採用担当も同じです。
Amughan 氏 (Pinterest): テクニカル・ライティング、AI倫理、ラベリングなども重要になってきています。
Schafer 氏 (Grammarly): Grammarly には、コーパス (データセット) を作る言語学者等からなる内部チームがあります。
機械学習の経験が無い・浅い場合、どうすれば?
質問: 職務経験が無い場合、自分の AI/ML スキルをどのように示したら良いですか?
Schafer 氏 (Grammarly): ある求職者は、アカデミックから産業界へとキャリアチェンジをしようとしていました。「プロダクションレベルのコードが書けるか」という当然の疑問を見通して、自分の書いた Github のリポジトリへのリンクを前もって共有していました。趣味のプロジェクトを極める、というのも可能です。
Gomez 氏 (Upstart): プロジェクトやコースなどを履歴書に書くのも良いです。流行りの言葉を書くのではなく、「何を成し遂げたか」という点を強調するようにしましょう。
Amughan 氏 (Pinterest): Kaggle などのコンペに言及するのも良いです。業界の人に話を聞く、ブログを読むと、自分のストーリーをどう語るかの参考になります。
質問: どこで候補者を見つけますか?
Tokmak 氏 (Scale AI): 色々なところを見ます。LinkedIn 、コンペ、社内紹介、大学でのリクルーティングです。カンファレンスにも行きます。
質問: 機械学習エンジニア、サイエンティストなど、色々な職種があって分かりにくいのですが、何らかの業界標準はできないのでしょうか?
Schafer 氏 (Grammarly): その職で本当に何が求められているかを知るには、「どのぐらいの割合の時間コードを書いていますか」「一般的なソフトウェア・エンジニアと同じコードの質が要求されますか」「深層学習と伝統的な機械学習のどちらを使いますか」という質問をすると良いでしょう。
Amughan 氏 (Pinterest): 会社のブログや求人ページなどを見てよく研究しましょう。
Gomez 氏 (Upstart): 「数撃ちゃ当たる」的にたくさん応募するのではなく、少数の会社をよく研究し、人脈をつくり、相手に合わせた就職活動をしましょう。
PyTorch と TensorFlow、どちらを学ぶ?
質問: 求人広告に、TensorFlow、PyTorch、Kubernetes、Docker など、数多くのプラットフォーム等が書いてありますが、経験が無い・浅い場合どうすれば良いでしょう?
Amughan 氏 (Pinterest): 求人広告を書く時には、なるべく幅広く含むようにしますので、尻込みする必要はありません。LinkedIn などで社員のバックグラウンドを調べるというのも参考になります。
Katanforoosh 氏 (Workera): これらの必須要件は、「AND」というよりは「OR」に近いですね。
Schafer 氏 (Grammarly): もっと大切なのは、どのぐらい速く学習してキャッチアップできるか、という点です。
質問: 一言でアドバイスをお願いします。
Amughan 氏 (Pinterest): 就職活動にはストレスがつきものです。根気強く続けましょう。
Schafer 氏 (Grammarly): 採用担当者、リクルーターと協力し、自分の強み、これから伸ばす点に目を向けましょう。
Gomez 氏 (Upstart): 不採用通知はつきものです。それだけであきらめないように。特にキャリアチェンジをする際は。
Tokmak 氏 (Scale AI): 機械学習は売り手市場です。自分に合った職が見つかるまで続けましょう。
ちなみに、パネリストの皆さんの企業では、機械学習人材を募集しています。興味のある方は、以下のページをチェックしてみることをオススメします。
機械学習エンジニアを採用する際に私が見る点
私も、これまで主に日米両国のスタートアップにおいて、数多くの機械学習エンジニア、研究者、データサイエンティストの採用活動に関わったことがあります。また、応募者として、採用プロセスを経験したことも何度もありました。その際に、特に採用側の人間として注目する点についていくつか書いてみます。
Kaggle より、自分の興味のあるタスクを解く
注: こちらの段落ですが、私のコンペティション等への理解不足等により、正確ではない、誤解を与えるような内容になってしまっている点、お詫び申し上げます。個人的にはコンペティション等には何度も参加、さらには、開催したこともありますが、理解が不十分なままこのような断定的な内容を書いたことは不適切であったと考えております。以下の段落については、そのまま残しておきます。近いうちに、コンペティションの実践 ML についても記事を書きたいと考えております。
いきなり物議を醸し出しそうなことを書きますが、Kaggle などに代表される機械学習コンペティションは、「実世界のビジネスに役立つ機械学習スキルを練習する場」としてはほとんど役に立たない、というのが私の考えです。Kaggle などのコンペティションでは、タスク、学習用・評価用データ、評価指標などがあらかじめ決められて与えた上で、その問題を最もうまく解決できるモデルを作るのを競います。ここでは、「なるべく性能の高いモデルを作ること」にほぼ全ての労力が注がれます。
一方、現実世界の機械学習業務を見てみると、必要となるスキルはこのまったく逆であることが分かります。機械学習に関わると、ビジネス上のインパクトとコストの両方を天秤にかけながら、多くの関係者と協業しながら、以下のような数々の難しい決定を下していく必要があります:
- 解くべきタスクは何か。そもそも機械学習で解ける・解くべき問題なのか。
- 教師あり学習、教師なし学習、強化学習、どれを使うべきか。
- 訓練と評価用のデータはどのように用意するか。
- 社内でデータを作る場合、アノテーションは誰に頼み、どのようなガイドラインに従うのか。
- これは回帰問題か分類問題か。それとも生成問題か。
- 深層学習もしくは伝統的機械学習のどちらを使うべきか。
- どのようなアーキテクチャで、どのフレームワークを使って実装するのか。
- ゼロから学習するか、訓練済みモデルをそのまま使うか、fine-tune するか。
- モデルをどう評価し、ローンチの判断はどうするのか。
- デプロイにはどのようなプラットフォームを使うのか。
- システムがきちんと動いてビジネス価値を生み出しているかどうかをどう評価・モニタリングするのか。
- モデルの再学習・更新の業務プロセスをどうするか。
などなどです。Kaggle などの標準化されたコンペティションでは、これらがあらかじめ決められている(もしくは考えなくて良い)ので、自分で考える力が身につきません。また、コンペティションなどで重要になる1〜2%の性能の差は、ユーザー体験から見たら誤差でしかないかもしれません(もちろん、医療診断など、1〜2%の性能の差が死活問題になる分野もあります)。
個人的には、Kaggle などのコンペティションよりも、「自分が個人的に持っている問題を、機械学習でどう解決するか」という趣味のプロジェクトを始めてみる、というのをオススメします。
「MNIST の手書き文字を、CNN を使って分類しました」というありふれた問題よりも、「Raspberry Pi とカメラを使って、飼い犬がうんちをしてないかどうか監視するシステムを作りました」という方が100倍面白く、実際の業務に近いのです。
「映画レビューのデータセットから感情分析モデルを学習しました」というありふれた問題よりも、「小説のキャラクターのセリフから話している人を当てるシステム」をどう作るか、というのを考える、実装する練習を積む方が、業務上よっぽど役に立ちます。
なお、ここで出した最初2つの例、後の2つの例は、モデル的には同じ(画像分類とテキスト分類)という点に注目してください。「モデリング」は、機械学習において最も重要な点ではないのです。
補足しておくと、Kaggle などのコンペティションは、「全くの初心者で、何から始めて良いか分からない」「上級者で、自分のアプローチ・モデルの性能を極限まで追求したい」といった場合には非常に役に立ちます。フォーラムなどで他の人がどのように考え、どのように実装しているかを見ることができるのも参考になるでしょう。
面接だけで機械学習スキルを測るのは不可能
面接だけで候補者の機械学習スキルを正確に測るのは不可能である、というのが私の考えです。
ソフトウェア・エンジニアの採用についても、コーディング面接の是非が活発に議論されていて、このトピックについて話し出すとまた記事や本が書けてしまうのですが、「技術面接は一つの近似でしかない」というのは、皆が同意するところかと思います。限られた時間内で、検索もせずに、ホワイトボード上もしくは口頭で問題を解く、という設定が、日常の業務で必要とされているスキルからかけ離れているからです。
コーディング面接よりも候補者のスキルを正確に測れる方法にはいくつかあります。一つは、候補者に「持ち帰り課題」を与え、1週間ほどで家で解いてもらうこと。この場合の課題は、検索したら答えが分かるような簡単なものではありません。例えば「こういうデータセットが与えられた場合、あなたならどう分析して、どのようなモデルを作りますか」という大まかな問題に対して、レポートとコードを提出してもらいます。分析、設計、コーディングのスキルが正確に測れるというメリットがあります。
もっと良いのは、お試しとして数週間、簡単なプロジェクトを与えて一緒に働いてみる、という方法です。私がコンサルタントとして関わっている Lang-8 でも採用しており、入社する前にスキル、コミュニケーション能力、カルチャーマッチングなどが測れます。もちろん有給ですし、候補者の側からも、自分の希望と会社の実情がマッチしているかどうかというのをあらかじめ確認でき、非常に良い制度だと思います。
なお、上の2つの方法とも、「適切な課題を設計する」「適切なお試しプロジェクトを設計する」という、採用よりも高度な問題について考えなければなりません。「候補者のスキルを判断できるスキルを持った人が社内に居ない」という鶏と卵の問題に直面することがあります。この場合、外部の専門家に頼んで、課題を設計してもらう、面接に同席してもらうという方法もあります(私も、このような方法で、クライアントさんの採用をお手伝いしてきました)。
最後に、「技術面接は一つの近似でしかない」という点から、面接にはかならず偽陰性(スキルが足りているのに不採用になる)がつきものである、という系が導かれます。優良企業であるほど採用に慎重になるのが普通で、偽陽性(スキル不足の人を誤って雇ってしまう)リスクを嫌がります。面接に落ちた、選考が進まなかったからといって、過度に落ち込むことのないようにしましょう。
「名前を知っている」ことと「本質が分かっている」ことは違う
近年の機械学習分野の発展は目覚ましく、まさに日進月歩で新しいアルゴリズムやモデルが発表されています。面接をしていると、このような流行りのモデルの知識が非常に豊富な候補者が多くいます。
しかし、もっと突っ込んだ質問をしてみると、実はよく分かっていなかった、ということがしばしばあります。例えば、なぜそのモデルがそのタスクに適切なのか、どのように訓練データを前処理するのか、計算量と性能のトレードオフはどうか、損失関数をどう設計するか、正則化のテクニックは何を使うか、などです。このような問題は、メディアを賑わす「花形」のモデルに比べると地味なトピックですが、機械学習を使って成果を出すためにはいずれも非常に大切な要素です。
候補者としては、流行り物のモデルやアルゴリズムを追うよりも、基礎となる技術を論文を読むなどしてきちんと理解しておくことの方が大切です。自然言語処理の分野で言えば、数ある BERT の異種を追いかけるよりも、RNN とトランスフォーマーがどう動くか、どのように実装するか、などを理解する。画像認識で言えば、数ある GAN の異種を追いかけるよりも、基礎となるネットワーク (U-Net や ResNet) や、初代 GAN の論理的な背景などをきちんと把握する。どの分野を目指すにしても、線形代数、確率統計、微分積分、損失関数、最適化、正則化などの基礎は (例えば Goodfellow 氏の Deep Learning の本を読むなどして) おさえておきましょう。
モデリングだけが機械学習ではない
上でも述べましたが、モデリングは、機械学習業務のほんの一部でしかありません。実際の機械学習業務では、システムや業務フロー全体をデザインするといった、モデリング以外の要素が大半です。
このような中で成果を出せるかどうかを見極めるために、面接では、機械学習システムデザインに関する問題を出します。なお、これは他の大手テック企業やスタートアップでも広く採用されている面接形式で、私が関わった機械学習系のポジションでは、コーディング面接に加え、だいたいこの形式の面接が行われることが普通です。
具体的には、「このようなサービスにこのような機能を機械学習を使って実装するとして、どのように取り組むか」という抽象度の高い問題を出します。これには、決まった正解は無いため、候補者が問題を分解して考えられることができるか、ビジネスの問題を機械学習の問題にうまく落とし込めるかどうか、言語・フレームワーク・デプロイ方法・プロダクトの他のサービスとのやり取りなども含め、アーキテクチャ全体を考えられるか、といった点を見ます。もちろん、機械学習モデルに何を使うか、といった点も議論しますが、これは全体のうちほんの一部でしかありません。
機械学習システムデザインを含め、機械学習関係の職に応募することに興味のある方は、Facebook London に入社することになりました を読んでいただけると、雰囲気がかなり分かるかと思います。また、この記事内でも紹介されていますが、Chip Huyen 氏の Machine Learning Systems Design は、機械学習に関する良いアドバイスが詰まっているので、採用に直接関わるのでなくても、一読されることをオススメします。
なお、機械学習の面接について話し始めると一冊の本が書けてしまいます。もっと興味のある方はこちら まで直接ご連絡・ご質問いただければ、もっと突っ込んだ話しができると思います。
関連記事
 萩原 正人
萩原 正人